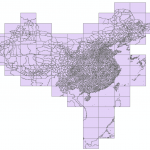
反地理查询系统中我们讲到GADM提供的数据时不符合我国的领土主张的。今天要介绍的这份数据是《1:100万全国基础地理数据库》 数据介绍 全国1:100万基础地理数据覆盖全国陆地范围和包括台湾岛、海南岛、钓鱼岛、南海…
OpenStreetMap数据简介 OpenStreetMap,简称OSM,是一个开源的世界地图,可依据开放许可协议自由使用,并且可以由人们自由的进行编辑,随着开源意识的普及,以及电子地图应用的普及,osm数据的质量和体量不断增加,…
Basemap简介 Basemap是Python可视化库Matplotlib下的一个工具包,主要功能是绘制二维地图,对于空间数据的可视化非常重要。Basemap本身不会进行任何绘图,但提供了将坐标转换为25个不同地图投影之一的功能。Matplot…
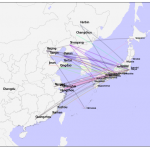
Mapbox简介 Mapbox由Eric Gunderson于2010年创立,其发展迅速,已经成为制图复兴浪潮的领导者。Mapbox专注于为地图和应用程序开发人员提供自定义底图图块,他们将自己定位为Web地图和移动应用程序的领先软件公司。…
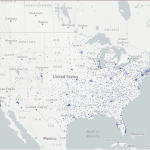
GeoPandas简介 GeoPandas是一个开源项目,旨在让使用Python进行地理空间数据分析变得更容易。它是在Pandas数据分析库的基础上构建的,用于处理地理空间数据。GeoPandas扩展了Pandas,使得可以直接使用空间数据(地…

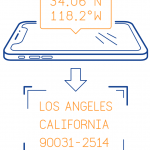
想知道某个经纬度属于哪个城市,通常可以通过地图 API 的接口实现。但是地图服务商的 API 通常会有配额限制。问题来了,能否搭建自己的经纬度反查系统呢? GADM GADM 主页:https://gadm.org/ GADM,全称 Databa…
什么是心理账户 心理账户是芝加哥大学行为科学教授Richard Thaler提出的概念。他认为,除了实际账户外,在人的头脑里还存在着另一种心理账户。人们会把在现实中客观等价的支出或收益在心理上划分到不同的账户中。比…

稀缺性的运用一开始流行于线下,如高档餐厅只提供一小份的食物,又如商家打出的“最后三天,清仓大甩卖”…这些都是商家利用稀缺性来进行的产品设计和营销。 稀缺性之所以让人向往,主要原因是会产生心理上的偏见,…
为什么要关注负面情绪? 一直以来,我们都认为好情绪,积极的情绪有利于身心健康。怒伤肝,忧伤肺,思伤脾,恐伤肾,百病皆生于气。所以,积极的情绪一直是我们追求的目标。负面的情绪,对我们就没有一点好处吗?其…

营销的核心是动机,抓住用户动机最好的方式是基于人性的弱点对产品进行设计。微信张小龙曾经说过,产品的终极目标是满足人性需求,贪嗔痴(欲望、嫉妒、执着)。类似负面情绪在产品设计中的作用 一样。针对人性弱点…
