文章内容如有错误或排版问题,请提交反馈,非常感谢!
常用相关性分析存在的问题
1、有许多非线性的关系是分数根本无法检测到的,比如下图:
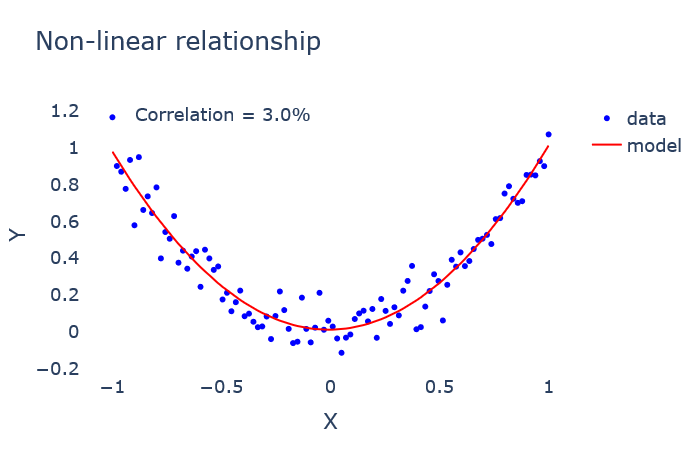
2、计算出来的矩阵是对称的,即a与b的相关性同b与a的相同。更多的时候,关系是不对称的。一个有3个唯一值的列永远不可能完美地预测另一个有100个唯一值的列。但事实可能恰恰相反。显然,不对称很重要,因为它在现实世界中非常普遍。
Predictive Power Score (PPS)的实现逻辑
假设我们有两个列,想要计算a预测b的预测能力得分。在这种情况下,我们将b视为目标变量,将a视为(唯一)特性。我们现在可以计算一个交叉验证的决策树,并计算一个合适的评估度量。当目标是数值时,我们可以使用决策树回归模型计算平均绝对误差(MAE)。当目标是分类的,我们可以使用一个决策树分类器,并计算加权F1。你也可以使用其他的分数,比如ROC等。
PPS使用示例(Python)
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import ppscore as pps
df = pd.read_excel("data/train.xlsx")
plt.figure(figsize=(15,13))
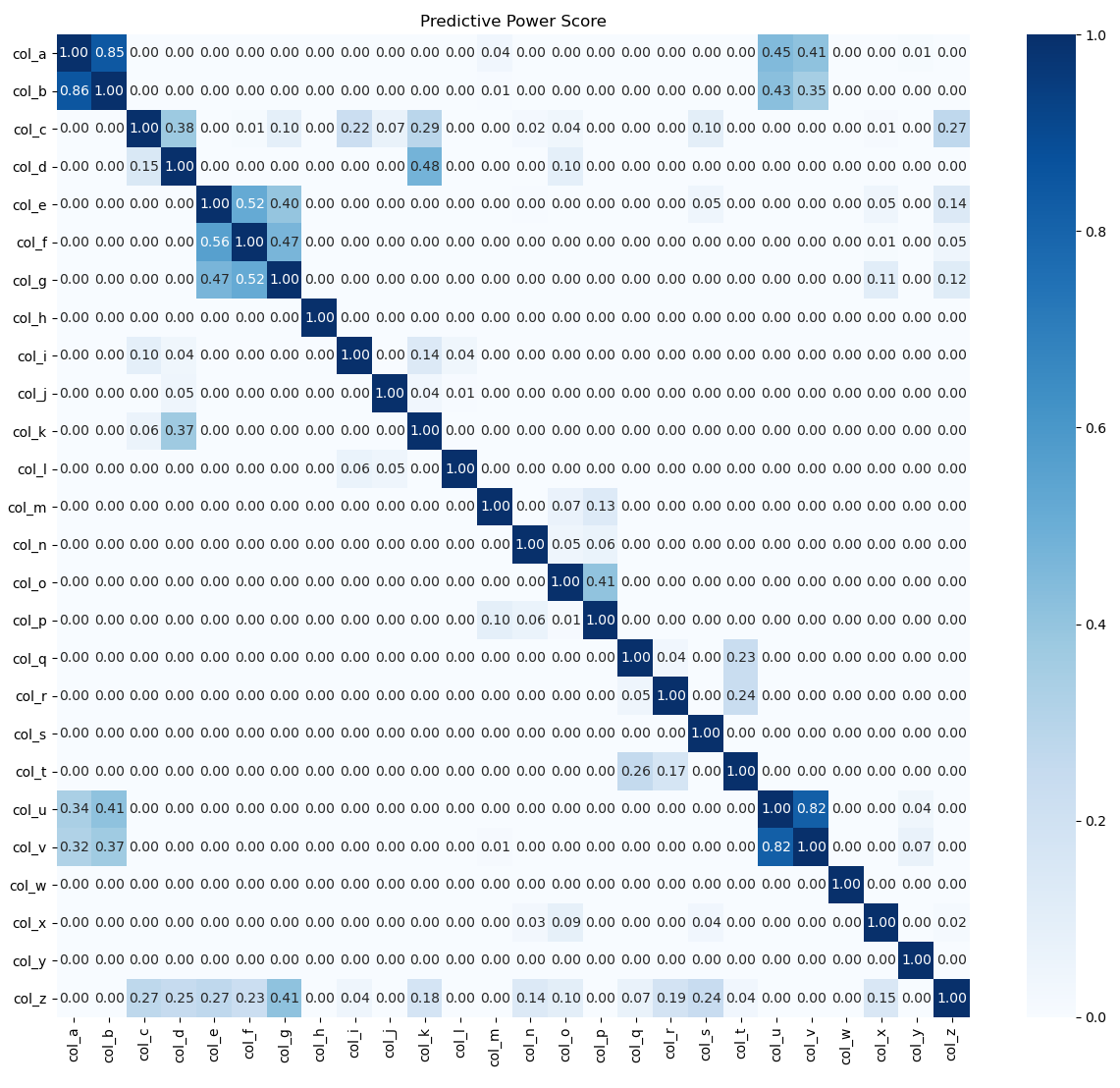
sns.heatmap(pps.matrix(df), annot=True, vmin=0, vmax=1, cmap='Blues', fmt=".2f")
plt.title("Predictive Power Score")
plt.savefig('corr_pps.png')
执行结果:
参考链接:


