Apache Avro简介
Apache Avro是一种数据序列化系统,广泛用于数据的高效存储与传输,尤其是在大数据处理和分布式系统中。它最初由Hadoop项目开发,旨在解决数据序列化时的兼容性、效率和可移植性问题。
Avro(读音类似于[ævrə])是Hadoop的一个子项目,由Hadoop的创始人Doug Cutting(也是Lucene,Nutch等项目的创始人)牵头开发。Avro是一个基于二进制数据传输高性能的中间件。在Hadoop的其他项目中例如HBase (Ref)和Hive (Ref)的Client端与服务端的数据传输也采用了这个工具。Avro是一个数据序列化的系统。Avro可以将数据结构或对象转化成便于存储或传输的格式。Avro设计之初就用来支持数据密集型应用,适合于远程或本地大规模数据的存储和交换。

当前市场上有很多类似的序列化系统,如Google的Protocol Buffers, Facebook的Thrift。Avro提供着与诸如Thrift和Protocol Buffers等系统相似的功能,但是在一些基础方面还是有区别的,主要是:
- 动态类型:Avro并不需要生成代码,模式和数据存放在一起,而模式使得整个数据的处理过程并不生成代码、静态数据类型等等。这方便了数据处理系统和语言的构造。
- 未标记的数据:由于读取数据的时候模式是已知的,那么需要和数据一起编码的类型信息就很少了,这样序列化的规模也就小了。
- 不需要用户指定字段号:即使模式改变,处理数据时新旧模式都是已知的,所以通过使用字段名称可以解决差异问题。
核心特点
- 紧凑性和高效性:
- Avro使用二进制格式存储数据,避免了JSON或XML的冗余字符,具有更高的存储和传输效率。
- 模式驱动:
- 数据与其模式(Schema)分离存储,解码时通过模式解析数据。
- 支持跨语言(Java、Python、C++等)使用,方便在分布式环境中共享数据。
- 动态模式解析:
- 在读取数据时可以指定一个模式(Reader Schema),通过模式解析实现数据前后兼容性。
- 面向行存储:
- 每条记录单独序列化,适合流式处理和小文件存储。
- 跨语言支持:
- 支持多种编程语言,方便在不同的技术栈中使用。
Avro的优点
- 高效的序列化:由于数据格式紧凑,Avro在数据的读写速度和存储效率方面表现出色。
- 动态模式解析:支持数据的前向和后向兼容(Forward & Backward Compatibility),方便在数据结构更新时保持应用的兼容性。
- 与Hadoop的无缝集成:Avro是Hadoop的原生支持序列化格式,广泛应用于MapReduce、Hive、Spark等大数据处理框架。
- 丰富的数据类型:支持复杂和嵌套数据结构,适合处理复杂的数据模型。
Avro的使用场景
- 数据存储:用于存储大数据平台中的结构化数据,如HDFS、Kafka。
- 数据交换:在分布式系统中作为数据的传输格式,减少带宽占用。
- 流式处理:适合在实时流数据处理(如Kafka Streams、Flink)中使用。
- 远程调用:使用Avro RPC实现高效的分布式服务通信。
与其他序列化格式的比较
Apache Avro、Protocol Buffers(Protobuf)、Thrift、JSON和XML是几种常见的数据序列化格式和协议,它们各有优缺点,适合不同的应用场景。以下是对它们的一些关键特性的比较:
| 特性 | Avro | Protobuf | Thrift | JSON | XML |
| 数据格式 | 二进制格式 | 二进制格式 | 二进制和文本格式 | 文本格式 | 文本格式 |
| 模式支持 | 必须使用模式,支持模式演化 | 必须使用模式,支持模式演化 | 使用IDL定义模式,支持模式演化 | 无需模式(可选JSON Schema) | 无需模式(可选DTD或XSD) |
| 性能 | 高效的序列化和反序列化 | 高性能序列化和反序列化 | 高效,适合分布式系统的RPC | 较慢的解析速度,适合人类可读性要求高 | 解析速度慢,适合复杂数据结构 |
| 跨语言支持 | 广泛的语言支持 | 多种语言支持 | 多种语言支持,特别适合跨语言RPC | 原生支持多种语言,无需额外库 | 原生支持多种语言,无需额外库 |
| 应用场景 | 大数据处理(Hadoop、Kafka),数据交换 | 网络通信、数据存储,高效序列化场景 | 分布式系统服务通信,跨语言RPC | Web API数据交换,配置文件 | 配置文件、文档存储,复杂数据结构 |
| 人类可读性 | 否 | 否 | 部分(文本格式) | 是 | 是 |
| 自描述性 | 否(依赖外部模式) | 否(依赖外部模式) | 否(依赖IDL) | 部分(通过键值对) | 是(标签描述) |
| 扩展性 | 通过模式演化实现 | 通过模式演化实现 | 通过IDL实现 | 通过灵活的数据结构实现 | 通过DTD/XSD实现 |
选择哪种数据格式和协议取决于具体的需求和场景:
- 如果需要高效的数据序列化和反序列化,且可以接受二进制格式,Protobuf和Avro是不错的选择。
- 如果需要跨语言的服务调用和数据交换,Thrift提供了很好的支持。
- 如果需要人类可读性和易于调试,JSON是最常用的选择。
- 如果需要复杂的数据结构和强自描述性,XML可能更合适。
Apache Avro的工作原理
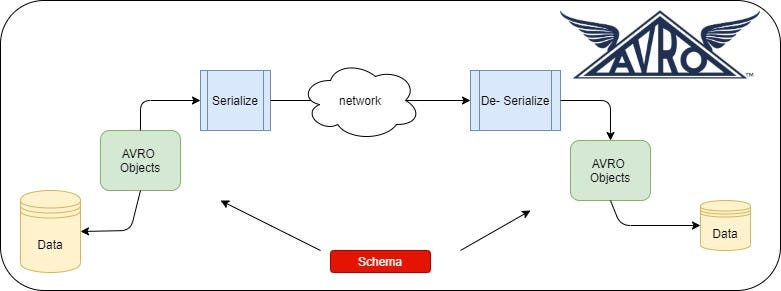
- 写入数据:提供模式和数据,Avro将数据序列化为二进制格式。
- 读取数据:提供数据文件和(可选的)模式,Avro解码数据并返回可用的对象。
- 数据兼容性:当模式发生变化时(如新增字段),只需提供新的ReaderSchema即可正确解析旧数据。
Avro的核心组件
Schema(模式):使用JSON定义数据结构,包括字段名称、类型等。支持复杂数据类型(如记录、数组、映射)和嵌套结构。示例:
{
"type":"record",
"name":"User",
"fields":[
{"name":"name","type":"string"},
{"name":"age","type":"int"},
{"name":"email","type":["null","string"],"default":null}
]
}
数据文件:包含Avro编码的二进制数据和元数据。元数据通常包括模式和压缩信息。
RPC(远程过程调用):支持分布式系统中的高效数据交换。使用Avro定义的协议,轻量且高效。
Avro的具体实现
Avro依赖模式(Schema)来实现数据结构定义。可以把模式理解为Java的类,它定义每个实例的结构,可以包含哪些属性。可以根据类来产生任意多个实例对象。对实例序列化操作时必须需要知道它的基本结构,也就需要参考类的信息。这里,根据模式产生的Avro对象类似于类的实例对象。每次序列化/反序列化时都需要知道模式的具体结构。所以,在Avro可用的一些场景下,如文件存储或是网络通信,都需要模式与数据同时存在。Avro数据以模式来读和写(文件或是网络),并且写入的数据都不需要加入其它标识,这样序列化时速度快且结果内容少。由于程序可以直接根据模式来处理数据,所以Avro更适合于脚本语言的发挥。
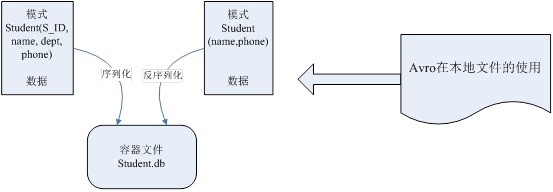
Avro的模式主要由JSON对象来表示,它可能会有一些特定的属性,用来描述某种类型(Type)的不同形式。Avro支持八种基本类型(PrimitiveType)和六种混合类型(ComplexType)。基本类型可以由JSON字符串来表示。每种不同的混合类型有不同的属性(Attribute)来定义,有些属性是必须的,有些是可选的,如果需要的话,可以用JSON数组来存放多个JSON对象定义。在这几种Avro定义的类型的支持下,可以由用户来创造出丰富的数据结构来,支持用户纷繁复杂的数据。
Avro支持两种序列化编码方式:二进制编码和JSON编码。使用二进制编码会高效序列化,并且序列化后得到的结果会比较小;而JSON一般用于调试系统或是基于WEB的应用。对Avro数据序列化/反序列化时都需要对模式以深度优先(Depth-First),从左到右(Left-to-Right)的遍历顺序来执行。基本类型的序列化容易解决,混合类型的序列化会有很多不同规则。对于基本类型和混合类型的二进制编码在文档中规定,按照模式的解析顺序依次排列字节。对于JSON编码,联合类型(UnionType)就与其它混合类型表现不一致。
Avro为了便于MapReduce的处理定义了一种容器文件格式(ContainerFileFormat)。这样的文件中只能有一种模式,所有需要存入这个文件的对象都需要按照这种模式以二进制编码的形式写入。对象在文件中以块(Block)来组织,并且这些对象都是可以被压缩的。块和块之间会存在同步标记符(SynchronizationMarker),以便MapReduce方便地切割文件用于处理。下图是根据文档描述画出的文件结构图:
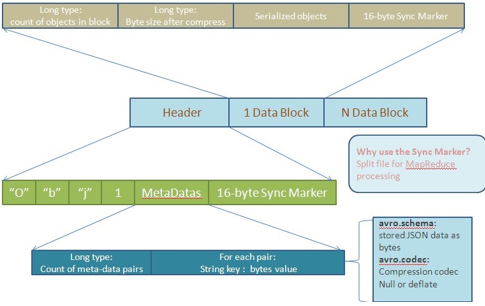
一个存储文件由两部分组成:头信息(Header)和数据块(DataBlock)。而头信息又由三部分构成:四个字节的前缀(类似于MagicNumber),文件Meta-data信息和随机生成的16字节同步标记符。文档中指出当前Avro认定的就两个Meta-data:schema和codec。codec表示对后面的文件数据块(FileDataBlock)采用何种压缩方式。Avro的实现都需要支持下面两种压缩方式:null(不压缩)和deflate(使用Deflate算法压缩数据块)。除了文档中认定的两种Meta-data,用户还可以自定义适用于自己的Meta-data。这里用long型来表示有多少个Meta-data数据对,也是让用户在实际应用中可以定义足够的Meta-data信息。对于每对Meta-data信息,都有一个string型的key(需要以“avro.”为前缀)和二进制编码后的value。对于文件中头信息之后的每个数据块,有这样的结构:一个long值记录当前块有多少个对象,一个long值用于记录当前块经过压缩后的字节数,真正的序列化对象和16字节长度的同步标记符。由于对象可以组织成不同的块,使用时就可以不经过反序列化而对某个数据块进行操作。还可以由数据块数,对象数和同步标记符来定位损坏的块以确保数据完整性。
上面是将Avro对象序列化到文件的操作。与之相应的,Avro也被作为一种RPC框架来使用。当在RPC中使用Avro时,服务器和客户端可以在握手连接时交换模式。服务器和客户端有彼此全部的模式,因此相同命名字段、缺失字段和多余字段等信息之间通信中需要处理的一致性问题就可以容易解决。如图所示,协议中定义了用于传输的消息,消息使用框架后放入缓冲区中进行传输,由于传输的初始就交换了各自的协议定义,因此即使传输双方使用的协议不同所传输的数据也能够正确解析。
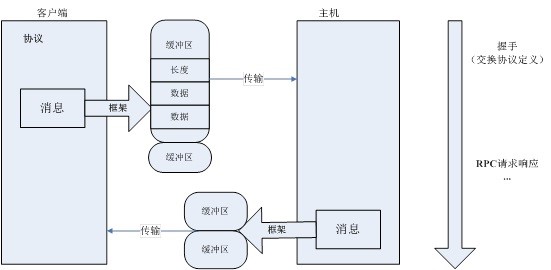
Avro作为RPC框架来使用。客户端希望同服务器端交互时,就需要交换双方通信的协议,它类似于模式,需要双方来定义,在Avro中被称为消息(Message)。通信双方都必须保持这种协议,以便于解析从对方发送过来的数据,这也就是传说中的握手阶段。
消息从客户端发送到服务器端需要经过传输层(TransportLayer),它发送消息并接收服务器端的响应。到达传输层的数据就是二进制数据。通常以HTTP作为传输模型,数据以POST方式发送到对方去。在Avro中,它的消息被封装成为一组缓冲区(Buffer),类似于下图的模型:
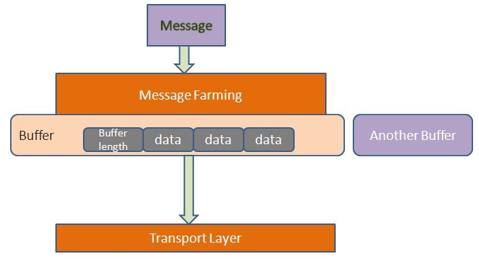
每个缓冲区以四个字节开头,中间是多个字节的缓冲数据,最后以一个空缓冲区结尾。这种机制的好处在于,发送端在发送数据时可以很方便地组装不同数据源的数据,接收方也可以将数据存入不同的存储区。还有,当往缓冲区中写数据时,大对象可以独占一个缓冲区,而不是与其它小对象混合存放,便于接收方方便地读取大对象。对象容器文件是Avro的数据存储的具体实现,数据交换则由RPC服务提供,与对象容器文件类似,数据交换也完全依赖Schema,所以与Hadoop目前的RPC不同,Avro在数据交换之前需要通过握手过程先交换Schema。
Apache Avro的使用
Apache Avro是一个数据序列化系统,广泛用于大数据处理和存储。它支持丰富的数据结构和模式演化特性。在Python中使用Avro通常涉及定义数据模式、序列化数据到Avro文件以及从Avro文件反序列化数据。以下是如何在Python中使用Apache Avro的基本步骤:
安装Avro库首先,你需要安装Avro的Python库,可以使用pip进行安装:pip install avro-python3定义Avro模式
Avro使用JSON格式来定义数据模式。以下是一个简单的模式示例,描述了一个用户的数据结构:
{
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "age", "type": "int"},
{"name": "email", "type": "string"}
]
}
将这个模式保存为user.avsc文件。
序列化数据到Avro文件
下面是如何使用Avro库将数据序列化到Avro文件的示例:
import avro.schema
import avro.io
import avro.datafile
from avro.datafile import DataFileWriter
from avro.io import DatumWriter
# 加载模式
schema_path = "user.avsc"
schema = avro.schema.parse(open(schema_path, "r").read())
# 创建一个Avro数据文件
with open("users.avro", "wb") as out_file:
writer = DataFileWriter(out_file, DatumWriter(), schema)
writer.append({"name": "Alice", "age": 30, "email": "alice@example.com"})
writer.append({"name": "Bob", "age": 25, "email": "bob@example.com"})
writer.close()
从Avro文件反序列化数据
下面是如何从Avro文件中读取数据的示例:
from avro.datafile import DataFileReader
from avro.io import DatumReader
# 读取Avro数据文件
with open("users.avro", "rb") as in_file:
reader = DataFileReader(in_file, DatumReader())
for user in reader:
print(f"Name: {user['name']}, Age: {user['age']}, Email: {user['email']}")
reader.close()
使用模式演化
Avro支持模式演化,这意味着你可以修改数据模式,而不需要重新生成所有数据。例如,假设你想为用户添加一个新的字段phone:
{
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "age", "type": "int"},
{"name": "email", "type": "string"},
{"name": "phone", "type": ["null", "string"], "default": null}
]
}
使用这种模式,旧数据仍然可以被读取,因为新字段有一个默认值。
Apache Avro是一个强大的序列化系统,特别适合大数据应用。通过定义模式,你可以确保数据的一致性和兼容性。Python的Avro库提供了简单的API来处理Avro数据文件,支持数据的序列化和反序列化,并且通过模式演化特性,可以轻松管理数据结构的变化。
参考链接:


