文章内容如有错误或排版问题,请提交反馈,非常感谢!
Zeppelin简介
Apache Zeppelin是一个开源的Notebook工具,旨在为数据科学家、数据工程师和分析师提供一个交互式的环境,用于数据探索、可视化和协作分析。它支持多种后端数据处理引擎,使用户能够在一个统一的界面中执行复杂的数据分析任务。
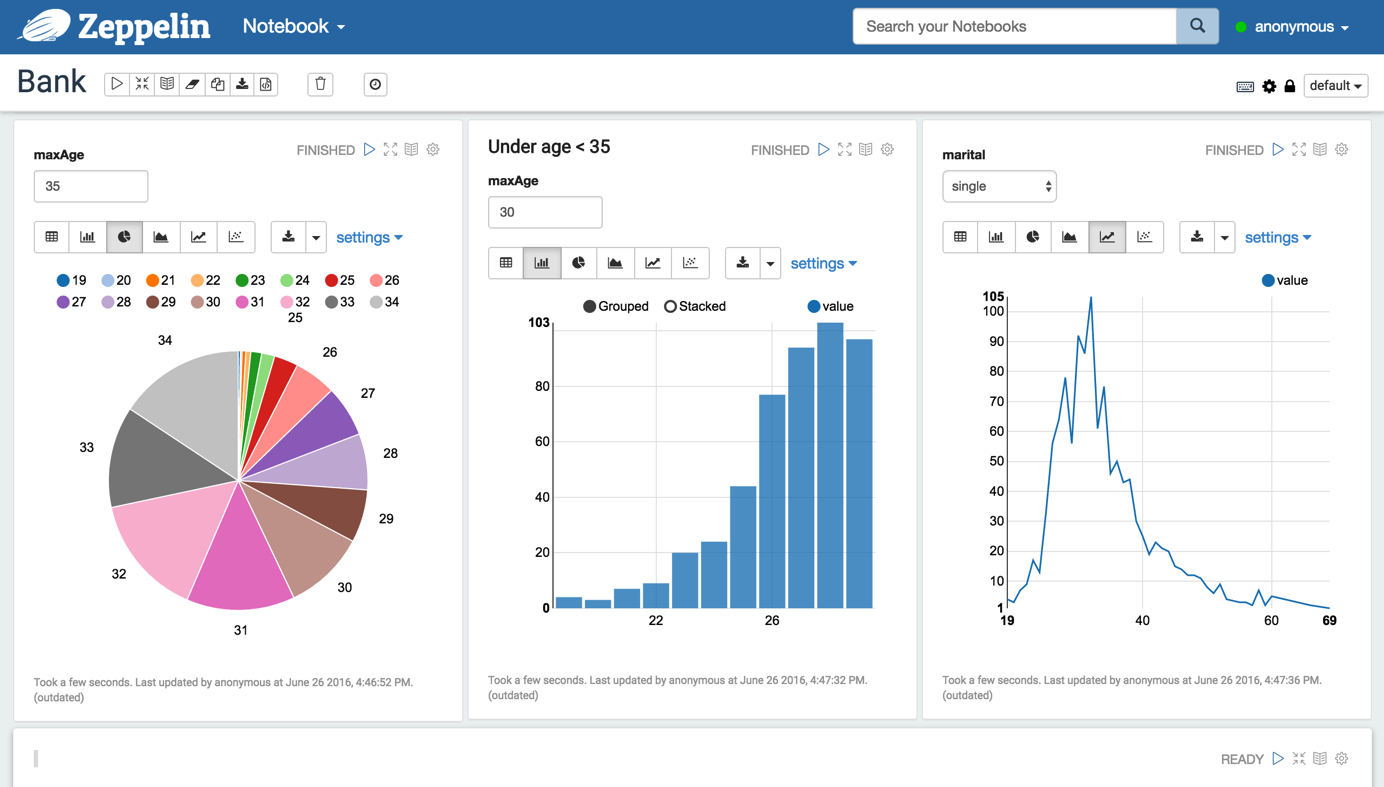
核心功能
- 多语言支持:Zeppelin支持多种编程语言和数据处理引擎,包括Apache Spark、Python(通过IPython)、R、SQL、Scala、Markdown等,用户可以在同一个笔记本中使用多种语言。
- 交互式数据可视化:提供丰富的可视化选项,包括柱状图、饼图、线图、地图等,用户可以通过简单的命令将数据转换为可视化图表,并支持自定义图表样式。
- 实时协作:支持多个用户实时协作编辑同一个笔记本,使团队成员能够共同探索和分析数据。
- 动态表单:允许用户创建动态表单组件(如下拉列表、文本框、滑块等),以便在笔记本中与参数化查询和分析进行交互。
- 可扩展的插件架构:通过插件机制支持更多的数据处理引擎和可视化工具,用户可以根据需求扩展Zeppelin的功能。
- 集成与扩展:支持与多种大数据生态系统工具的集成,如Hadoop、HBase、Elasticsearch、Kylin等,方便在不同数据源之间进行分析。
典型使用场景
- 数据探索与分析:数据科学家和分析师可以使用Zeppelin进行数据探索、清洗和初步分析,快速获取数据洞察。
- 数据可视化与报告:通过可视化工具,用户可以将分析结果转换为易于理解的图表和报告,适合用于展示和分享分析结果。
- 机器学习与实验:支持使用Spark MLlib、scikit-learn等库进行机器学习实验和模型训练,便于对模型进行迭代和优化。
- 教育与培训:作为一个交互式教学工具,Zeppelin可以用于数据科学和大数据课程的教学和演示。
与Jupyter的区别
Apache Zeppelin和Jupyter Notebook是两种流行的开源笔记本工具,广泛用于数据科学、数据分析和机器学习等领域。虽然它们在许多方面具有相似性,但也存在一些关键的区别。以下是两者的详细比较:
共同点
- 交互式笔记本: 两者都提供基于Web的交互式笔记本环境,允许用户编写代码、执行计算、可视化数据并记录分析过程。
- 多语言支持: 两者都支持多种编程语言,尽管它们的实现方式有所不同。
- 可视化: 提供多种数据可视化功能,支持将数据分析结果转换为图表和图形。
- 开源: 都是开源项目,拥有活跃的社区支持和丰富的扩展生态系统。
主要区别
- 语言支持与解释器架构:
- Jupyter: 使用内核(Kernels)来支持多种编程语言。每种语言都有相应的内核,最常用的是IPython内核用于Python。用户可以通过安装不同的内核来支持多种语言(如R、Julia、Scala等)。
- Zeppelin: 使用解释器(Interpreters)来支持多种语言和数据处理引擎。提供内置的多语言支持,包括Spark、Python、SQL、Scala等,并且可以在同一个笔记本中混合使用多种语言。
- 数据处理引擎集成:
- Jupyter: 主要通过Python库(如pandas、numpy、matplotlib)进行数据处理和可视化。通过插件和扩展可以支持分布式计算引擎,如Apache Spark(需要额外配置)。
- Zeppelin: 天生支持与大数据处理引擎(如Apache Spark、Flink)的集成,适合大规模数据分析。直接内置了对多种大数据工具的支持,用户可以轻松配置和使用。
- 协作与共享:
- Jupyter: 支持通过nbviewer、JupyterHub等工具进行笔记本的共享和协作。需要额外设置和工具来支持多用户协作和访问控制。
- Zeppelin: 提供内置的多用户协作功能,用户可以实时协作编辑同一个笔记本。更加注重企业级应用中的多用户和权限管理。
- 可视化与用户界面:
- Jupyter: 提供丰富的可视化库(如matplotlib、seaborn、plotly)支持,用户可以使用Python库进行高度自定义的可视化。
- Zeppelin: 提供内置的可视化选项,支持通过简单命令生成多种图表,并且支持动态表单和交互式控件。
- 使用场景:
- Jupyter: 广泛用于数据科学、机器学习、教育和科研。适合需要灵活编程和自定义可视化的用户。
- Zeppelin: 更加侧重于大数据分析和企业级应用,适合需要与大数据工具集成的场景。
总结
- Jupyter: 如果你的工作主要围绕Python生态系统,并且需要高度自定义的分析和可视化,那么Jupyter是一个理想的选择。它的灵活性和广泛的社区支持使其成为数据科学和机器学习的标准工具。
- Zeppelin: 如果你的工作涉及大规模数据处理,需要与Apache Spark等大数据工具紧密集成,并且需要在团队中进行实时协作,那么Zeppelin是一个更合适的选择。其企业级功能和多语言支持使其在大数据分析场景中具有优势。
总体而言,选择哪种工具取决于具体的使用场景、团队需求和技术栈偏好。两者都有各自的优势和适用领域,用户可以根据自己的需求选择合适的工具。
Zeppelin的架构
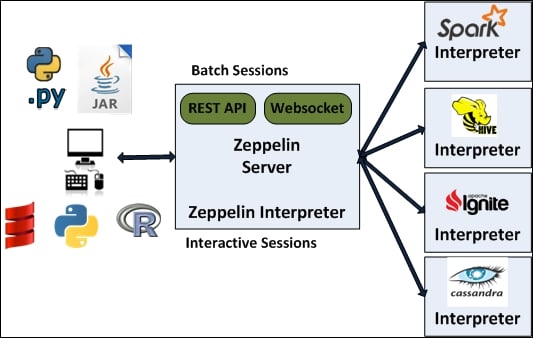
Apache Zeppelin的架构设计旨在为用户提供一个灵活且强大的交互式数据分析环境。其架构由多个模块组成,这些模块协同工作,以实现数据处理、可视化和协作等功能。
架构组件
Zeppelin的架构主要包括以下几个关键组件:
Zeppelin Server
- 功能: 作为中心服务,负责管理笔记本的执行、解释器的调度、会话管理和与用户的交互。
- 会话管理: 处理用户的会话请求,确保每个用户的笔记本环境独立运行。
- 调度与执行: 将用户在笔记本中编写的代码发送到相应的解释器执行,并返回结果。
Web UI
- 功能: 提供基于Web的用户界面,用户可以通过浏览器访问和使用Zeppelin。
- 笔记本管理: 允许用户创建、编辑和组织笔记本,并支持可视化配置。
- 实时协作: 支持多个用户同时编辑同一个笔记本,实现实时协作。
解释器(Interpreters)
- 功能: 解释器是Zeppelin用于执行不同编程语言和数据处理引擎的模块。
- 多语言支持: 每个解释器对应一种语言或引擎,如Spark、Python、R、SQL等。
- 可扩展性: 用户可以根据需要添加和配置新的解释器,以支持更多的工具和语言。
存储系统
- 功能: 存储笔记本内容、配置和用户数据。
- 持久化: 支持将笔记本内容持久化存储到文件系统、数据库或云存储。
- 版本管理: 一些配置允许对笔记本进行版本控制,方便用户追溯和恢复历史版本。
安全与权限管理
- 功能: 提供用户身份认证和权限控制,确保数据和笔记本的安全性。
集成:支持与LDAP、Active Directory等企业级认证系统集成。
工作流程
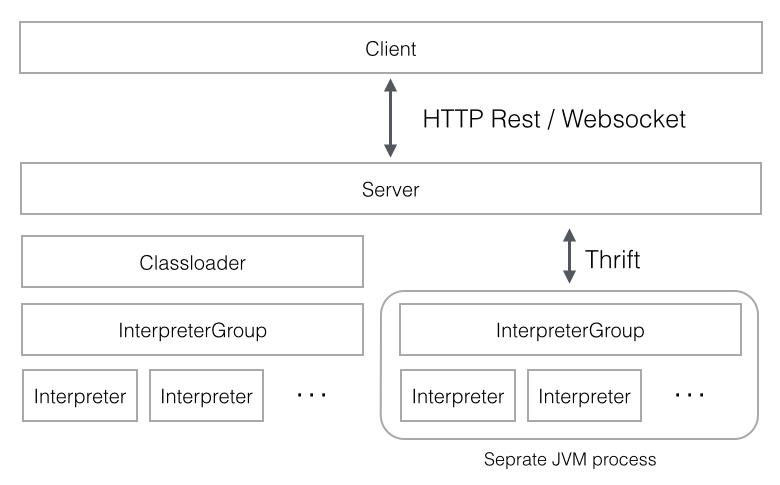
- 用户登录:用户通过浏览器访问Zeppelin的Web UI,进行身份认证和登录。
- 笔记本创建与编辑:用户创建或打开一个笔记本,在其中编写代码和文档。
- 代码执行:用户的代码被发送到相应的解释器,由解释器进行解析和执行。
- 结果返回与可视化:执行结果通过Web UI返回给用户,并以文本或图表形式呈现。
- 协作与共享:用户可以与团队成员共享笔记本,进行实时协作和讨论。
特性支持
- 实时数据处理:通过与Spark、Flink等大数据引擎的集成,支持实时和批量数据处理。
- 灵活的可视化:内置多种可视化选项,支持通过简单命令生成交互式图表。
- 动态表单:允许用户创建动态控件(如下拉列表、滑块),以便与参数化查询进行交互。
参考链接:


