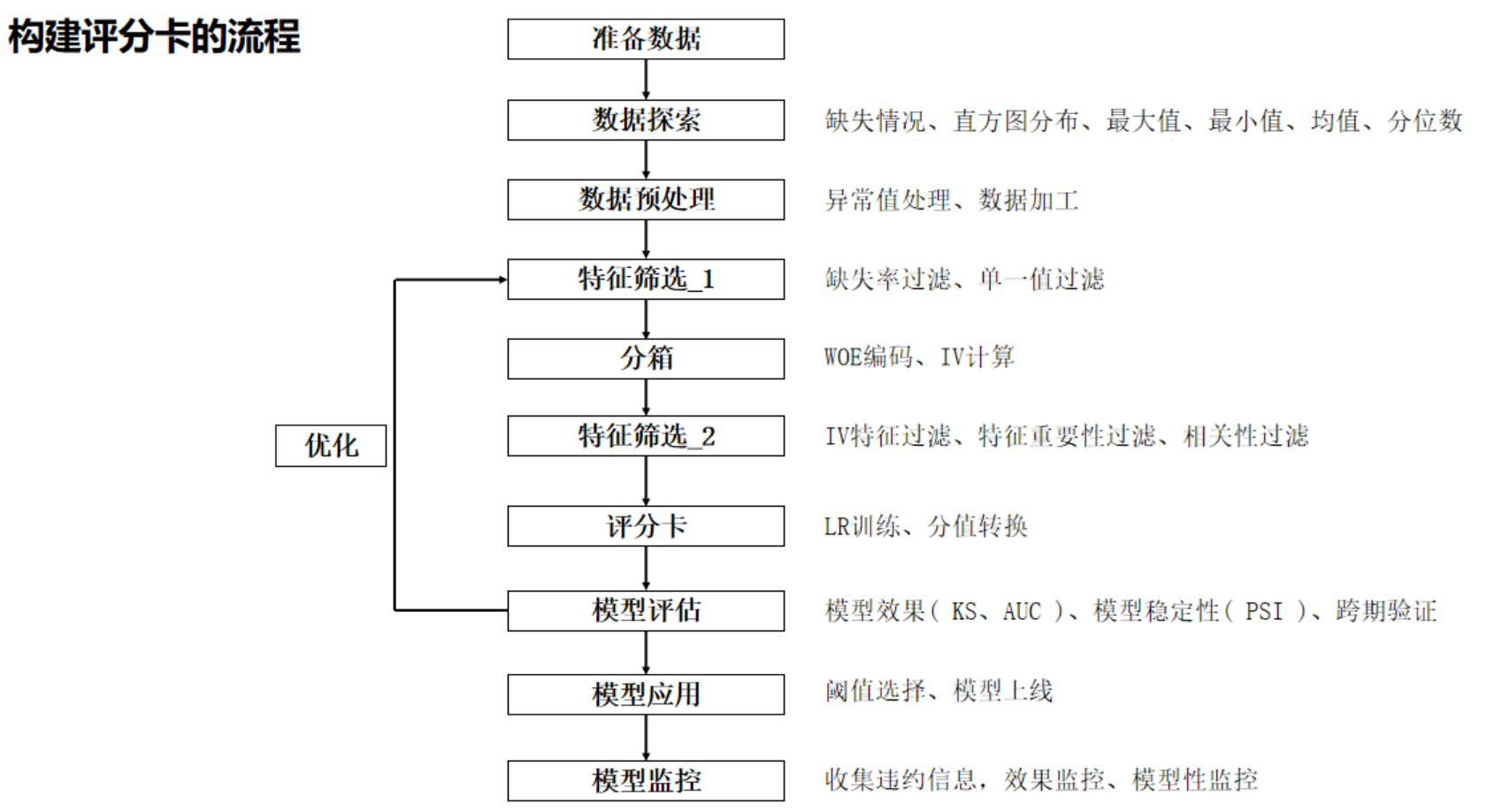
评分卡简介
评分卡模型(Scorecard Model)是一种用于预测个人或企业信用风险的统计模型。它主要应用于金融领域,尤其是在信贷风险评估中。该模型通过对用户的特征进行加权评分来评估其信用状况。

评分卡模型通常基于逻辑回归分析,以下是其主要特点:
- 变量选择:首先选择与目标变量(如信用违约风险)相关的特征变量,通常是客户的个人信息、信用历史、收入等。
- 特征转换:将每个特征变量转化为分数。通常使用分箱(binning)技术将连续型变量转化为离散型,并为每个箱分配一个分数。
- 模型构建:基于历史数据,使用统计方法(如逻辑回归)来估算每个特征对信用风险的影响程度,并计算对应的分数。
- 评分规则:根据每个特征的分数,得出一个综合评分。这个评分通常反映了客户的信用状况,分数越高表示信用越好。
- 风险分类:根据评分的高低,将客户划分为不同的信用风险等级(如优良、一般、差等)。
评分卡模型的一个典型例子是银行用来评估个人贷款申请者是否有足够的信用来批准贷款。具体可以查看先前的文章:风险控制:信用评分卡模型
Toad简介
toad 是针对风险评分卡的建模而开发的工具包,其功能全面,性能强大,从数据探索EDA、特征筛选、特征分箱、WOE变换,到建模、模型评估、转换分数,对评分卡模型的各个步骤都做了完整的封装,极大的简化了建模的复杂程度。
Toad的核心功能
- 数据预处理
- 缺失值处理:自动识别并填充缺失值,支持均值、中位数或特定值填充。
- 异常值检测:通过分位数或IQR方法识别异常值,并提供截断或缩尾处理。
- 数据分箱(Binning):
- 支持等频分箱、等距分箱、卡方分箱、决策树分箱等。
- 自动优化分箱边界,确保每箱的样本量合理。
- 特征分析与筛选
- IV值(Information Value)计算:评估变量的预测能力,IV>0.02的特征通常保留。
- WOE编码(Weight of Evidence):将分箱后的特征转换为WOE值,增强模型可解释性。
- 高相关性筛选:通过相关系数矩阵或VIF剔除冗余特征。
- 模型训练与评估
- 逻辑回归建模:Toad默认使用逻辑回归(可与其他模型结合),因其输出概率与评分卡天然契合。
- 模型评估指标:
- KS值:衡量模型区分好坏客户的能力(>0.3为佳)。
- AUC-ROC:评估整体排序能力。
- PSI(Population Stability Index):监控模型稳定性,PSI<0.1说明群体稳定。
- 评分卡生成
- 分数转换:将逻辑回归系数转化为直观的分数
- 自动生成评分表:输出每个特征的分数分配,便于业务解释。
与传统方法的对比
| 环节 | 传统方法 | Toad实现 |
| 分箱 | 手动调整,耗时易出错 | 自动化分箱,支持多种算法 |
| 特征筛选 | 基于IV和业务经验人工筛选 | 自动计算IV并剔除低价值特征 |
| 评分转换 | 手动推导公式,容易出错 | 一键生成评分卡 |
注意事项:
- 分箱合理性检查:需结合业务解释分箱结果,避免纯数据驱动导致不合理分段。
- 模型监控:定期通过PSI检测特征分布漂移,及时更新模型。
相关概念
分箱
在信用评分卡模型中,分箱(Binning) 是将连续变量或高基数类别变量划分为有限个离散区间的过程,是构建可解释、稳定性强模型的核心步骤。
分箱的核心目的
- 提升模型稳定性。将连续变量离散化,降低数据微小波动对模型的影响。
- 增强业务可解释性。将变量转化为与目标变量(如违约概率)呈现单调关系的区间。
- 处理非线性关系。捕捉变量与目标之间的非线性关联(如年龄与违约率的U型关系)。
- 适配评分卡要求。为后续计算WOE(Weight of Evidence) 和 IV(Information Value) 提供基础。
分箱的主要方法
- 无监督分箱
- 等宽分箱(Equal Width):按变量值范围均分(如年龄分为 [18-30], [30-40], [40-50])。
- 优点:简单易实现
- 缺点:对异常值敏感,可能导致空箱。
- 等频分箱(Equal Frequency):按样本量均分(如每箱含10%的样本)。
- 优点:规避异常值影响
- 缺点:边界可能出现不合理的业务跳跃。
- 有监督分箱
- 卡方分箱(Chi-square Merge):基于相邻区间的卡方统计量合并箱体,直至满足停止条件。
- 优点:自动优化分箱数量
- 缺点:可能生成非单调分箱。
- 决策树分箱(Optimal Binning):用决策树分裂点作为分箱边界(如使用CART算法)。
- 优点:最大化信息增益
- 缺点:可能过拟合训练数据。
- 业务导向分箱
- 根据业务经验手动定义分箱规则(如收入分为:低收入(<5k)、中收入(5k-20k)、高收入(>20k))。
- 优点:符合业务逻辑,易被业务方接受
- 缺点:依赖专家经验,可能损失统计信息。
- 根据业务经验手动定义分箱规则(如收入分为:低收入(<5k)、中收入(5k-20k)、高收入(>20k))。
- 卡方分箱(Chi-square Merge):基于相邻区间的卡方统计量合并箱体,直至满足停止条件。
- 等宽分箱(Equal Width):按变量值范围均分(如年龄分为 [18-30], [30-40], [40-50])。
分箱的关键评估指标
- WOE(Weight of Evidence)衡量每个分箱内正负样本分布的差异:$\text{WOE}_i = \ln ( \frac{\text{正样本占比}_i}{\text{负样本占比}_i})$,WOE值越大,该箱体正样本比例越高。
- IV(Information Value) 评估变量整体预测能力:$\text{IV} = \sum_{i=1}^{n} (\text{正样本占比}_i – \text{负样本占比}_i) \times \text{WOE}_i$
- 单调性检查,理想情况下,WOE值应随分箱单调变化(如年龄越大,WOE单调下降)。
分箱的注意事项
- 分箱数量
- 通常5-10箱,避免过少(信息损失)或过多(过拟合)。
- 高基数类别变量(如城市)可合并低频类别为”其他”。
- 特殊值处理
- 缺失值单独分箱(如-1 或 Missing)。
- 异常值单独分箱(如收入>100万的归为”超高收入”)。
- 跨时间一致性
- 生产环境需使用训练集分箱规则,避免PSI过高。
- 业务逻辑对齐
- 确保分箱与业务认知一致(如年龄分箱边界不跨生命周期阶段)。
分箱与模型性能的关系
- 过粗分箱:损失信息 → 模型区分度(KS/AUC)下降
- 过细分箱:引入噪声 → 模型稳定性(PSI)降低
- 最佳实践:在模型性能和稳定性间寻找平衡(通过交叉验证选择分箱数)。
附:TOAD分箱参数详解
| 参数 | 说明 |
| method | 分箱方法:’chi’(卡方)、’dt’(决策树)、’quantile’(等频) |
| min_samples | 每箱最小样本比例(默认0.05,即5%) |
| n_bins | 最大分箱数(默认5) |
| empty_separate | 是否将空值单独分箱(默认True) |
通过合理分箱,可构建出既符合统计规律又具备业务解释性的评分卡模型。
特征的IV值
特征的IV值(Information Value,信息价值) 是信用评分模型和特征选择中广泛使用的指标,用于衡量一个特征对目标变量(如是否违约)的预测能力。IV值越高,特征对目标的区分能力越强。
IV值的核心作用
- 筛选特征:IV值帮助判断哪些特征对目标变量有显著影响,通常保留IV值较高的特征。
- 量化预测能力:通过数值直观反映特征的预测效果,避免主观判断。
- 分箱优化依据:在分箱过程中,IV值可指导分箱策略(如合并低信息量的分箱)。
IV值的计算步骤
IV值的计算基于 WOE(Weight of Evidence,证据权重),需对特征进行分箱(离散化)。具体步骤:
Step 1: 计算每个分箱的WOE
$$\text{WOE}_i = \ln ( \frac{\text{好样本比例}_i}{\text{坏样本比例}_i}) = \ln ( \frac{(\text{好样本数}_i / \text{总好样本数})}{(\text{坏样本数}_i / \text{总坏样本数})})$$
Step 2: 计算每个分箱的IV
$$\text{IV}_i = (\text{好样本比例}_i – \text{坏样本比例}_i) \times \text{WOE}_i$$
Step 3: 汇总所有分箱的IV值
$$\text{总IV值} = \sum_{i=1}^{n} \text{IV}_i$$
IV值的解读标准
IV值的大小与预测能力的对应关系(常见经验阈值):
| IV值范围 | 预测能力 | 是否保留 |
| IV < 0.02 | 几乎无预测能力 | 剔除 |
| 0.02 ≤ IV < 0.1 | 预测能力较弱 | 谨慎保留 |
| 0.1 ≤ IV < 0.3 | 预测能力中等 | 优先保留 |
| IV ≥ 0.3 | 预测能力极强 | 保留并重点关注 |
注意事项
- 分箱敏感性:IV值高度依赖分箱方法(如卡方分箱、决策树分箱)。不同的分箱策略可能导致IV值差异较大,需结合业务理解优化分箱。
- 过拟合风险:高IV值可能是过拟合的信号(如分箱过细),需通过交叉验证或检验稳定性。
- 与其他指标结合:需综合缺失率、相关性、业务含义等筛选特征,而非仅依赖IV值。
KS统计量
KS统计量(Kolmogorov-Smirnov Statistic) 是信用评分模型和风险建模中广泛使用的核心指标,用于衡量模型对正负样本(如“好客户”和“坏客户”)的区分能力。它通过比较两个累积分布函数(CDF)的差异,反映模型预测结果的排序性能。
KS统计量的核心作用
- 评估模型区分能力:判断模型能否有效区分正负样本(例如违约与非违约客户)。
- 选择最优阈值:帮助确定最佳概率分界点(如将概率>0.5的客户判为高风险)。
- 监控模型稳定性:通过跟踪KS值变化,发现模型性能衰减(需结合PSI等其他指标)。
KS统计量的计算方法
Step 1: 按预测概率排序样本
将样本按模型预测的概率(如违约概率)从高到低排序。
Step 2: 计算正负样本的累积分布
负样本(如非违约)的累积分布:
$$CDF_{\text{bad}}(p) = \frac{\text{负样本中概率≤p的样本数}}{\text{总负样本数}}$$
正样本(如违约)的累积分布:
$$CDF_{\text{good}}(p) = \frac{\text{正样本中概率≤p的样本数}}{\text{总正样本数}}$$
Step 3: 计算KS值
$$\text{KS} = \max ( |CDF_{\text{good}}(p) – CDF_{\text{bad}}(p)|)$$
图示解释
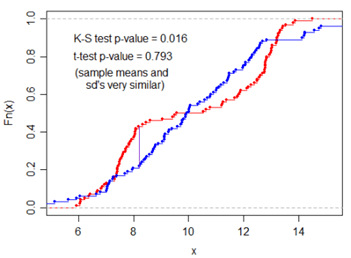
横轴为样本排序(从高风险到低风险),纵轴为累积占比。KS值为两条曲线的最大垂直距离。
KS值的解读标准
KS值的范围在0到1之间,值越大表示模型区分能力越强。经验判断标准如下:
| KS值范围 | 模型区分能力 | 业务建议 |
| KS < 0.2 | 区分能力弱 | 需优化模型或特征 |
| 0.2 ≤ KS < 0.3 | 区分能力一般 | 可接受,但建议改进 |
| 0.3 ≤ KS < 0.5 | 区分能力良好 | 满足大多数场景需求 |
| KS ≥ 0.5 | 区分能力极强 | 可能过拟合,需检查数据合理性 |
注意事项
- 过拟合风险:过高的KS值(如KS > 0.5)可能是模型过拟合的信号,需检查训练集与测试集分布差异(使用PSI指标)或特征工程合理性。
- 阈值选择:KS值对应的概率点即为最佳分界阈值,但实际业务中需权衡误判成本(如将高风险客户误判为低风险的损失)。
- 与AUC的关系:
- AUC衡量模型整体排序能力,与KS值正相关但视角不同。
- KS值更关注模型在最佳分界点附近的性能,适合需要明确分类的场景。
PSI指标
PSI(Population Stability Index,群体稳定性指标) 是信用评分模型和风控领域中用于评估两个群体(如训练集与测试集、不同时间段的样本)数据分布一致性的核心指标。它帮助判断模型输入特征或预测结果的稳定性,常用于监控模型在生产环境中的性能衰减。
PSI的核心作用
- 监控数据分布变化:检测特征或预测结果在时间维度上的分布偏移(如客群变化导致模型失效)。
- 评估模型稳定性:判断模型是否需要重新训练(如PSI过高时)。
- 业务场景应用:
- 模型上线前:验证训练集与上线样本的分布一致性。
- 模型运行中:定期(如月度)监控特征和评分卡的稳定性。
PSI的计算方法
PSI通过比较 实际分布(Actual) 与 预期分布(Expected) 的差异计算得出,步骤如下:
Step 1: 数据分箱
对连续变量或评分结果进行分箱(通常10-20箱),分箱方法包括:
- 等宽分箱:按值范围等分(如0-100分、100-200分)。
- 等频分箱:按样本量等分(如每箱包含10%的样本)。
Step 2: 计算每个分箱的占比
- 预期分布占比:参考群体(如训练集)在第i箱的样本占比$E_i$ 。
- 实际分布占比:监控群体(如测试集)在第i箱的样本占比$A_i$ 。
Step 3: 计算每个分箱的PSI分量
$$\text{PSI}_i = (A_i – E_i) \times \ln\left( \frac{A_i}{E_i} \right)$$
Step 4: 汇总所有分箱的PSI值
$$\text{总PSI} = \sum_{i=1}^{n} \text{PSI}_i$$
PSI的解读标准
PSI值越小,分布越稳定。经验阈值如下(需结合业务调整):
| PSI范围 | 分布稳定性 | 业务建议 |
| PSI < 0.1 | 分布稳定 | 无需处理 |
| 0.1 ≤ PSI < 0.25 | 分布轻微变化 | 持续监控,分析原因 |
| PSI ≥ 0.25 | 分布显著偏移 | 需排查数据问题或触发模型重训练 |
注意事项
- 分箱敏感性:PSI对分箱数量和方式敏感。建议:
- 评分卡模型使用训练时的分箱规则(如transform.Combiner的分箱结果)。
- 避免分箱过少(<5)导致信息丢失,或过多(>20)引入噪声。
- 变量类型差异:
- 连续变量:优先等频分箱。
- 类别变量:直接按类别计算占比,无需分箱。
- 与CSI的区别:
- PSI:评估整体分布变化。
- CSI(Characteristic Stability Index):评估单个特征对目标变量关系的变化(需结合IV值监控)。
- 业务优先级:高PSI的特征需优先检查:
- 数据采集错误(如字段定义变更)。
- 客群结构变化(如新产品上线吸引不同人群)。
Toad的使用
TOAD 是一个基于 Python 的评分卡建模工具库,专注于信用评分模型的开发,提供特征分箱、特征筛选、WOE转换、模型评估等功能。以下是其核心 API 接口及使用方法的详细说明:
数据预处理模块
toad.detect(data)
功能: 检测数据质量,输出缺失率、唯一值数等统计信息。
参数:
- data: DataFrame,输入数据
- 返回值: DataFrame,各列的统计信息
示例:
import toad
data = pd.read_csv('data.csv')
desc = toad.detect(data)
toad.quality(data, target=’target’, iv_only=False)
功能: 计算特征的IV值(Information Value),评估特征预测能力。
参数:
- target: 目标变量名
- iv_only: 是否仅返回IV值
返回值: DataFrame,包含IV、缺失率、唯一值等指标
示例:
quality = toad.quality(data, target='bad', iv_only=True)
分箱处理模块
toad.transform.Combiner
功能: 对特征进行分箱(离散化),支持卡方分箱、决策树分箱等方法。
核心方法:
- fit(data, y=None, method=’chi’, min_samples=0.05, n_bins=5)
- method: 分箱方法(’chi’, ‘dt’, ‘quantile’, ‘step’)
- min_samples: 最小样本占比
- n_bins: 最大分箱数
- transform(data): 应用分箱规则
示例:
from toad.transform import Combiner combiner = Combiner() combiner.fit(data, target='bad', method='chi', min_samples=0.1) binned_data = combiner.transform(data)
toad.transform.WOETransformer
功能: 将分箱后的特征转换为WOE值。
方法:
- fit(data, target): 计算各箱的WOE值
- transform(data): 应用WOE转换
示例:
from toad.transform import WOETransformer woe = WOETransformer() woe.fit(binned_data, data['bad']) woe_data = woe.transform(binned_data)
特征选择模块
toad.selection.select(data, target=’target, empty=0.9, iv=0.02, corr=0.7)`
功能: 基于缺失率、IV值、相关性筛选特征。
参数:
- empty: 缺失率阈值
- iv: IV值阈值
- corr: 特征间相关性阈值
返回值: 筛选后的特征列表
示例:
selected_features = toad.selection.select(data, target='bad', iv=0.02)
模型训练与评估
toad.Classifier
功能: 封装逻辑回归模型,支持自动处理共线性。
方法:
- fit(X, y): 训练模型
- predict_proba(X): 输出概率
示例:
from toad.linear_model import LRClassifier model = LRClassifier() model.fit(woe_data[selected_features], data['bad'])
toad.metrics.KS
功能: 计算KS统计量。
示例:
proba = model.predict_proba(test_data) ks = toad.metrics.KS(proba, test_data['bad'])
评分卡生成
toad.ScoreCard
功能: 将逻辑回归系数转换为评分卡。
参数:
- combiner: 分箱规则
- transformer: WOE转换规则
- base_score: 基准分
- base_odds: 基准odds
- pdo: 分值翻倍odds
示例:
card = toad.ScoreCard(
combiner=combiner,
transer=woe,
base_score=600,
base_odds=35,
pdo=50,
)
card.fit(X_train, y_train)
scores = card.predict(X_test)
Toad实战
以下是一份基于 Kaggle公开数据集 的完整 toad 使用教程,涵盖 数据预处理、特征筛选、模型训练、评估与监控 全流程。本教程以信用评分场景为例,使用 Kaggle 的 “Give Me Some Credit” 数据集(预测客户未来两年内陷入财务困境的概率)。
环境准备
安装依赖库
!pip install toad pandas scikit-learn matplotlib
下载数据集
从 Kaggle 下载以下两个文件到本地目录 data/:
- cs-training.csv(训练集,含标签)
- cs-test.csv(测试集,无标签,用于模拟生产环境数据)
完整代码
import toad
import pandas as pd
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# =========================================================================
# 1. 数据加载与探索
# =========================================================================
# 加载训练集
data = pd.read_csv('data/cs-training.csv', index_col=0)
print("数据维度:", data.shape)
print("前5行数据:\n", data.head())
# 查看数据概况(缺失值、唯一值、数据类型)
toad.detect(data).head(10)
# =========================================================================
# 2. 数据预处理
# =========================================================================
# 重命名列(原始列名含特殊字符)
data.columns = [
'SeriousDlqin2yrs', 'RevolvingUtilization', 'Age',
'PastDue30-59Days', 'DebtRatio', 'MonthlyIncome',
'OpenLoans', 'PastDue90Days', 'RealEstateLoans',
'PastDue60-89Days', 'Dependents'
]
# 划分训练集与验证集
train, val = train_test_split(data, test_size=0.3, random_state=42)
# 处理缺失值
train_clean = toad.cleaner.drop_missing(train, threshold=0.5) # 删除缺失率>50%的列
print("处理后保留的列:", train_clean.columns.tolist())
# =========================================================================
# 3. 分箱与WOE转换
# =========================================================================
# 自动分箱(指定目标列和需要分箱的列)
combiner = toad.transform.Combiner()
combiner.fit(
train_clean,
y='SeriousDlqin2yrs',
method='chi', # 使用卡方分箱
min_samples=0.05, # 每箱至少5%样本
empty_separate=True # 空值单独分箱
)
# 查看分箱结果
print("Age分箱边界:", combiner.export()['Age'])
# 可视化分箱
adj_bin = {'Age': [20, 30, 40, 50, 60, 70]} # 可手动调整分箱
combiner.set_rules(adj_bin)
toad.plot.bin_plot(train_clean, x='Age', target='SeriousDlqin2yrs')
# 应用WOE转换
transformer = toad.transform.WOETransformer()
train_woe = transformer.fit_transform(
combiner.transform(train_clean),
train_clean['SeriousDlqin2yrs'],
exclude=['SeriousDlqin2yrs']
)
# =========================================================================
# 4. 特征筛选(IV值)
# =========================================================================
# 计算IV值
iv_df = toad.quality(train_clean, target='SeriousDlqin2yrs', iv_only=True)
print("特征IV值:\n", iv_df)
# 筛选IV>=0.02的特征
selected_features = iv_df[iv_df['iv'] >= 0.02].index.tolist()
print("筛选后的特征:", selected_features)
# =========================================================================
# 5. 模型训练
# =========================================================================
from toad.linear_model import LRClassifier
# 初始化模型(自动处理共线性)
model = LRClassifier()
model.fit(train_woe[selected_features], train_woe['SeriousDlqin2yrs'])
# =========================================================================
# 6. 模型评估(KS/AUC)
# =========================================================================
# 对验证集进行相同预处理
val_clean = combiner.transform(val)
val_woe = transformer.transform(val_clean)
# 预测概率
val_proba = model.predict_proba(val_woe[selected_features])[:, 1]
# 计算KS值
ks = toad.metrics.KS(val_proba, val_woe['SeriousDlqin2yrs'])
print(f"验证集KS值 = {ks:.3f}")
# 计算AUC
from sklearn.metrics import roc_auc_score
auc = roc_auc_score(val_woe['SeriousDlqin2yrs'], val_proba)
print(f"验证集AUC = {auc:.3f}")
# =========================================================================
# 7. 模型监控(PSI)
# =========================================================================
# 加载模拟生产环境数据(假设是新时间段的数据)
prod = pd.read_csv('data/cs-test.csv', index_col=0)
prod.columns = train_clean.columns # 重命名列
# 预处理生产数据
prod_clean = combiner.transform(prod)
prod_woe = transformer.transform(prod_clean)
# 计算模型评分的PSI
train_score = model.predict_proba(train_woe[selected_features])[:, 1]
prod_score = model.predict_proba(prod_woe[selected_features])[:, 1]
psi = toad.metrics.PSI(train_score, prod_score)
print(f"模型评分PSI = {psi:.3f}")
# 检查特征PSI(以MonthlyIncome为例)
psi_income = toad.metrics.PSI(
train_clean['MonthlyIncome'],
prod_clean['MonthlyIncome']
)
print(f"特征MonthlyIncome的PSI = {psi_income:.3f}")
# =========================================================================
# 8. 模型部署(生成评分卡)
# =========================================================================
# 输出模型系数
coef_df = pd.DataFrame({
'feature': selected_features,
'coefficient': model.coef_[0]
})
print("模型系数:\n", coef_df)
# 保存分箱规则与WOE转换器
import joblib
joblib.dump(combiner, 'model/combiner.pkl')
joblib.dump(transformer, 'model/transformer.pkl')
参考链接:


