Luigi简介
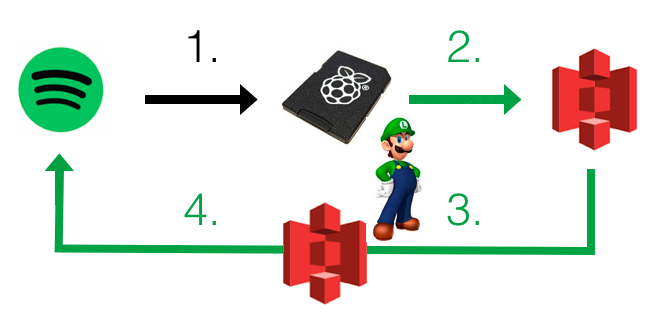
Luigi是一个由Spotify开发的开源Python模块,旨在简化复杂数据管道的构建、管理和调度。它专注于数据流的自动化和任务依赖的管理,非常适合处理大规模数据处理任务。
核心概念
- 任务(Task):Luigi的基本构建块是任务。每个任务通常代表数据处理管道中的一个步骤。任务可以是运行SQL查询、处理数据文件、训练机器学习模型等。
- 依赖管理:Luigi通过定义任务之间的依赖关系来管理复杂的工作流。任务可以声明它们依赖于哪些其他任务,Luigi会确保在运行当前任务之前,所有依赖任务都已成功完成。
- 目标(Target):目标是任务的输出,通常是文件或数据库表。Luigi使用目标来检查任务是否已完成,并决定是否需要重新运行任务。
- 调度器(Scheduler):Luigi包含一个中央调度器,负责协调任务的执行。调度器跟踪任务的状态和依赖关系,并调度任务的运行。
特点
- 简洁的代码结构:Luigi使用Python编写,任务和工作流的定义使用简单的Python类和函数。这使得开发人员可以轻松定义和管理复杂的工作流。
- 自动化的错误处理和重试机制:如果任务失败,Luigi可以自动重试任务,并在问题解决后重新调度未完成的任务。
- 可视化和监控:Luigi提供一个简单的Web界面,用户可以通过该界面查看工作流的执行状态、任务的依赖关系和日志信息。
- 扩展性:Luigi具有良好的扩展性,用户可以通过编写自定义任务和目标来扩展其功能。
- 广泛的应用集成:Luigi可以与多种数据存储和处理系统集成,如Hadoop、Spark、PostgreSQL、MySQL、AWS S3等。
适用场景
- 数据工程:适合处理复杂的数据管道,涉及多个步骤的数据清洗、转换和加载(ETL)任务。
- 机器学习工作流:可用于管理和调度机器学习模型的训练、评估和部署工作流。
- 报表生成和数据分析:自动化生成定期报告和数据分析任务,确保数据的及时性和准确性。
限制
- 水平扩展能力有限:Luigi的调度器设计适合中小规模的工作流,对于需要高并发和大规模集群的场景,可能需要结合其他工具或进行定制化开发。
- 实时处理能力不足:Luigi更适合批处理任务,而非实时流式数据处理。
总的来说,Luigi是一个强大而灵活的工具,特别适合数据工程和分析团队用来管理复杂的数据处理工作流。其简单的Python API和自动化的任务管理功能,使得开发人员能够专注于数据处理逻辑,而无需担心底层的调度和依赖管理。
与AirFlow的对比
Luigi和Apache Airflow是两种流行的开源工作流调度和管理工具,广泛用于数据工程和数据科学任务。尽管它们在功能上有一些重叠,但在设计理念、功能特性和适用场景上存在一些区别。以下是Luigi和Airflow的对比:
| 特性/方面 | Luigi | Apache Airflow |
| 开发背景 | 由Spotify开发,专注于批处理数据管道 | 由Airbnb开发,广泛用于各种工作流管理 |
| 核心概念 | 基于任务树和目标(Target)来管理任务和依赖关系 | 基于DAG(有向无环图)来定义任务及其依赖关系 |
| 用户界面 | 提供简单的Web界面,功能基础 | 提供功能丰富的Web界面,支持任务的图形化展示和实时监控 |
| 调度能力 | 基本的调度功能,适合中小规模的工作流 | 强大的调度功能,支持复杂调度策略和大规模任务并发执行 |
| 扩展性 | 支持基本扩展,需要更多自定义开发 | 广泛的集成支持和插件机制,易于扩展和集成其他系统 |
| 社区和支持 | 社区规模较小,活跃度相对较低 | Apache基金会顶级项目,拥有活跃的社区和广泛的支持 |
| 适用场景 | 简单的批处理数据管道,直接依赖管理 | 复杂工作流和调度需求,企业级工作流管理 |
| 集成能力 | 支持与Hadoop、Spark、SQL数据库、AWS S3等集成 | 支持与各种数据库、云服务、大数据框架的广泛集成 |
| 错误处理 | 自动化的错误处理和重试机制 | 提供详细的错误处理机制和任务重试策略 |
| 任务定义 | 使用Python类和函数定义,任务以任务树形式组织 | 使用Python定义DAG和任务,支持复杂依赖和调度配置 |
选择Luigi或Airflow通常取决于具体的需求和环境。Luigi适合需要快速搭建简单数据管道的场景,而Airflow则提供了更丰富的功能和扩展性,适合复杂的企业级工作流管理。对于需要广泛集成和复杂调度的场景,Airflow通常是更好的选择。
Luigi的使用
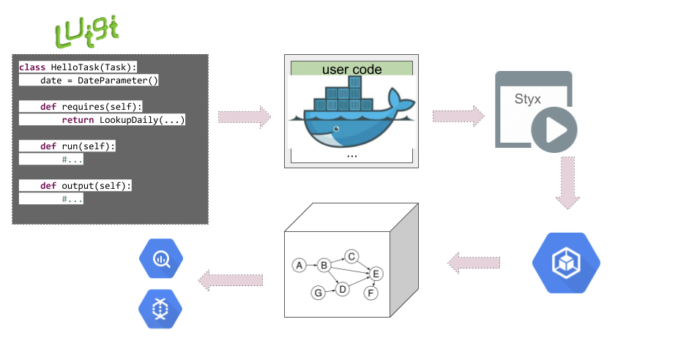
使用Luigi来管理和调度工作流通常涉及几个关键步骤,从安装到定义任务,再到运行和监控工作流。
安装Luigi
Luigi是一个Python模块,可以通过Python的包管理工具pip安装:pip install luigi定义任务
在Luigi中,任务是通过继承luigi.Task类来定义的。每个任务需要实现以下几个方法:
- requires(self): 定义当前任务的依赖任务。
- output(self): 定义任务的输出,通常是一个文件或数据库记录。
- run(self): 定义任务的具体逻辑。
以下是一个简单的任务示例:
import luigi
import random
class GenerateRandomNumber(luigi.Task):
def output(self):
return luigi.LocalTarget('random_number.txt')
def run(self):
with self.output().open('w') as f:
f.write(str(random.randint(1, 100)))
class PrintRandomNumber(luigi.Task):
def requires(self):
return GenerateRandomNumber()
def output(self):
return luigi.LocalTarget('printed_number.txt')
def run(self):
with self.input().open('r') as infile, self.output().open('w') as outfile:
number = infile.read()
print(f"The generated random number is: {number}")
outfile.write(number)
if __name__ == '__main__':
luigi.run()
运行任务
要运行Luigi任务,可以使用命令行工具。确保在脚本中包含 if __name__ == ‘__main__’: luigi.run() 这一行,以便通过命令行调用Luigi任务。
运行命令:
python your_script.py PrintRandomNumber --local-scheduler
–local-scheduler 参数表示使用本地调度器,而不是Luigi的中央调度器。
监控任务
Luigi提供了一个简单的Web界面来监控任务的执行状态。要启动Luigi的Web服务器,可以运行:
luigid
然后在浏览器中访问 http://localhost:8082 查看任务的状态和日志信息。
组织复杂工作流
在实际应用中,Luigi可以用来组织更复杂的工作流,通过定义多个任务和它们之间的依赖关系。任务可以被组合成复杂的任务树,每个任务可以有多个输入和输出。
使用外部系统
Luigi提供了多种内置的任务和目标类型,支持与外部系统的集成,如Hadoop、Spark、SQL数据库、AWS S3等。用户也可以通过继承 luigi.Task 类来定义自定义任务,以满足特定需求。
参考链接:
- spotify/luigi: Luigi is a Python module that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization etc. It also comes with Hadoop support built in. (github.com)
- Why We Switched Our Data Orchestration Service – Spotify Engineering: Spotify Engineering (atspotify.com)


