文章内容如有错误或排版问题,请提交反馈,非常感谢!
Amundsen简介
Amundsen是一个开源的数据发现和数据目录工具,最初由Lyft开发。它旨在帮助企业用户更好地理解、发现和利用组织内的数据资源。通过提供一个直观的界面和强大的搜索功能,Amundsen使数据科学家、分析师和工程师能够快速找到所需的数据集、表格、列、仪表板等数据资产,从而提高数据的可用性和组织内数据的使用效率。
核心特性
- 数据发现:
- Amundsen提供强大的搜索和发现功能,支持通过关键字、标签和元数据来查找数据资产。
- 用户可以快速搜索并找到相关的数据集、表、列和仪表板。
- 元数据管理:
- 收集和展示数据资产的元数据,包括数据源、数据类型、创建者、更新时间等。
- 支持自动化元数据提取和更新,确保元数据的准确性和及时性。
- 血缘分析:
- 提供数据血缘信息,展示数据在不同表格和数据流之间的传递和转换过程。
- 帮助用户理解数据的来源和影响范围,支持数据治理和质量管理。
- 用户协作:
- 支持用户对数据资产进行注释、评分和标记,促进数据的共享和协作。
- 提供用户行为分析,帮助识别和推荐热门数据集和常用数据资产。
- 可扩展性和集成:
- Amundsen提供可扩展的架构,支持与多种数据源和工具的集成。
- 用户可以开发自定义连接器和插件,满足特定的集成需求。
优势
- 用户友好:直观的界面和强大的搜索功能,提升用户的使用体验。
- 强大的元数据管理:自动化的元数据提取和更新,确保数据资产的准确性。
- 丰富的集成功能:支持多种数据源和工具,满足复杂的数据集成需求。
- 开放的社区支持:活跃的开源社区和持续的开发支持,提供丰富的资源和帮助。
应用场景
- 数据科学和分析:
- 帮助数据科学家和分析师快速找到和理解数据集,支持数据分析和建模。
- 提供数据资产的背景信息和使用建议,优化数据使用效率。
- 数据治理和管理:
- 支持数据治理团队管理和监控数据资产,确保数据的质量和合规性。
- 提供数据血缘和影响分析,支持数据的生命周期管理。
- 业务智能和报告:
- 帮助业务用户找到相关的数据和指标,支持报表和仪表板的创建。
- 提供数据资产的上下文信息,增强业务决策的准确性。
- 数据工程和开发:
- 支持数据工程师管理和优化数据管道,确保数据流的高效性和可靠性。
- 提供数据依赖和影响分析,支持数据管道的维护和优化。
Amundsen的架构
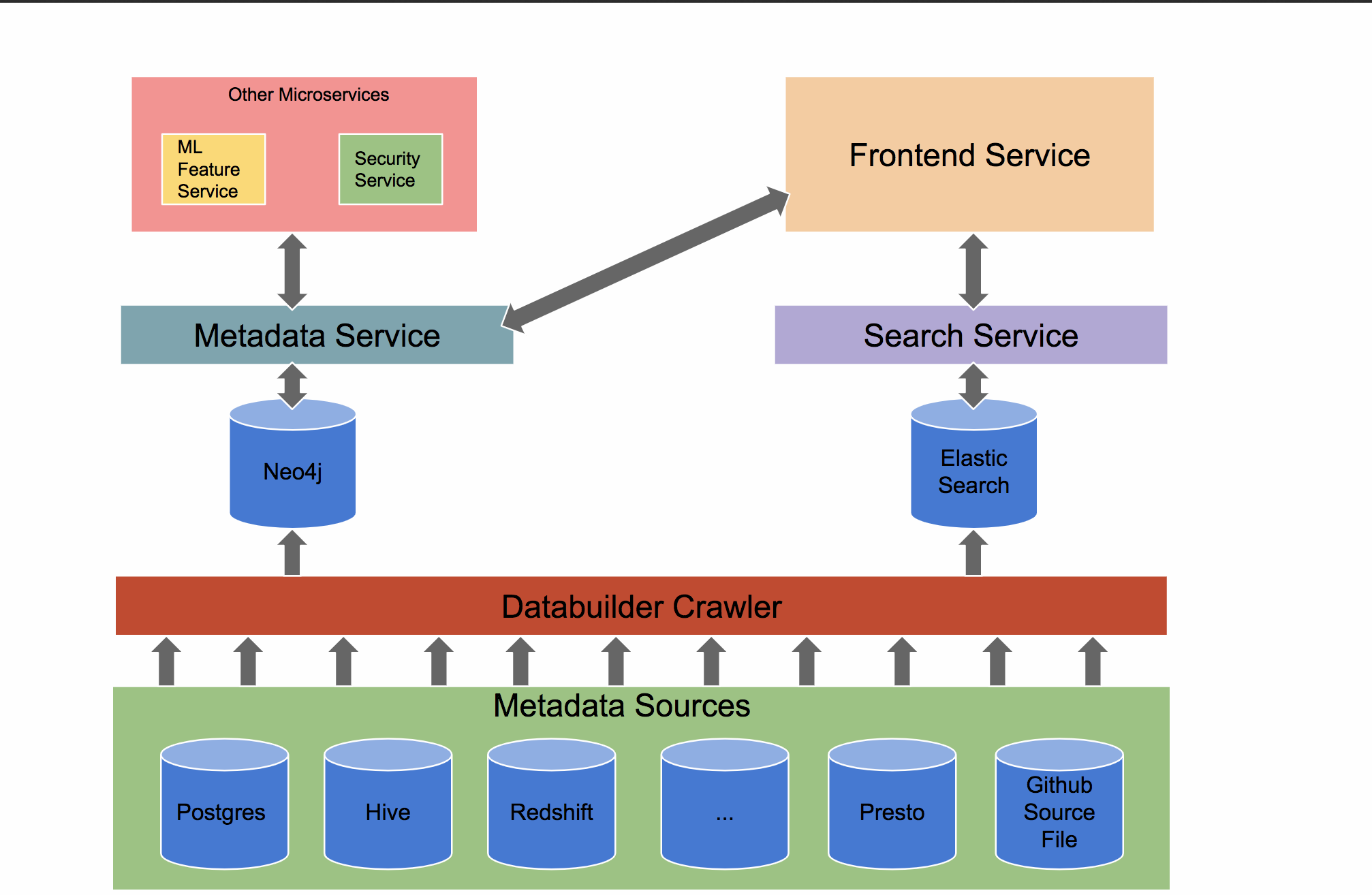
主要组件
- MetadataService(元数据服务)
- 功能:管理和存储数据资产的元数据,包括表、列、模式、用户、标签等。
- 实现:通常使用Neo4j图数据库来存储元数据,因其擅长处理复杂关系和连接。
- API:提供RESTful API,供其他组件查询和更新元数据。
- SearchService(搜索服务)
- 功能:提供对数据资产的搜索功能,使用户能够快速查找需要的数据。
- 实现:使用Elasticsearch来实现全文搜索功能,支持快速的索引和查询。
- API:提供搜索API,供前端应用调用。
- Frontend(前端)
- 功能:提供用户界面,供用户浏览和搜索数据资产。
- 技术栈:使用js构建,提供直观的用户体验。
- 功能模块:包括主页、搜索页、表详情页、用户详情页等,帮助用户轻松查找和理解数据。
- DataBuilder(数据构建器)
- 功能:从各种数据源中提取元数据,并将其加载到MetadataService中。
- 实现:通常通过定制化的脚本或使用开源的库,如 amundsendatabuilder,从数据库、数据仓库、ETL工具等提取元数据。
- 支持的数据源:支持多种数据源,包括Hive、Redshift、BigQuery、PostgreSQL等。
工作流程
- 元数据提取:
- DataBuilder从各种数据源中提取元数据。
- 提取的元数据通过批处理或流处理的方式加载到MetadataService中。
- 元数据存储:MetadataService使用Neo4j存储元数据,并维护数据资产之间的关系。
- 搜索索引:SearchService使用Elasticsearch为数据资产创建索引,以支持快速搜索。
- 用户交互:
- 用户通过前端界面与Amundsen交互,使用搜索功能查找数据资产。
- 前端调用MetadataService和SearchService的API获取和展示数据。
参考链接:


