在先前整理的自然语言处理之自动摘要这篇文章中介绍了TextTeaser和TextRank两种自动摘要的方法。今天要介绍的sumy工具不但包含了上述两种方法,还包含了其他文本摘要方法。

Sumy简介
sumy是一个用于文本摘要生成的Python库。它支持多种文本摘要算法,能够从给定的文本中提取出最重要的信息,生成简洁的摘要。这对于需要快速获取文本核心内容的应用场景非常有用,例如新闻聚合、文档处理和信息检索。
sumy支持以下几种文本摘要算法:
- LSA(Latent Semantic Analysis):基于潜在语义分析的算法,通过识别文本中重要的主题来生成摘要。
- LexRank:基于图的算法,通过计算句子之间的相似性来确定句子的权重。
- TextRank:类似于PageRank的算法,构建句子图并计算每个句子的排名。
- Luhn:基于词频和位置的算法,识别重要的词并生成摘要。
- Edmundson:基于关键字、位置和频率的算法,需要手动指定重要词汇。
除此之外,sumy还允许用户自定义和扩展摘要算法。
应用场景
- 新闻聚合:从新闻文章中提取核心内容,生成简洁的摘要。
- 文档处理:对长文档进行摘要,帮助快速理解内容。
- 信息检索:在搜索结果中提供简洁的摘要,帮助用户快速找到相关信息。
Sumy支持算法简介
LSA
在文本摘要生成中,LSA(Latent Semantic Analysis,潜在语义分析)是一种基于统计和线性代数的方法,用于提取文本的主题结构并生成摘要。LSA的基本原理可以概述如下:
- 文本表示:首先,将文本表示为词项矩阵(Term-Document Matrix)。在这个矩阵中,行表示文档中的不同词项,列表示文档或句子,矩阵的值通常是词频或经过某种加权(如TF-IDF)的词频。
- 奇异值分解(SVD):对词项矩阵进行奇异值分解,将其分解为三个矩阵的乘积:U、Σ、和V^T。这里,U和V是正交矩阵,Σ是对角矩阵,其对角线上的值称为奇异值。奇异值反映了数据集中重要的潜在语义结构。
- 降维:通过保留最大的k个奇异值(通常选择能够解释大部分方差的奇异值),对矩阵进行降维。这一步的目的是去除噪声,保留文本的主要语义结构。
- 相似性计算:使用降维后的矩阵,计算文档中各句子之间的相似性。可以通过计算句子向量之间的余弦相似度来实现。
- 摘要生成:选择与文档主题最相关的句子组成摘要。通常,这些句子是与潜在语义结构(LSA生成的主题)最接近的句子。
LSA的优点在于它能够捕捉到文本中的潜在语义关系,而不仅仅是表面的词频关系。然而,它也有一些局限性,比如对输入文本的长度和质量比较敏感,同时在处理多语言文本时可能需要进行适当的预处理。
LexRank
LexRank是一种基于图的文本摘要生成算法,它利用了图排序技术(类似于PageRank)来识别文本中重要的句子。其基本原理可以概述如下:
- 文本表示:首先,将文本分割成一系列句子,并将这些句子视作图的节点。
- 相似性计算:计算句子之间的相似性,通常使用余弦相似度。相似性度量基于句子向量化表示(如TF-IDF向量)。如果两个句子的相似度超过某个预定义的阈值,就在它们之间建立一条加权边。
- 构建图:根据计算出的相似性构建无向图,句子作为节点,相似性作为边的权重。
- 图排序:应用图排序算法(如PageRank)来计算每个句子的“重要性”分数。这个分数反映了一个句子在文本中的中心性,即它与其他句子相连的程度和重要性。
- 摘要生成:根据计算出的分数,对句子进行排序,选择得分最高的若干句子作为摘要。这些句子被认为是最能代表文本主要内容的句子。
LexRank的优点在于它不依赖于语言特定的特征,具有较好的语言独立性,并且能够很好地捕捉文本中句子之间的关系。不过,它在处理长文本或具有复杂句子结构的文本时可能需要调整相似性阈值和其他参数以获得更好的效果。
TextRank
TextRank是一种基于图的排序算法,用于从文本中提取重要信息,如关键词提取和自动摘要。TextRank的核心思想与PageRank类似,通过图结构识别文本中重要的部分。
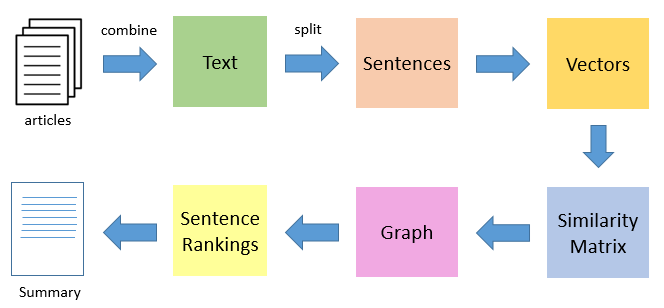
以下是TextRank生成摘要的基本原理:
- 文本表示:将文本分割成一系列句子,每个句子被视作图中的一个节点。
- 相似性计算:计算句子之间的相似性,通常使用余弦相似度或Jaccard相似度。相似性度量基于句子的向量化表示(如TF-IDF向量)。如果两个句子之间的相似度超过某个阈值,就在它们之间建立一条加权边。
- 构建图:根据计算出的相似性构建加权无向图,句子作为节点,相似性作为边的权重。
- 图排序:应用PageRank算法计算每个句子的“重要性”分数。PageRank算法通过迭代计算,识别出在图中占据中心位置的节点,即重要的句子。
- 摘要生成:根据句子的得分,对它们进行排序,选择得分最高的若干句子组成摘要。这些句子被认为是文本中最具代表性的部分。
TextRank的优势在于它不依赖于特定语言特性,能够应用于多种语言的文本处理任务。同时,它利用了图结构来捕捉句子之间的全局关系,而不仅仅依赖于局部信息。不过,在处理非常长的文本时,计算相似性和图排序可能会消耗较多的计算资源。
Luhn
Luhn摘要算法是一种经典的基于统计的方法,用于从文本中提取关键句子以生成摘要。它的基本原理相对简单,主要通过识别句子中的关键词和关键短语来确定句子的重要性。以下是Luhn生成摘要的基本步骤:
- 文本表示:将文本分割成一系列句子,每个句子被视为一个独立的单元。
- 词频统计:计算每个单词在文本中的出现频率。通常,高频词被认为是重要的词汇。
- 关键词识别:识别句子中的关键词。Luhn算法特别关注那些出现在句子中间部分的高频词,而忽略句子开头和结尾的高频词。这是因为句子的中间部分往往包含更多的内容信息。
- 句子评分:根据句子中关键词的数量和位置对句子进行评分。具体来说,Luhn算法会计算句子中关键词的数量,并根据关键词的位置给予不同的权重。例如,位于句子中间的关键词会被赋予更高的权重。
- 摘要生成:根据句子的评分,选择得分最高的若干句子组成摘要。这些句子被认为是文本中最重要和最具代表性的部分。
具体公式
Luhn算法中的句子评分公式可以表示为:
$$\text{Score}(s)=\frac{\sum_{i=1}^{n}w_i}{\sqrt{|s|}$$
其中:
- s是句子。
- n是句子中关键词的数量。
- $w_i$是第i个关键词的权重。
- $|s|$是句子的长度(单词数)。
优点和缺点
优点:
- 简单易实现,计算效率高。
- 不依赖复杂的自然语言处理技术,适用于多种语言。
缺点:
- 只考虑词频和位置,可能无法捕捉更复杂的语义信息。
- 对于某些类型的文本(如文学作品)可能效果不佳,因为这些文本中的重要信息可能不完全集中在高频词上。
总的来说,Luhn算法是一种简单但有效的文本摘要方法,特别适合处理结构化较强的文本,如新闻文章和技术报告。
Edmundson
Edmundson 摘要算法是一种早期的基于启发式的方法,用于自动生成文本摘要。它结合了多种特征来评估句子的相对重要性。以下是 Edmundson 摘要算法的基本原理:
- 文本表示:将文本分割成句子,每个句子作为一个独立的单元进行分析。
- 特征选择:Edmundson 算法使用多个启发式特征来评估句子的权重。这些特征包括:
- 关键词(Cue Words):包含特定关键词的句子被认为更重要。这些关键词通常是预定义的,与主题密切相关的词。
- 标题词(Title Words):出现在标题或副标题中的词被认为是重要的。包含这些词的句子可能具有更高的权重。
- 位置特征(Location Features):通常情况下,出现在段落开头或结尾的句子可能更重要。
- 词频(Term Frequency):句子中高频词的密度也可以作为一个衡量标准。
- 句子评分:根据上述特征对每个句子进行评分。通常使用一个线性组合的方式,将每个特征的贡献加权求和,得到句子的总得分。
- 摘要生成:根据句子的得分排序,选择得分最高的若干句子组成摘要。这些句子被认为是最能代表文本主要内容的句子。
优点和缺点
优点:
- 结合多种特征,可以捕捉文本的多方面信息。
- 可以通过调整特征的权重来适应不同类型的文本和应用场景。
缺点:
- 需要预定义关键词和标题词,可能需要人工干预。
- 特征选择和权重的设置对摘要质量有较大影响,需要经验和调试。
Edmundson 算法在现代应用中可能不如基于机器学习和深度学习的方法那么强大,但它为自动摘要技术的发展奠定了基础,并提供了一种结合多种特征进行综合评估的思路。
Sumy 的使用
安装 Sumy
可以通过 pip 安装 sumy:pip install sumy
此外,sumy 依赖于 nltk,需要安装相关的预料与模型。具体方法见:自然语言处理工具包之 NLTK
基本用法
从文本生成摘要
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lsa import LsaSummarizer
# 要进行摘要的文本
text = """
Natural Language Processing (NLP) is a sub-field of artificial intelligence (AI) focused on the interaction between computers and humans through natural language.
The ultimate objective of NLP is to read, decipher, understand, and make sense of human languages in a valuable way.
"""
# 创建文本解析器
parser = PlaintextParser.from_string(text, Tokenizer("english"))
# 创建 LSA 摘要器
summarizer = LsaSummarizer()
# 生成摘要(提取 2 个句子)
summary = summarizer(parser.document, 2)
# 输出摘要
for sentence in summary:
print(sentence)
从 URL 生成摘要
from sumy.parsers.html import HtmlParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.text_rank import TextRankSummarizer
# 要进行摘要的网页 URL
url = "https://example.com/some-article"
# 创建 HTML 解析器
parser = HtmlParser.from_url(url, Tokenizer("english"))
# 创建 TextRank 摘要器
summarizer = TextRankSummarizer()
# 生成摘要(提取 3 个句子)
summary = summarizer(parser.document, 3)
# 输出摘要
for sentence in summary:
print(sentence)
支持多种语言
Sumy 支持多种语言的文本摘要。使用时只需更改 Tokenizer 中的语言参数即可,例如使用中文:
parser = PlaintextParser.from_string(text, Tokenizer("chinese"))
注意事项
- 算法选择:不同的算法适用于不同类型的文本,可能需要根据具体需求进行选择和调整。
- 参数调整:有些算法可能允许调整参数(如相似性阈值等),可以根据需要进行微调。
- 语言支持:确保使用的语言在 Sumy 支持的范围内,并且文本的编码格式正确。
Sumy 是一个强大而灵活的工具,适合快速实现自动摘要功能。通过选择合适的算法和参数,可以为不同的应用场景生成高质量的摘要。
参考链接:


