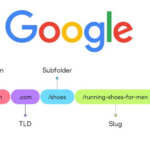
为什么需要了解Google搜索URL参数 在浏览器地址栏里,一个不起眼的Google搜索链接蕴藏着远超表面浏览的精密控制力。当你输入关键词并按下回车,生成的URL并非一串单纯的字符,而是一份由多个参数精确编码的“搜索指…
百度作为中国互联网的入口级应用,其搜索功能的每一次调用都通过一个精心设计的URL(统一资源定位符)来完成。这些看似复杂的URL字符串,实则是一个由众多参数构成的精密系统,它不仅决定了搜索结果的呈现,更承载…

在当今自动化运维和持续集成的时代,定时任务管理平台已成为开发者和运维团队不可或缺的工具。它们不仅能够替代传统的 crontab,还提供了可视化界面、任务监控、错误告警和分布式调度等高级功能。本文将介绍一个知…

《思考,快与慢》是诺贝尔经济学奖得主丹尼尔·卡尼曼的集大成之作,它并非一本简单的心理学或经济学著作,而是一幅描绘人类思维运作机制的精密地图。本书的核心价值在于,它系统地揭示了那些潜藏在我们日常判断与决…

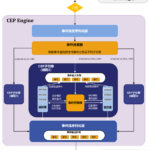
在当今数据驱动的时代,业务系统每秒都在产生海量的实时事件流,如用户点击、交易记录、设备传感器读数等。这些孤立的数据点本身价值有限,但当它们按照特定顺序和逻辑组合起来时,往往揭示了更深层次的业务洞察——…
复杂事件处理(Complex Event Processing,CEP)是一种能够实时分析并响应海量数据流中事件的技术框架。其核心目标是从庞杂、源源不断的数据流中,通过预定义的规则,识别出有意义的事件模式或将简单事件组合成具有…
本文基于知名创业孵化器Y Combinator创始人保罗·格雷厄姆(Paul Graham)的核心理念,系统梳理了创业从构思到执行、从增长到融资的全过程关键原则。内容经过优化与重组,旨在为创业者提供一份清晰、实用的行动指南…

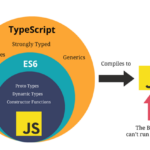
TypeScript 作为现代前端开发的核心工具之一,已从一种可选的增强语言演变为构建大型、可维护应用的事实标准。它不仅是 JavaScript 的超集,更是一套完整的工程化解决方案。以下将从定义、核心特性、与 JavaScript …
在暴雪娱乐(Blizzard Entertainment)出品的《魔兽争霸》《星际争霸》等经典游戏中,大部分游戏数据都被封装在一个名为MPQ的大型档案文件中。如果采用最朴素的查找方式——从文件头部开始逐个比对字符串,直到找到目…

在当今的网页浏览体验中,我们常常会遇到各种不便,例如恼人的广告、不友好的界面设计,或是希望自动化某些重复操作。Tampermonkey(俗称油猴或篡改猴)作为一款强大的浏览器扩展,允许用户通过编写JavaScript脚本…
