在先前整理的自然语言处理之自动摘要这篇文章中介绍了TextTeaser和TextRank两种自动摘要的方法。今天要介绍的sumy工具不但包含了上述两种方法,还包含了其他文本摘要方法。 Sumy简介 sumy是一个用于文本摘要…

主题模型是用来在非结构数据中无监督的发现隐含主题信息的一类重要工具,比较成熟和常用的算法有基于矩阵分解(如:SVD分解)的LSA(Latent Semantic Analysis), 引入概率方法代替SVD的pLSA(Probabilistic Latent…
在HuggingFace 上,有多个模型适合用于对中文文本的迷信。这些模型通常被预训练在大规模的中文语料上,因此它们能够有效地理解和处理中文文本。以下是一些推荐的模型: bert-base-chinese bert-base-chinese 是一个…
背景与基础 目前的机器学习模型都是数学模型,其对应的输入要求必须是数字形式(number)的,而我们处理的真实场景往往会包含许多非数字形式的输入(有时候即使原始输入是数字形式,我们也需要转换),最典型的就是…
ChatGPT与GPT ChatGPT,全称聊天生成预训练转换器(英语:Chat Generative Pre-trainedTransformer),是OpenAI开发的人工智能聊天机器人程序,于2022年11月推出。该程序使用基于GPT-3.5、GPT-4架构的大型语言模型…
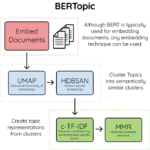
BERT简介 BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言表示的方法,由Google的研究者在2018年提出。它在自然语言处理(NLP)领域取得了革命性的进展,尤其是在理解上下文含义…

Transformer简介 Transformer是一种深度学习架构,由Google的研究者在2017年的论文《Attention Is All You Need》中首次提出。它在自然语言处理(NLP)和其他领域取得了巨大的成功,特别是在处理长序列数据方面。Tr…
在自然语言的处理中语义分析中,除了需要拆解字形外,字音有时也能表示含义。另外,在搭建搜索引擎时在搜索词query分析是也会的用到汉字转拼音或拼音转汉字的场景。 Python已经有很多包支持类似的功能,整理出来…

汉字是记录汉语的文字。汉字对发展中华民族的优秀文化起了重大的作用。汉字是世界上最古老的文字之一。汉字以象形字为基础,形、音、义、结合于一体,成为独特的方块形的表意体系的文字。 汉字的特点: 汉字的…

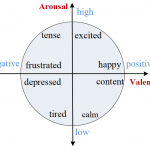
情感分析基本概念 为什么要情感分析 随着移动互联网的普及,网民已经习惯于在网络上表达意见和建议,比如电商网站上对商品的评价、社交媒体中对品牌、产品、政策的评价等等。这些评价中都蕴含着巨大的商业价值。比…