最近在整理规则引擎相关的知识点,看到Bilibi的相关文章,稍微整理出来供参考。Bilibili目前已经将其开发的规则引擎gengine开源了,有兴趣的朋友可以深入研究下。
由于自己对Golang不了解,所以这里不会涉及到具体的代码实现层面的内容,这里主要整理的是其开发思路。
规则引擎在B站的应用场景
随着对业务理解的不断深入和抽象,很多业务场景的功能(代码)都可以抽象成”规则+指标”的模式。这种模式,可以应用于很多场景,如:
- 风控场景,识别黑产,需要各种规则来进行判别;
- 流量(内容)分发场景,需要基于各种可收集的指标,组成规则,然后基于规则,来对用户进行定制化的内容分发;
- 推荐场景,推荐本身就是一个基于多指标的典型规则场景模式(或者说,机器学习就是一个收集数据指标,然后进行学习,最后进行推广的过程)。
- 数据清洗场景,有些业务数据需要使用规则进行打标、清洗、识别,最后落表使用。
规则引擎在B站的迭代(前期)
第一代规则引擎
仅支持逻辑运算符(&&, ||, !, 外加括号),主要是用来解析逻辑表达式,通过定义特定占位符,来绑定具体的子操作,然后使用子操作的结果来进行逻辑运算,并得到整个逻辑表达式的最终结果。
如,逻辑表达式规则:”$1&&$2″, $1和$2占位符(也叫指标),接受规定个数的参数,然后分别输出true或false,逻辑表达式再对占位符的结果进行完整的逻辑运算,并得到最终的结果。
第一代规则引擎特点:
- 简单,因为简单,所以执行性能相当好;
- 扩展能力弱,可以满足逻辑判别要求,但无法满足数值判别要求;
- 工程需要重新发版,当添加新的占位符运算时,工程需要重新发版。
- 不利于记忆,这种规则表现形式,不利于人记忆,时间久了,要搞清楚占位符代表的是什么,还要回头去看当初写的文档。
第二代规则引擎
基于某些解释型语言的规则引擎,如Java支持的Javascript的执行引擎,那么规则的编写语言就是Javascript,写规则就是在写Javascript。规则引擎就是java虚拟机支持的Javascript执行引擎本身。
第二代规则引擎特点也很明显:
- 表现能力强,所引入的解释型语言有多强,规则表现能力有多强。
- 无需重新发版。
- 执行性能略差。
- 接入成本高,使用复杂,使用者(常常是数据挖掘、数据分析、产品等人员,他们常常缺乏代码能力)为了配置几个规则,不得不花很多精力去学习一门语言,即使开发者自身,如果不熟悉规则配置语言,也一样要去学习。如此一来,规则的配置难度和使用成本极大,以致于难以推广;毕竟,如果都学会了这门语言,我何不直接撸代码呢?那样性能还高,也直接。
第三代规则引擎
为了延续规则的表现能力,同时为了降低规则的配置难度,且免于学习一门新语言的代价,第三代规则引擎将实现规则引擎自身的语言作为规则配置语言,同时还加入了一些有用的规则属性,如”规则名称”、”规则优先级”、”规则描述”等。第三代规则引擎的典型代表是Java实现的drools。
第三代规则引擎的特点是:
- 规则表现力强,可基于用户指定的规则优先级,来先后执行规则;
- 配置简化,简化了一些复杂的且不必要的语法。
- 对开发友好,对配置规则者不友好,第三代规则引擎适合熟悉规则引擎开发语言自身的开发人员使用,但当推广至其他人员使用时,依旧免不了要让不熟悉此语言的人重新学习一门语言(规则配置复杂度并没有真正消除);
- 性能偏弱,不能完全满足实时、高性能服务场景的需求(具体见下文举例)。
B站新一代规则引擎的设计
预期的规则引擎:
- 支持规则优先级新的同类型的产品,不应该丢掉老版产品的优点,这些优点不仅是优点,还是一种业务开发财产。
- 使用足够简单、灵活。这个要求,对规则在配置上的难易程度提出了要求。本质上是提出了规则与具体代码之间的界限划分。
- 可选择的规则执行模式。因为通过观察各个场景发现,没有一种执行模式是万能的,无论是基于性能考量,还是基于业务本身考量,不同的场景需要不同的执行模式。
- 高性能。这当然是最重要的,如果不能满足高性能,高并发的需求,最终还是会被扔到历史的垃圾堆中。
- 和golang的无缝对接。因为B站业务开发是以golang为主要开发语言,因此,开发的规则引擎必须要要能和golang无缝对接才行。
- 其他的小确幸:支持注释,变量…等等
规则引擎尽管形式看起来复杂,但其实本质只有4种:
- 逻辑运算
- 四则运算
- ..else选择结构
- 预加载的API
指标依赖于具体领域场景的程序原,抽象的越好,规则使用越简单。这里也有一点小技巧,通常,我们看到的所有数据形式也只有三种:字符串、数字、布尔型。基于此,我们在这3个基础上来抽象具体领域的指标。另外,规则的解析和规则执行是异步的(用户可以在任何时候解析新来的规则字符串),所以规则引擎特别适合实时的、动态修改、下发规则。
规则引擎如何支持更一般的机器学习模型调用呢?通常训练出来的模型最终会以API接口的形式向外提供服务,这个正好由函数来支持的。
通过对各种业务场景的分析提炼,一个规则引擎至少应该满足3种执行模式。但实际上,规则执行模式至少有5种,具体执行模式,如下图所示:
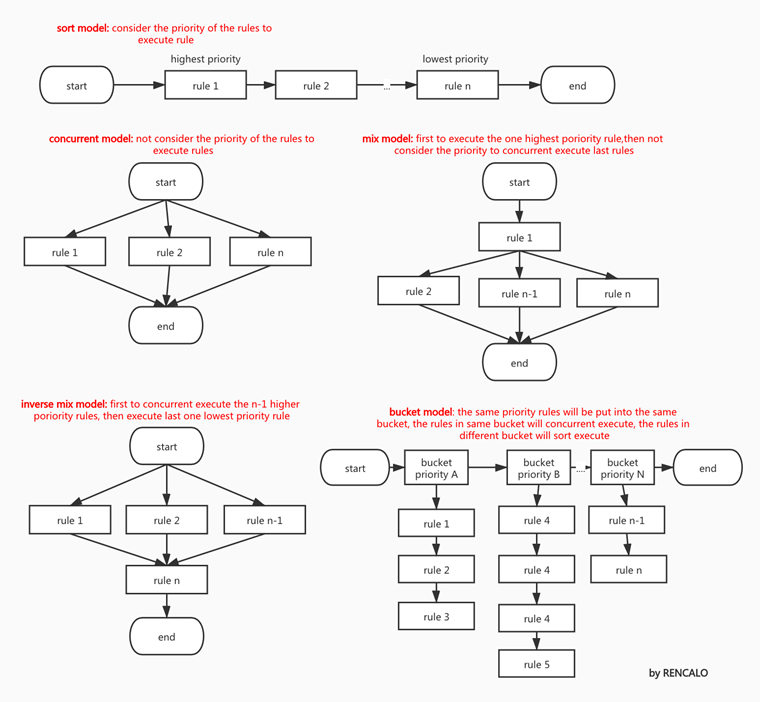
- 顺序模式(sort model):规则优先级高越高的越先执行,规则优先级低的越后执行。这也是drools支持的模式。此模式的缺点很明显:随着规则链越来越长,执行规则返回的速度也越来越慢。
- 并发执行模式(concurrent model):在此执行模式下,多个规则执行时,不考虑规则之间的优先级,规则与规则之间并发执行。规则执行的返回的速度等于所有规则中的执行时间最长的那个规则的速度(逆木桶原理)。执行性能优异,但无法满足规则优先级。
- 混合执行模式(mix model):规则引擎选择一个优先级最高规则的最先执行,剩下的规则并发执行。规则执行返回耗时=最高优先级的那个规则执行时间+并发执行中执行时间最长的那个规则耗时;此模式兼顾优先级和性能,适合于有豁免规则(或前置规则)的场景。
- 逆混合执行模式(inverse mix model):优先级最高的n-1个规则并发执行,执行完毕之后,再执行剩下的一个优先级最低的规则。这种模式适用于有很多前导判断规则的场景。其特性与混合模式类似,兼顾性能和优先级。
- 桶模式(bucket model):规则引擎基于规则优先级进行分桶,优先级相同的规则置于同一个桶中,桶内的规则并发执行,桶间的规则基于规则优先级顺序执行。
参考链接:


