在开源可视化报表工具Superset、metabase、Redash时,已经涉及到一部分在线SQL工具的内容,但是其整个整个可视化工具的一部分。今天要介绍的是另外独立的开源在线SQL工具。
在线SQL查询SQL
SQLPad
SQLPad是一个开源的web应用程序,专门用于编写和运行SQL查询以及查看结果。它提供了一个直观的用户界面,使得用户能轻松地执行和保存查询,查看查询历史,以及将结果导出为CSV或JSON格式。
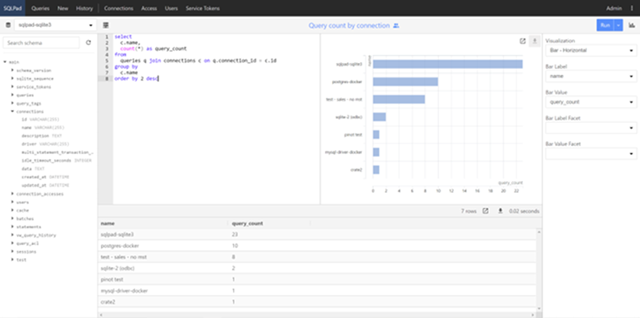
SQLPad支持多种数据库,包括但不限于MySQL, PostgreSQL, SQLServer, AmazonRedshift, GoogleBigQuery, Crate,Vertica,以及Presto。
除了上述的基本功能,SQLPad还提供了一些高级功能,如查询排版,自动化运行查询,以及可视化查询结果等。另外,SQLPad还有一个强大的用户和角色管理系统,可以对用户的权限进行细粒度的控制。
为了方便用户使用,SQLPad提供了Docker镜像,可以快速地在任何支持Docker的环境中部署。
总的来说,如果你在寻找一个轻量级的,功能完备的SQL查询工具,SQLPad是一个不错的选择。
CloudBeaver
CloudBeaver是一个免费开源的数据库管理工具,它基于Web并且跨平台使用。CloudBeaver致力于为用户提供友好的界面和便捷的数据操作。
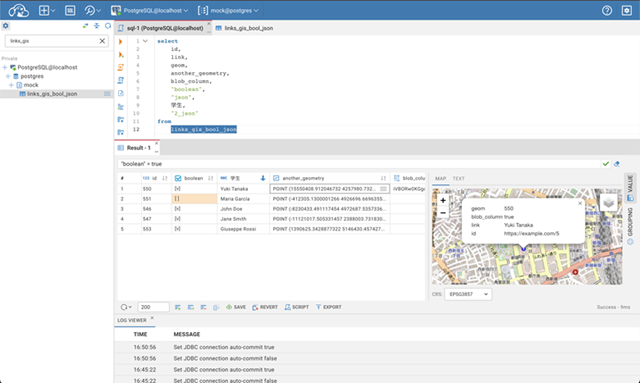
以下是CloudBeaver的一些主要特性:
- 支持的数据库多样:CloudBeaver支持多种数据库,包括MySQL, PostgreSQL, MariaDB, SQLite以及更多其它的数据库类型。
- 数据浏览和编辑:用户可以方便地查看和编辑数据,无需编写SQL语句。
- SQL编辑器:这个功能允许用户编写、执行SQL查询,并可以查看查询结果。
- 数据导出:用户可以将查询结果导出为各种格式,例如CSV、JSON等。
- 多用户支持:CloudBeaver支持多用户同时在线操作,提供权限管理和访问控制。
- 可定制和扩展:开发者可以根据自己的需求扩展CloudBeaver的功能。
- 安全性:CloudBeaver提供了数据加密和安全传输的功能,保证了数据的安全性。
总的来说,CloudBeaver是一个功能全面、易用的数据库管理工具,适合各种规模的团队使用。
Querybook
Querybook是一个开源的数据查询平台,允许数据分析师以协作的方式编写、组织和共享他们的数据查询和分析。这个工具主要面向处理大规模数据集,支持连接到各种数据仓库服务。
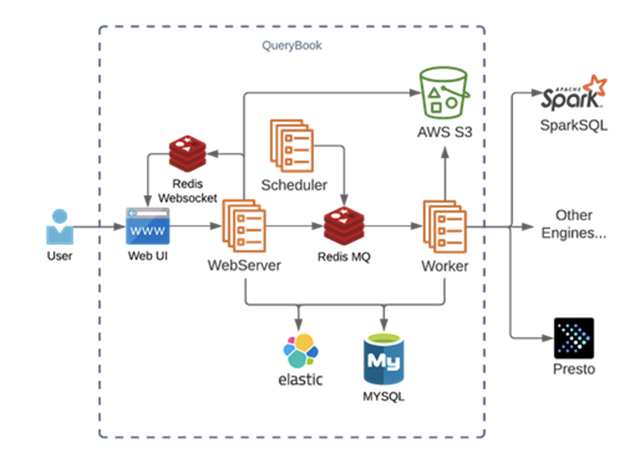
以下是Querybook的一些核心特点:
- 多种数据引擎支持:Querybook支持多种数据查询引擎,例如Hive, Presto, MySQL, PostgreSQL等,从而能够适应多样化的数据源需求。
- 交互式查询工作区:用户可以在Querybook中编写和执行SQL查询,使用智能自动完成功能提高效率。
- 查询记录和组织:每个查询都会被自动保存,方便用户回溯历史。查询可以被组织成文档,而文档可以被分门别类地管理。
- 共享和协作:Querybook允许用户分享查询和结果,团队成员之间可以协作,共同编辑查询文档。
- 数据可视化:查询结果可以直接在Querybook中进行基本的图表可视化,帮助用户更好地理解数据。
- 数据表元数据查看:Querybook可以显示数据表的详细元数据信息,如字段名、类型和注释等,便于用户理解数据结构。
- 查询调度:它支持设置定时任务来执行查询,适用于需要定期运行的报告或数据提取任务。
- 权限和安全管理:Querybook提供了权限管理功能,管理员可以设置不同用户对于不同数据源和查询文档的权限。
总之,Querybook是一个便于数据团队协作的工具,它提供了丰富的功能来帮助用户执行数据查询、分析和共享。通过优化数据查询和分析的流程,Querybook旨在使得数据工作更加高效和有组织。
元数据管理
databasir
Databasir是面向团队的关系型数据库模型文档管理平台,旨在通过自动化的方式解决模型文档管理过程中维护成本高、内容更新不及时以及团队协作复杂等问题。
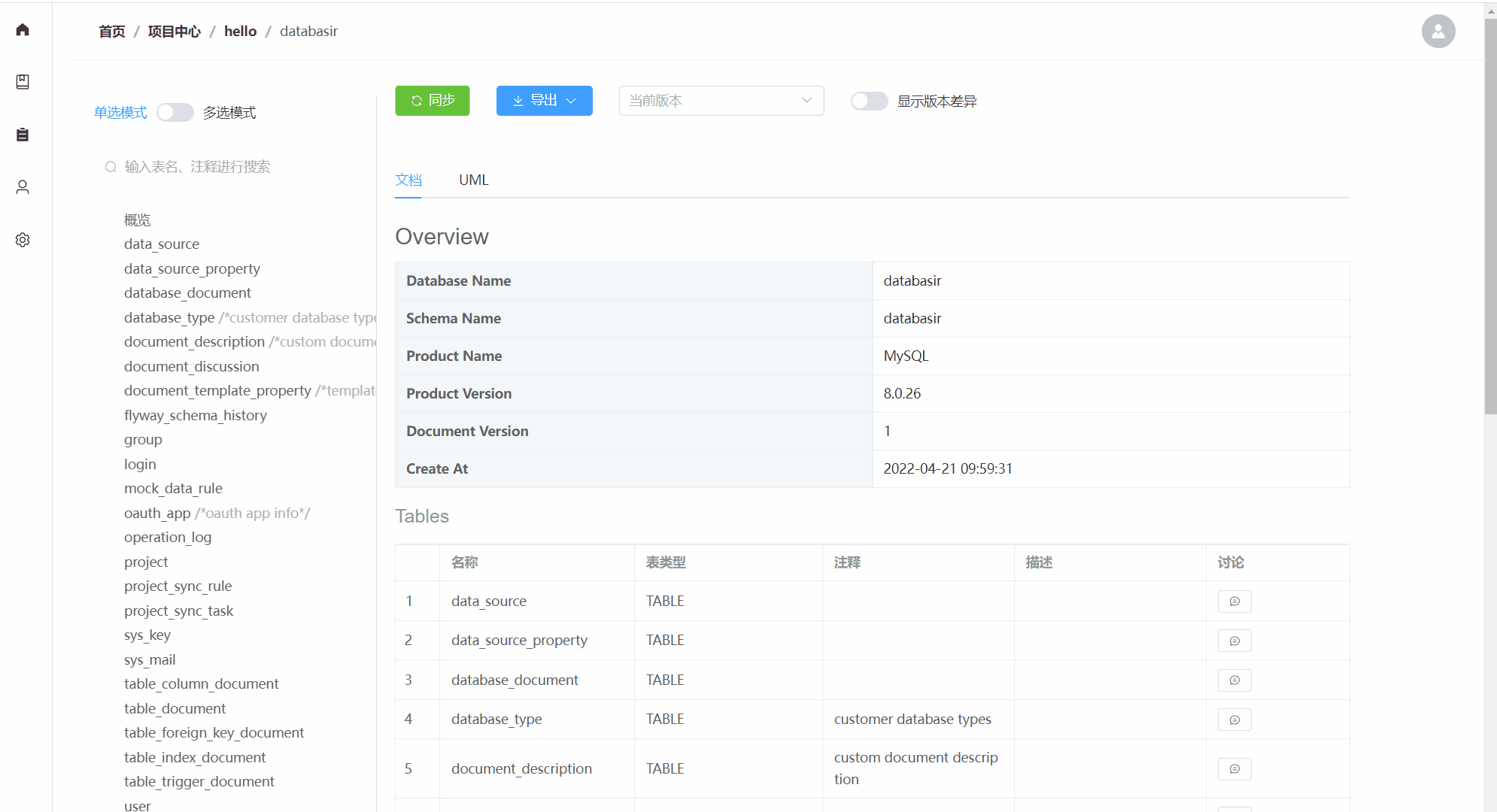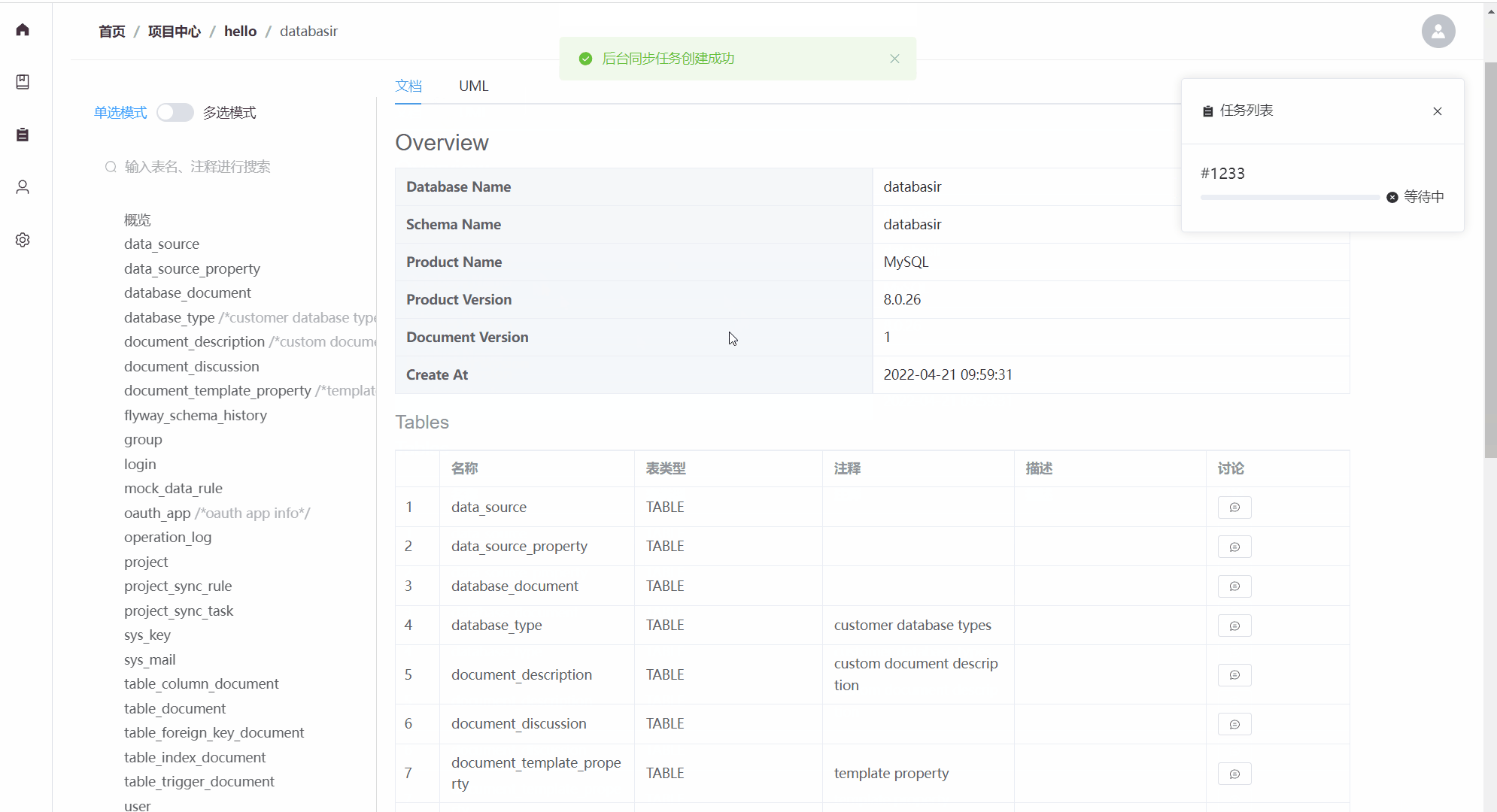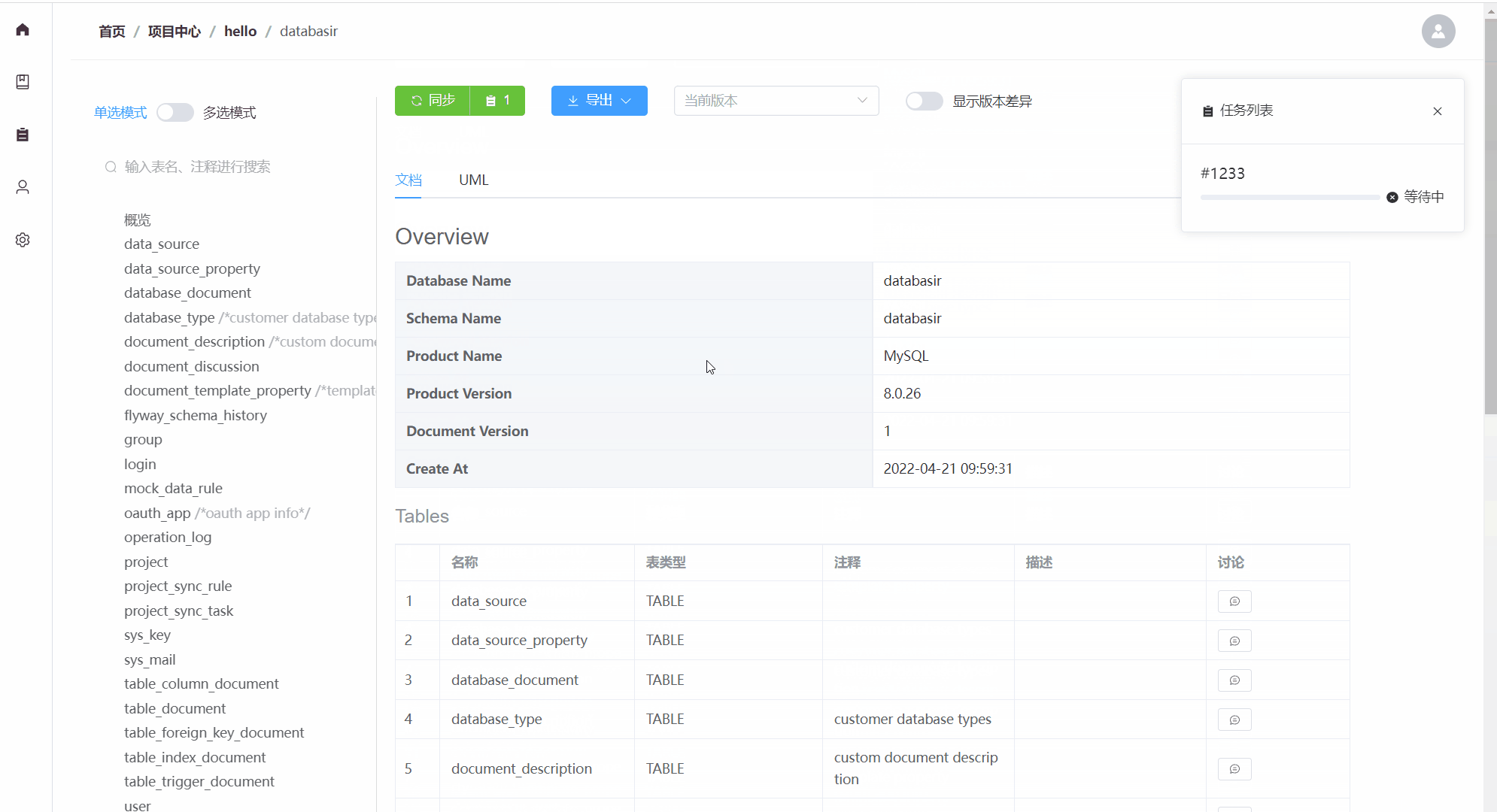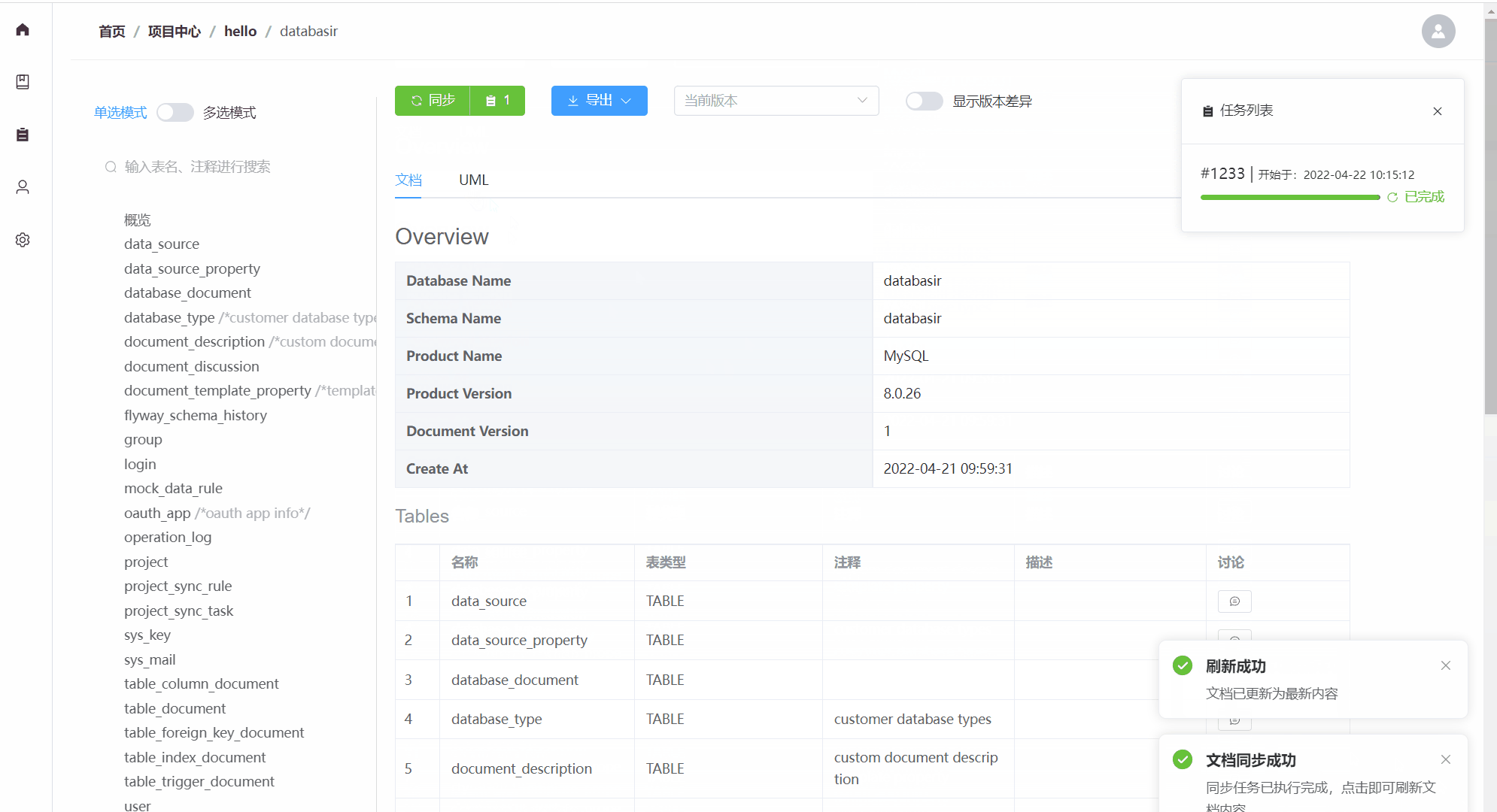
主要包含以下功能:
- 支持mysql、postgresql等常用数据库(理论拥有JDBC驱动的数据库都能支持)
- 自动或手动同步数据库Schema并生成文档
- 数据库历史版本文档查看
- 支持markdown等格式导出
- 扁平化的权限管理模式,团队管理、成员管理一应俱全
- 关注数据库安全,密码加密存储,并且不会再返回前端
- ……
DataHub
DataHub是由LinkedIn开发的一个开源的元数据平台,旨在帮助企业构建出可扩展的、可靠的、实时的数据系统。它可以收集、存储和服务企业级的元数据,以促进数据发现、数据治理和数据观察性。
以下是DataHub的一些核心特点:
- 元数据收集:DataHub可以从不同来源(例如数据库、数据流平台、数据仓库等)收集元数据。
- 数据发现和搜索:DataHub提供了强大的搜索引擎,帮助用户方便快捷地查找数据资产。
- 数据血缘:DataHub提供了数据血缘视图,可以清楚地描绘出数据是如何从源头流向下游的,以及数据在流转过程中的转换关系。
- 数据目录:DataHub提供了一个统一的数据目录,可以查看企业中所有的数据资产,包括表格、指标、数据流等。
- 数据治理:DataHub支持数据的标签和注释,可以在元数据层面进行数据治理,提升数据的质量和可信度。
- 扩展性:DataHub的元数据模型是可扩展的,可以根据业务需求定制元数据类型。此外,DataHub采用微服务的架构设计,更加容易扩展和集成。
- 社区驱动:DataHub是一个由社区驱动的开源项目,拥有活跃的开发者社区和广泛的用户群体。
DataHub的设计理念是让元数据成为数据驱动决策的关键环节,帮助企业构建起更健全的数据治理框架,提升数据的可用性和价值。在大规模和复杂的数据环境中,DataHub提供了一种有效的解决方案,以管理和利用元数据。
Datahub的优点:
- 名门开源,与 Kafka 同家庭。社区活跃,发展势头迅猛,版本更新迭代迅速。
- 定位清晰且宏远,Slogan 可以看出团队的雄心壮志及后期投入,且不断迭代更新的版本也应证了这一点。
- 底层架构灵活先进,未扩展集成而生,支持推送和拉去模式
- UI 界面简单易用,技术人员及业务人员友好
- 接口丰富,功能全面
Datahub 的不足:
- 前端界面不支持国际化,界面的构建和使用逻辑不够中国化
- 版更更新迭代快,使用后升级是个难题
- 较多功能在建设中,例如 Hive 列级血缘
- 部分功能性能还需要优化,例如 SQL Profile
- 中文资料不多,中文交流社群也不多
Atlas
Apache Atlas 是一个开源的可扩展的数据治理和数据元数据管理平台。它由 Apache Foundation 开发,可以帮助企业在大数据生态系统中实现数据治理的目标。
以下是 Apache Atlas 的一些主要特性:
- 元数据管理:Apache Atlas 提供了一种集中化的方式来管理您的数据资源的元数据。这包括数据集的源头位置、创建时间、使用频率、数据质量、数据所有者等信息。
- 数据血缘视图:Atlas 能够生成数据的血缘视图,这可以帮助用户了解数据的来源、数据流向以及数据如何在处理过程中被转换。
- 数据分类和标签:用户可以为数据资源添加分类和标签,这将帮助改进搜索结果,使数据更容易被发现和理解。
- 安全和策略执行:Atlas 可以与 Apache Ranger 集成,以便在大数据平台上实施安全策略。Apache Ranger 可以在元数据层级上实施安全策略,使得数据访问权限可以根据 Atlas 中的标签和分类进行控制。
- 开放 API:Atlas 提供了 RESTful API,使得用户能够将 Atlas 集成到其他应用或数据工具中。
- 数据质量管理:Atlas 也可以用来跟踪和管理数据质量,为数据质量提供了一个统一的评估标准。
Atlas 的优点:
- 大厂开源,深度集成 Hadoop 生态中的 Hive,支持表级、字段级血缘
- 与 HDP 原生集成,支持对接 Ranger 实现行列级数据权限管控,安装便捷省心
- 强大的元数据元模型,支持元数据定制及扩展
- 源代码不复杂,国内有大量平台基于 Atlas 定制修改为商用产品
Atlas 的不足:
- 其优势也是劣势,母开源公司已被并购,历史悠久,不再是一种优势,反而是一种负担
- Hadoop 体系已经走向衰退,如何只是完美支持 Hive 和 Hadoop 体系,已经无法满足现在快速发展的技术要求
- 其设计界面复杂,体验老旧、数据目录及数据检索都不够便捷
- 使用体验复杂及产品功能更聚焦于解决技术人员的问题,而非数据的最终用户,比如业务人员
- 生态渐渐失去新鲜感、新的类似平台不断发展
Marquez
Marquez 是一个开源的元数据服务,专为数据治理而设计。它提供了一种集中的方法来收集、聚合和可视化一个公司的数据集的元数据。Marquez 旨在帮助数据团队发现数据集的来源,了解数据集之间的依赖关系以及它们是如何被数据处理工作流(如 ETL 作业)所使用。
以下是 Marquez 的一些核心特性:
- 数据集元数据跟踪:Marquez 能跟踪数据集的元数据,包括其创建时间、最后更新时间、位置、架构和其他描述性信息。
- 作业元数据跟踪:它可以跟踪数据处理作业的详情,包括作业的输入和输出数据集、执行时长和状态。
- 数据血缘关系:Marquez 强调数据血缘(Lineage)的重要性,能够展示数据集之间的关系和它们是如何随着时间演变的。这有助于理解数据的来源和使用情况。
- 集成和兼容性:Marquez 可以与现有的数据处理工具和平台集成,比如 Apache Airflow,提供 API 以便其他系统能够与之交互。
- 数据质量和可靠性:通过记录和展示数据集的更新历史,Marquez 帮助提高数据分析的质量和可靠性。
- 开放标准:Marquez 使用开放标准(如 OpenLineage)来定义数据集和作业的元数据模型。
作为一个数据治理工具,Marquez 非常适合企业和大型组织,它们需要对公司范围内的数据集进行管理和监控。通过 Marquez,数据工程师和分析师可以更好地理解和利用现有数据资源,推动更加透明和高效的数据协作。
Marquez 的优点:
- 界面美观,操作细节设计比较棒
- 部署简单,代码简洁
- 依靠底层 OpenLineage 协议,结构较好
Marquez 的不足:
- 聚焦数据资产/血缘的可视化,数据资产管理的一些功能,需要较多开发工作
Amundsen
Amundsen 是一个开源的数据发现和元数据平台,由 Lyft 创建,旨在帮助数据分析师和数据科学家更快地发现和搜索公司内部的数据资源。通过提供一个集中的数据信息库,Amundsen 使用户能够检索和浏览数据集、表、字段等元数据。
Amundsen 的名称来自挪威探险家罗尔德·阿蒙森,他是第一个到达南极点的人,这个名字反映了平台帮助用户探索和发现数据的能力。
以下是 Amundsen 的一些关键特点:
- 数据发现:Amundsen 提供强大的搜索功能,使用户能够通过关键词快速查找公司内部的数据集和相关信息。
- 数据浏览:用户可以浏览不同的数据源和数据集,以及查看表的元数据,如字段类型、描述和数据预览。
- 数据使用情况和人气:Amundsen 会展示数据集的使用频率和”人气”,帮助用户识别哪些数据集最常被访问和依赖。
- 数据血缘和关系:提供数据之间的血缘关系图,帮助用户了解不同数据集如何相互关联,以及数据是如何流动和转化的。
- 用户协作:Amundsen 允许用户添加对数据集的标签、描述和注释,提高数据集的易用性和透明度。
- 集成:能够与多种数据源和数据湖技术(如 Hive, Presto, Redshift 等)集成,确保能获取广泛的数据元信息。
- 数据质量指标:部分部署可以集成数据质量指标,帮助用户评估数据的可靠性。
Amundsen 的设计理念是降低数据资产的发现成本,并加强团队内部对数据的理解和协作。一个集中化的数据目录能够显著提升数据团队的效率,避免重复工作,以及减少因数据误解导致的错误。对于拥有大量分散数据集的企业来说,Amundsen 是一个有价值的工具。
Amundsen 的优点:
- Lyft 大厂开源,社区活跃,版本更新较多
- 定位清晰明确,与 Datahub 类似,致力于成为现代数据栈中的数据目录产品
- 支持对接较多的数据平台与工具
Amundsen 的不足:
- 中规中矩的 UI 界面,操作便捷性不足
- 中文文档不多
- 血缘、标签、术语等功能方面不如 Datahub 使用便捷
- 较多支持友好的组件,国内使用的不多
OpenDataDiscovery
OpenDataDiscovery Platform (ODDP) 是一个开源的企业级数据目录解决方案,由 Yotabites 创建并维护。其主要目标是帮助数据科学家和分析师在大规模数据环境中更快地发现、理解和信任数据。
以下是 OpenDataDiscovery Platform 的一些主要特性:
- 多数据源集成:ODDP 支持与多种数据源集成,包括 Hadoop HDFS, AWS S3, Google Cloud Storage, SQL 数据库等,以便于收集和管理元数据。
数据血缘:ODDP 执行数据血缘分析,能够显示数据的来源和去向,以及数据是 OpenDataDiscovery(ODD)是一个开源的数据发现和数据观测平台,旨在帮助团队管理和监控他们的数据资产。它提供了对数据目录、数据质量、数据血缘以及数据的使用情况的可视化,从而增强数据的透明度和可信度。
下面是 ODD 的一些核心特性:
- 数据目录:ODD 允许组织构建一个全面的数据目录,其中包含了关于数据集、数据库、表以及字段的详细元数据信息。这有助于用户快速找到需要的数据资产。
- 数据血缘:数据血缘的可视化帮助用户理解数据之间的关系,比如数据是如何从一个系统流向另一个系统,以及数据是通过哪些处理步骤被转换的。
- 数据观测:ODD 提供数据观测功能,使得团队能够监控数据的健康状态,警告数据的异常情况,如断链、延迟更新或不一致性。
- 数据质量:提供数据质量评分和指标,帮助用户评估数据的准确性、完整性和一致性。
- 数据使用分析:ODD 可以分析数据的使用模式,确定哪些数据资产最受欢迎,从而更好地理解组织中的数据需求。
- 集成能力:OpenDataDiscovery 可以集成多种数据源和数据处理工具,方便用户从一个统一的平台监控和管理不同系统中的数据。
- 社区驱动:作为一个开源项目,ODD 由一个活跃的社区支持,不断地增加新的功能和改进现有的特性。
ODD 强调数据的可发现性、可观测性和质量管理,通过提供这些功能,它帮助企业建立起更健全的数据治理框架,支持数据驱动的决策过程。对于需要跨越多个数据源和平台管理数据的组织来说,ODD 是一个有价值的工具。
OpenDataDiscovery 的优点:
- 提供在线体验 Demo 环境,有助于推广拉新
- UI 界面美观漂亮,界面操作逻辑符合国人使用习惯
- 项目年轻,能够在已有的众多数据资产项目中吸取经验
- 集成了数据质量模块
- Datahub 有的一些优秀功能都做了规划
- 支持开放数据标准,感觉也没啥用,国内玩不转
- 提供了调度工作流告警接口
- 基于数据可观测的新理念设计
- ML 是第一等公民,这个是对赌未来的 AI 发展预期
OpenDataDiscovery 的不足:
- 项目处于起步阶段,社区还不太活跃
- 与 Datahub 大量功能重叠
- 中文资料少的可怜
OpenMetadata
OpenMetadata 是一个开源的元数据框架,旨在促进数据治理和数据发现,以及加强企业内部数据的协作和管理。该框架通过提供一套元数据服务和规范,帮助组织标准化对数据资产的描述,方便团队成员理解、搜索和使用数据。
OpenMetadata 的主要特点包括:
- 统一的元数据模型:它定义了一个统一的元数据模型,该模型可以跨不同数据平台和工具使用,并提供了一致性和互操作性。
- 数据目录:OpenMetadata 提供了一个数据目录功能,它允许用户浏览和搜索企业中的数据资产,包括数据表、指标、仪表板等。
- 数据血缘和关系:它能够捕获和展示数据资产之间的关系和血缘,包括数据的来源、转换和消费路径。
- 数据质量:OpenMetadata 框架允许集成数据质量指标和校验,以评估和监控数据的质量。
- 数据访问和安全:框架支持管理数据访问策略和跟踪数据访问的历史记录,提高数据的安全性和合规性。
- 数据注释和协作:用户可以在数据资产上添加注释、标签和描述,以增强团队间的协作和数据资产的文档化。
- 分布式架构:OpenMetadata 设计为分布式系统,支持在复杂的数据环境中进行扩展和部署。
- API 和集成:它提供了 RESTful API 和各种集成接口,以便与现有的数据工具和平台(如 ETL、BI 等)相连通。
OpenMetadata 的优点:
- 提供在线体验 Demo 环境,有助于推广拉新
- UI 界面美观漂亮,界面操作逻辑符合国人使用习惯
- 项目年轻,能够在已有的众多数据资产项目中吸取经验
- 集成了数据质量模块
- 支持开放数据标准,感觉也没啥用,国内玩不转
- 基于数据可观测的新理念设计
OpenMetadata 的不足:
- 项目处于起步阶段,国人参与不多
- 与 OpenDataDiscovery 的区分度不是特别大
- 产品还在快速开发中
- 中文资料少的可怜
其他参考资料:


