Argo Workflows 简介 Argo Workflows 是一个Kubernetes原生的工作流引擎,专为运行在 Kubernetes 集群上的容器化任务设计。它允许用户定义、调度和管理复杂的工作流,广泛应用于机器学习、数据处理、CI/CD 和其他自…
Apache Ranger简介 Apache Ranger是一个强大的开源安全框架,专为Hadoop生态系统中的数据治理和安全控制而设计。Ranger提供了一个集中化的安全策略管理平台,可以帮助企业管理和实施细粒度的访问控制,确保数据的安…

Kubernetes简介 Kubernetes(简称K8s)是一个开源的容器编排平台,旨在自动化应用程序的部署、扩展和管理。它最初由 Google 开发,现在由云原生计算基金会(CNCF)维护。Kubernetes 提供了一种灵活的架构来管理容器…
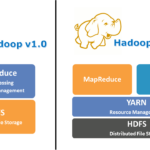
YARN简介 Apache Hadoop YARN(Yet Another Resource Negotiator)是Hadoop生态系统中的一个关键组件,负责集群资源管理和作业调度。YARN的引入大大提升了Hadoop的可扩展性和灵活性,使得不同类型的计算框架可以在…
Apache Tez 简介 Apache Tez 是一个通用的分布式计算框架,主要设计用于在 Hadoop 集群上高效执行复杂的数据处理任务。它最初由 Hortonworks 开发,后来成为 Apache 软件基金会的一个顶级项目。Tez 的主要目标是提…

Apache Pig 简介 Apache Pig 是一个用于处理和分析大型数据集的高层数据流脚本平台,主要运行在 Hadoop 集群上。Pig 提供了一种称为 Pig Latin 的语言,允许用户以更高的抽象层次来编写数据分析程序,而无需直接使…

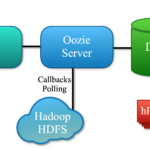
Apache Oozie简介 Apache Oozie是一个用于管理和协调Hadoop作业的工作流调度系统。它是专为处理复杂的数据处理任务而设计的,允许用户定义和执行由多个Hadoop作业组成的工作流。 核心功能 工作流调度: Oozie…
Apache Giraph简介 Apache Giraph是一个用于大规模图处理的开源分布式计算框架。它最初是由雅虎开发,并在2011年成为Apache基金会的孵化项目。Giraph的设计灵感来自Google的Pregel,它提供了一种以图为中心的计算模…

Apache Calcite 是一个动态数据管理框架,主要用于处理查询优化和查询规划。它是一个开源项目,隶属于 Apache 软件基金会。Calcite 并不是一个完整的数据库系统,而是一个用于构建数据库系统的工具箱。 主要特性…

Ambari简介 Apache Ambari是一个开源的管理平台,旨在帮助系统管理员简化大规模Hadoop集群的安装、配置和管理。它提供了一个直观的用户界面和一组RESTful API,可以轻松地操作集群中的各种服务。 产生背景 Apache…






