前面我们学习了腾讯Item-based CF实时推荐算法,这篇文章延续同样来自腾讯,介绍的是腾讯实时视频推荐系统的实践。内容来自论文: Real-time Video Recommendation Exploration 这篇论文中的内容。
简介
传统的技术对于大规模视频数据的实时处理、准确性和可扩展性都有一定的限制。针对目前推荐系统存在的不足,腾讯视频推荐系统中为用户提供实时、准确推荐的一些新技术。我们开发了一种基于矩阵分解的可扩展在线协同过滤算法,该算法考虑了不同用户行为的隐式反馈解决方案,具有可调整的更新策略。为了选择高质量的候选视频进行实时Top-N推荐生成利用视频类型和时间因素等附加因素来计算类似视频。此外,我们还提出了我们的算法的可扩展实现,以及一些优化,以使建议更有效和准确,包括人口统计过滤和人口统计。为了验证模型的有效性和有效性,通过从腾讯视频中采集真实数据进行了全面的实验。此外,此视频推荐系统正运行在生产环境中,为腾讯视频提供推荐服务,并验证其优越性。
CF最成功的技术之一是矩阵分解(MF),基于MF的CF由于其对用户视频协作矩阵的稀疏性具有鲁棒性而变得越来越流行。然而,由于矩阵分解模型的更新训练成本高,不适用于大规模数据的快速变化趋势。一些在线学习算法通过将数据集的一个代表性样本保存在一个库中以对模型进行再培训来解决这个问题,但这并不适用于大型流数据集。为了避免这个问题,其他一些在线算法建议只在当前观察的基础上更新模型,以降低推荐的质量为代价。此外,MF最方便的数据是高质量的显式反馈。不幸的是,目前腾讯视频等在线视频系统中大量的数据都是隐性反馈,这意味着我们只能根据用户的行为来猜测他们的偏好。隐性反馈对腾讯视频的有效推荐提出了额外的挑战。
腾讯视频推荐目标
- 首先,推荐系统需要为用户提供准确的推荐。
- 其次,应该实时更新模型,以在很短的延迟(秒)内捕获用户的即时兴趣
- 第三,处理需要并行执行,即可扩展以处理大量计算。
为了实现上述目标,腾讯提出了一个实时的Top-N视频推荐系统。开发了一个实时的基于中频的CF算法,采用在线更新策略,在线更新策略考虑了不同隐式反馈数据实例的置信水平,其中训练过程中的学习率可根据每个数据实例进行调整。为了实时生成前N个推荐,构建了类似的视频表,选择高质量的候选视频进行推荐,这些视频记录了每个视频的最相关视频。除了MF的结果外,还利用其他因素,包括视频类型和时间因素来计算视频的相似性。
针对隐性反馈的在线可调整的矩阵分解
基本矩阵分解
我们将用户u对i项的评级表示为$r_{ui}$,这表示用户u对i项的偏好。较高的$r_{ui}$值意味着更强的偏好,而MF的目标是预测未知的评级。预测是通过一个内积来完成的,即$\hat{r}_{ui}=x_{u}^{T}y_{i}$。
MF的主要挑战是计算每个用户和项目到因子向量$x_{u},y_{i}\in\mathbb{R}^{f}$的映射。为了学习因子向量($x_u$和$y_i$),通过最小化已知评级集上的L2误差来进行训练:
$$\min_{x_{*},y_{*}}\sum_{(u,i)\in D}\left(r_{ui}-x_{u}^{T}y_{i}\right)^{2}+\lambda\left(\left\|x_{u}\right\|^{2}+\left\|y_{i}\right\|^{2}\right)$$
其中D是已知$r_{ui}$的一组用户项对,即训练集,$\lambda$是用于控制正则化程度的参数。正则化项$\lambda(\|x_{u}\|^{2}+\|y_{i}\|^{2})$用于避免过度拟合,且$\lambda$的值与数据有关,通常由实验确定。
上述公式试图捕获用户与产生不同评级值的项之间的交互,然而,评级值中观察到的大部分变化与相互作用无关,但受到与用户或项目相关的影响(称为偏差或截距)的影响。例如,一些用户倾向于给予比其他用户更高的评级,并且一些用户倾向于获得比其他用户更高的评级。考虑到偏差效应,我们将评级$r_{ui}$的预测扩展如下:
$$\hat{r}_{ui}=\mu+b_{u}+b_{i}+x_{u}^{T}y_{i}$$
其中$\mu$表示总体平均评级,参数$b_u$和$b_i$分别表示观察到的用户u和项目i与平均值的偏差。因此,观察到的评级分为四个部分:全局平均值,项目偏差,用户偏差和用户项目交互。然后,目标函数可扩展到:
$$\min_{x_{*},y_{*},b_{*}} \sum_{(u,i)\in D}(r_{ui}-\mu-b_{u}-b_{i}-x_{u}^{T}y_{i})^{2}+\lambda(\|x_{u}\|^{2}+\|y_{i}\|^{2}+b_{u}^{2}+b_{i}^{2})$$
解决MF优化问题最成功的方法是交替最小二乘法(ALS)和随机梯度下降(SGD)。基于SGD的优化在使用稀疏数据时通常比ALS表现更好。在模型精度和运行时效率方面。给定由<user, item, rating>形式的元组组成的训练数据集,SGD执行几次遍历数据集,直到满足一些停止标准,这通常是收敛边界或最大迭代次数。在每次迭代中,SGD扫过训练集中的所有已知评级。对于每个评级,SGD通过在误差梯度的反方向上校正它们来更新参数。校正程度由因子$\eta<=1$确定,称为学习速率的步长。基于等式,评级$r_{ui}$的相关预测误差计算如下:
$$e_{ui}=r_{ui}-\mu-b_{u}-b_{i}-x_{u}^{T}y_{i}$$
更新操作执行如下:
$$\begin{array}{c}{b_{u}\leftarrow b_{u}+\eta\left(e_{ui}-\lambda b_{u}\right)}\\{b_{i}\leftarrow b_{i}+\eta\left(e_{ui}-\lambda b_{i}\right)}\\{x_{u}\leftarrow x_{u}+\eta\left(e_{ui}x_{u}-\lambda x_{u}\right)}\\{y_{i}\leftarrow y_{i}+\eta\left(e_{ui}y_{i}-\lambda y_{i}\right)}\end{array}$$
隐式反馈解决方案
用于矩阵分解的最方便的数据是高质量的显式反馈,即用户关于他们对产品的兴趣的显式输入,例如星级评级,赞或踩。但是,在实际情况中并不总是可以获得明确的反馈。实际上,大多数丰富数据是隐式反馈,即间接反映用户意见的用户行为。由于我们只能根据用户行为猜测用户的偏好,如果处理不当,隐式反馈可能会降低推荐系统的性能。
腾讯视频中有各种类型的用户行为,包括点击,观看,评论等。我们可以使用的数据非常嘈杂,因为它间接地体现了用户的参与度和幸福感。例如,用户完整地观看视频的事实不足以得出他实际上喜欢它的结论,而用户可能由于时间限制而在短时间内观看喜爱的视频。基于不同用户动作表示不同程度的用户兴趣的直觉,腾讯为用户的各种动作类型设置适当的权重。例如,点击行为可能对应于一星评级,而评论行为等于三星评级。各种用户动作的权重由根据应用程序中的现实世界条件的经验确定。下表展示了在腾讯视频中的设置:
 其中,Impress 表示用户看到了展示的视频,Click 表示用户点击了视频,Play 表示用户播放了视频,PlayTime 则是根据用户播放的时常确定的值。特别是,用户的 PlayTime 动作,通过用户看到的进度设置的权重如下:
其中,Impress 表示用户看到了展示的视频,Click 表示用户点击了视频,Play 表示用户播放了视频,PlayTime 则是根据用户播放的时常确定的值。特别是,用户的 PlayTime 动作,通过用户看到的进度设置的权重如下:
$$w_{ui}=a+b\log(\text{vrate}_{ui})\quad(a\geq b,1\geq\text{vrate}_{ui}\geq0.1)$$
其中 $vrate_{ui}=t_{ui}/t_{i}$,$t_{ui}$ 是用户的观看时间,$t_i$ 表示视频的全长。
这里观看率而不是用户绝对观看时间来消除各种类型的视频的时间长度的变化。为了减少由于各种凌乱的隐式反馈引起的噪音,限制 rate$_{ui}\geq0.1$。换句话说,将 vrate$_{ui}<0.1$ 的 PlayTime 动作视为低效的,我们将其权重设置为与 Play 动作相同。由于很难根据停止观 看动作来推断用户的真实偏好,因此考虑到推荐的多样性,产生负面反馈是不明智的。实际上,腾讯也测试了 $w_{ui}=a+b*$vrate$_{ui}$,结果表明上面的公式有更好的表现。 为了训练 MF 模型,我们需要 $r_{ui}$ 值来表示用户 u 对视频 i 的偏好。对于隐式反馈,一种自然的方法是将用户操作的权重视为相应的评级,即 $r_{ui}=w_{ui}$。然而,尽管它在基于项目的 CF 中运行良好,但在 MF 模型中出现了严重的问题,主要原因是隐式反馈的不适当猜测所引起的噪声,因为 MF 对噪声数据敏感。因此,我们转向另一种方法。具体而言,将 r_{ui} 设置为二元变量,并将用户操作的权重 w_{ui} 表示为其测量的置信度: $$r_{ui}=\{\begin{array}{ll}{1}&{w_{ui}>0}\\{0}&{w_{ui}=0}\end{array}$$
简单地说,用户与视频 i 有交互($w_{ui}>0$)表示喜欢视频 i($r_{ui}=1$)。另一方面,如果用户从不与视频 i 互动,我们认为没有偏好($r_{ui}=0$)。此外,将其与置信水平相关联,即用户动作权重 $w_{ui}$,其将用于以下部分中的可调节在线更新策略。
可调整的在线更新策略
传统的矩阵分解(MF)以批处理模式进行训练,这需要多次通过或迭代数据集来训练模型。随着在这个快速变化的世界中时效性变得越来越重要,传统的训练方法不适用于连续生成评级的流数据。因此,腾讯提出了一种基于 SGD 的可调整在线更新策略的实时 MF 算法。
首先,实时视频推荐系统需要一个能够捕获用户最近活动并实时影响推荐结果的模型。为了处理无限数量的用户操作增加的大量流数据,我们需要一种不需要迭代数据集的增量更新策略。对于增量更新策略,每个用户操作仅处理一次,并且没有迭代可以确保模型收敛。实际上,由于用户动作以不可预测的速率连续生成,模型将一直更新,因此总是不会在流数据方面收敛,这对实时模型训练产生了额外的挑战。特别地,流数据条件中的模型应满足两个要求:能够产生令人满意的建议并且始终对新用户动作敏感。具体而言,首先,模型需要表示用户和视频的属性以预测准确的偏好。其次,新用户动作应该实时影响模型,即模型应该快速适应新的用户动作,而不是保持历史数据的局部最优状态。这两个要求在某种程度上倾向于发生冲突。
为了即时产生准确的推荐,模型应该适应当前的历史数据,但这会导致它对新的用户操作不敏感,这可能会降低未来的性能。一个有效的实时 MF 模型必须同时考虑这两个方面。在这种情况下,腾讯提出了一种可调节的增量 SGD 算法,该算法可以针对不同的用户动作实时更新 MF 模型到不同的范围。利用上一节中用户操作的置信度,并反映增量培训更新策略中用户操作的差异。一方面,对于具有低置信度的用户动作(更可能是噪声数据),我们减少它们对模型的影响,以避免过度拟合噪声数据或进入错误的优化方向,从而对新用户动作敏感。另一方面,具有高置信度的用户动作的影响增加,其更可能代表用户的真实偏好,使得模型可以表示用户和视频的属性,从而能够产生良好的性能。我们采用更新策略的学习率来控制对模型的影响,这与置信水平成正比。
具体而言,我们在一个步骤中更新每个新用户操作的模型,无需迭代。对于每个用户操作,其对模型的影响取决于其评级和置信度。我们仅在评级 $r_{ui}=1$ 时更新模型,即对用户的展示对模型没有影响。对于 $r_{ui}=1$ 的用户动作,置信度 $w_{ui}$ 越高,对模型训练过程的影响越大,即学习率越大。具体来说,根据其置信度更新不同用户操作的模型,如下所示:
$$\eta_{ui}=\eta_{0}+\alpha w_{ui}$$
其中 $\eta_{0}$ 是训练过程的基本学习率,$\alpha$ 是控制置信水平对学习率的影响的参数,这些参数是通过实验确定的。

以上为更新算法,由于在场景中使用流数据集并且用户评级操作以不可预测的速率生成,因此为简单起见,只显示一个用户评级操作的更新策略。对于每个用户评级操作,我们首先计算其偏好和执行度,$r_{ui}$ 和 $w_{ui}$。假设偏好为正($r_{ui}=1$),我们将根据用户评级动作的置信水平更新模型。每个用户操作都会实时影响模型,并立即影响推荐结果。对于新用户或新项目,首先在更新操作之前初始化其向量。使用基于分布式存储键值来存储 $x_u$ 和 $y_i$ 向量,将在下节中进行说明。
实时视频推荐
在本节中,将介绍从接收用户推荐请求到在我们的推荐系统中生成实时视频推荐的过程。此外,描述了生成高质量候选视频的策略。
推荐请求处理
我们的推荐系统的目标是提供个性化的推荐,帮助用户找到符合他们兴趣的高质量视频。为了提高用户满意度,必须实时提供这些建议,并反映用户最近在网站上的活动。此要求使我们无法通过许多工作中采用的预计算来生成建议,因为预先计算的建议无法反映用户最近的活动。相反,我们为每个用户请求实时为用户计算新建议。
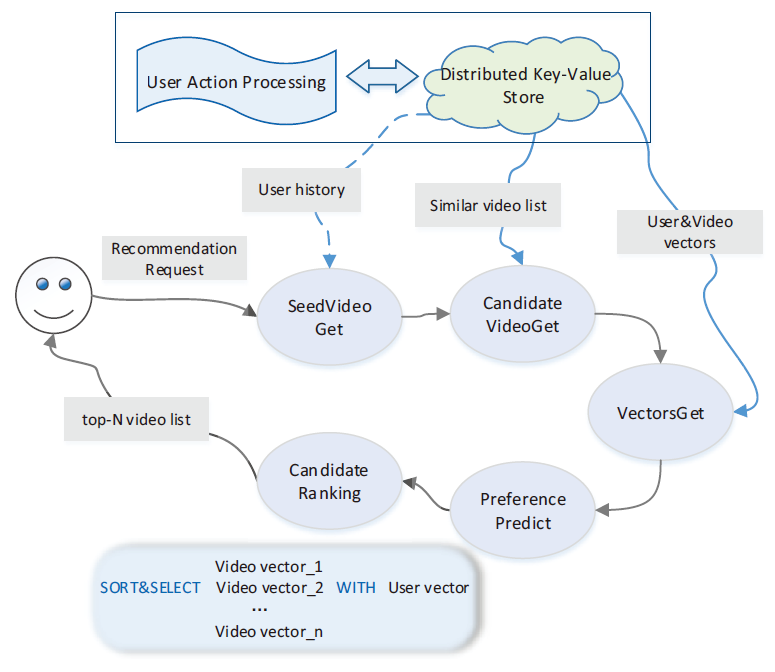
从接收用户推荐请求到生成实时视频推荐的过程如图所示,其中实时表示延迟通常以毫秒为单位。推荐发生的典型情况是,当用户打开要观看的视频时,我们需要制作类似的视频作为推荐。在收到用户推荐请求后,我们首先得到几个种子视频,然后扩展其相关视频集以选择一些候选。然后,利用 MF 模型计算出用户和视频向量,并根据公式预测用户对候选视频的偏好。最后的推荐是根据预测的偏好对这些候选视频进行排名。具体来说,示例种子视频可以是当前在上述情况下观看的视频用户,也可以是用户在其他不观看任何视频的情况下之前与(观看、喜欢)交互的历史视频。
请注意,我们选择一些候选视频以通过进一步排名来生成最终推荐。候选视频选择对于实时推荐生成是至关重要的,因为通过整个视频集的计算太昂贵并且实时响应用户的时间成本太高。考虑到用户或视频向量的维度总是在 20 到 200 之间,采用向量内积的偏好预测肯定是计算密集型任务。在像腾讯视频这样的大型视频网站中,整个视频集包含数百万个视频,每天有超过 10 亿的用户请求,一秒钟内最多有 10 万个请求。在没有候选视频选择的情况下,实时视频推荐生成中的巨大计算将是灾难。
候选视频准备
从上面的讨论中我们可以得出结论,实时视频推荐生成的关键是候选视频的选择。如先前所示,通过扩展种子视频的相关视频集来生成候选者。因此,为了选择高质量的候选视频,我们需要从视频 i 到一组相似或相关视频的精确映射。在这种情况下,我们将类似的视频定义为用户在观看给定的种子视频后可能观看的视频。为了获得准确的类似视频,我们结合了以下三个因素:协同过滤相似性,类型相似性和时间因素。
协同过滤相似性
基于矩阵分解模型,我们可以得到每个视频 i 的潜在因子 $y_i$ 的向量。考虑到这些向量的含义,我们可以通过采用内积来自然地计算视频 i 和 j 之间的相似性,如下所示:
$$s1_{ij}=y_{i}^{T}y_{j}$$
类型相似
在腾讯视频中,每个视频都有一个细粒度类别系统。人们普遍认为,相同类型的视频可能比不同类型的视频更相似。因此,我们在计算类似视频时会考虑视频的类型。对于视频 i 和 j,类型相似性定义如下:
$$s2_{ij}=\{\begin{array}{ll}{1}&{\text{type}(i)\text{equals type}(j)}\\{0}&{\text{type}(i)\text{not equals type}(j)}\end{array}$$
时间因素为了跟踪视频推荐中的实时变化趋势,我们在视频相似性计算中加入了时间因素,认为视频对之间的相似性是时间敏感的,并且随着时间的推移而下降,不需要新的相关用户操作支持。换句话说,过去类似的视频应该逐渐被遗忘。因此,在相似性计算中引入了时间因子。
具体来说,视频对的相似性随着更新时间的推移而降低。更新时间是指最近一次用户操作触发相似性计算的时间(视频i和j的相似性只有在发生与i或j相关的新用户操作时才会更新)。形式上,我们使用一个阻尼因子来测量这个时间因子,如下所示:
$$d_{ij}=2^{-\Delta t/\xi}$$
其中$\Delta t$是$\text{sim}_{ij}$(在下一节中定义)更新时间和当前时间之间的时间差,$\xi$是控制衰减速率的参数。
聚合影响因素
在此情景下,上述每一个相似性因素都在不同程度上对最终建议作出了贡献。我们利用每个相似因子进行关联融合。对于两个视频i和j,它们之间的总体相关性定义为:
$$\text{sim}_{ij}=d_{ij}\left((1-\beta)\times s1_{ij}+\beta\times s2_{ij}\right)$$
其中$\beta$是调整最终相关函数中不同相似因子的权重的参数。$\xi$和$\beta$的确切值由实验确定。
部署问题
可扩展的实施
基于实时增量矩阵分解的协同过滤的拓扑框架如图所示。在图中,Spout以<user,video,action>的形式发出数据元组,UserHistoryBolt接收这些数据元组,具有相同用户ID的数据元组将转到要处理的同一个worker。此外,我们还使用了一个基于分布式内存的键值存储(图中的KVStore)来存储计算中使用的状态数据。我们可以通过向量的对应键(用户ID或视频ID)访问向量$x_u$或$y_i$,而不影响其他向量。在这种情况下,KVStore有助于在操作员之间分配计算。
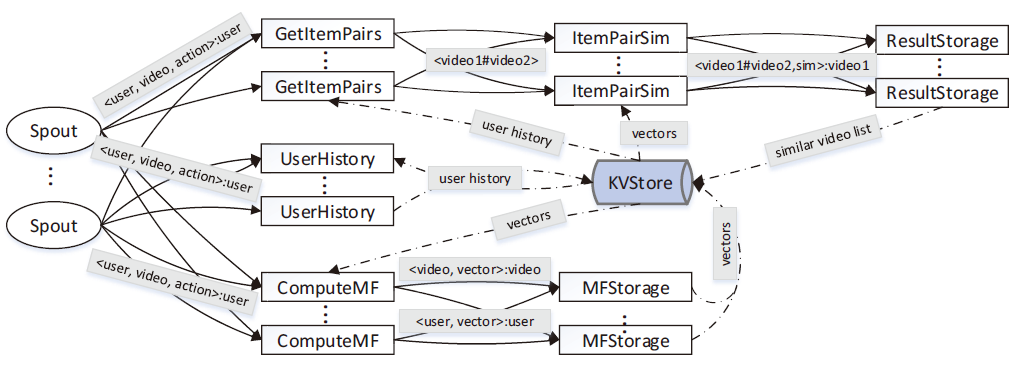
具体来说,Spout从腾讯视频获取数据,解析原始消息,过滤不合格的数据元组,并将数据元组转换为下一个Blot。生成的数据元组Spout包含多个字段,例如用户id,视频id,动作类型,动作结果等。为了清晰呈现,我们只显示图中数据元组的主要字段。用户操作元组按用户id字段分组,并流向下一个Blot。
有三条主线可以并行处理用户操作元组。
- 首先,ComputeMFbolt和MFStoragebolt接收用户操作元组,并根据算法更新KVStore中的向量($x_u$s和$y_i$s)。
- 第二,UserHistorybolt接收用户操作元组,并在KVStore中记录用户的行为。
- 第三,GetItemPairsbolt、ItemPairSimbolt和ResultStoragebolt接收用户动作元组,利用用户UserHistorybolt记录的用户历史进行视频对相似性计算,最后在KVStore中存储每个视频的前N个相似视频列表。
注意,模型更新是通过ComputeMF和MFStorage两个blot完成的。首先,将用户操作元组传输到ComputeMFbolt。ComputeMFbolt从KVStore中读取用户向量和视频向量,并按照算法计算新向量。然后,新的向量将被发送到MFStoragebolt,通过它们在KVStore存储中使用的对应键进行分组。MFStoragebolt接收新的向量并将其写入KVStore。这个实现设计中的关键因素是将新的向量从ComputeMFbolt重新分配到MFStoragebolt,并按它们的键进行分组,从而确保在某个时刻只有一个工作节点可以在特定的视频或用户向量上运行。使用这种方法,向量的更新是原子的,不会发生写冲突。从而可以安全地进行计算。
视频对的相似性计算由三个bolt完成,分别是GetItemPairsbolt、ItemPairSimbolt和ResultStoragebolt。与模型更新不同,本设计的目的是减少资源消耗,加快计算速度。具体地说,通过使用字段分组传输数据流,可以将KVStore的同一个键的查询减少到同一个worker,从而可以利用优化进行有效的处理。可能的优化是合并器技术和缓存技术。
一些优化
人口统计筛选
推荐指标之一是多样性和新颖性。YouTube通过在相关视频图上采用有限的传递闭包来扩展候选视频集,以生成更加多样和新颖的建议。然而,在生成建议时需要计算的候选视频的数量也随之增加,因此,生成建议的时间会更长,这可能会导致对用户的建议延迟,而长时间的等待会降低用户的满意度。在腾讯视频中,我们使用另一种称为基于人口统计的算法(DB)的技术来补充基于矩阵分解(MF)的协同过滤(CF)的推荐结果。
我们首先根据用户的性别,年龄和教育等属性将用户聚集到不同的人口群体中。同一人口统计组中的用户通常具有相似的兴趣或偏好。我们计算每个人口统计群组的热门视频,即最受欢迎的视频。数据库根据用户的人口统计组提供这些热门视频作为用户的推荐。通过选择性地将DB算法的结果合并到基于MF的CF算法的结果中,我们拓宽了推荐的范围,并为用户提供了发现新兴趣的机会。
人口统计筛选具有额外的好处。对于新用户或那些与视频几乎没有交互的非活动用户,MF算法无法产生足够有效的推荐。在这种情况下,我们可以依靠人口统计组信息来更好地了解这些用户。利用DB算法的结果,我们可以为这些用户提供推荐服务,从而部分解决新用户问题。特别是,对于新的未注册用户,我们会根据建议生成全球人口统计群体的热门视频,事实证明这些视频在实践中运作良好。
人口统计训练
我们使用的另一个优化是人口统计训练,即在前面提到的人口统计用户组中运行推荐算法。具体来说,每个人口统计学组都会有一个视频向量$y_i$,并计算人口统计学组中视频对之间的相似性。
人口统计训练有两个好处。一方面,人口统计学组的user-item矩阵明显不如全局user-item矩阵稀疏。通过在人口统计用户组中运行推荐算法,我们将得到一个更精确的模型。另一方面,人口统计训腾讯实时推荐算法练将生成更细粒度的模型,它可以捕捉不同人口群体之间的评分模式变化。


