当谈论到查询的相关性,很重要的一件事就是对于给定的查询语句,如何计算文档得分。文档得分是一个用来描述查询语句和文档之间匹配程度的变量。如果你希望通过干预Lucene查询来改变查询结果的排序,你就需要对Lucene的得分计算有所理解。
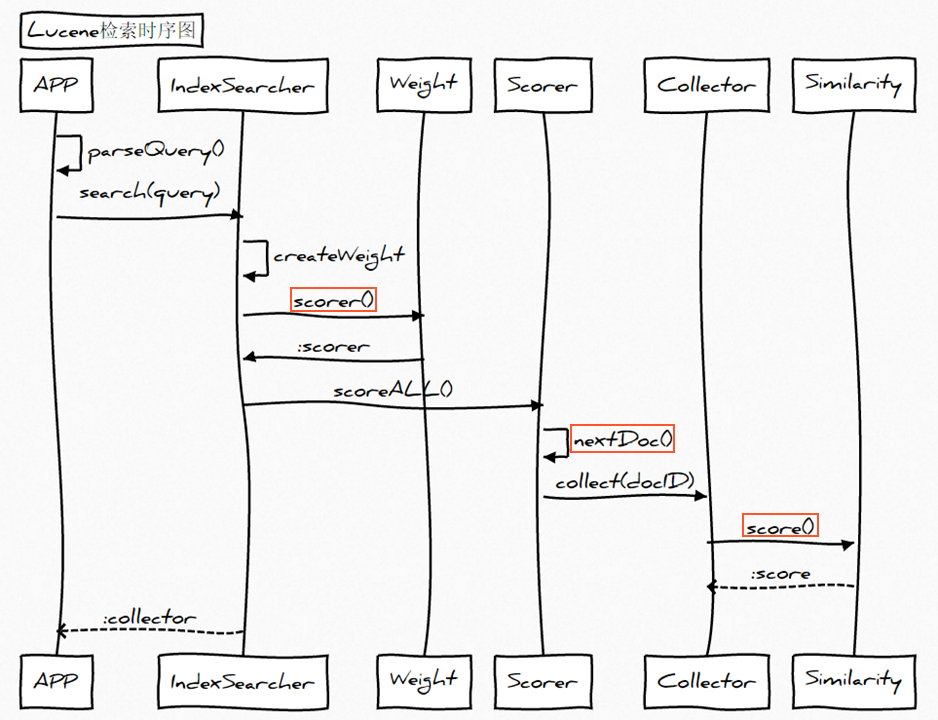
匹配文档的打分因子
当一个文档出现在了搜索结果中,这就意味着该文档与用户给定的查询语句是相匹配的。Lucene会对匹配成功的文档给定一个分数。至少从Lucene这个层面,从打分公式的结果来看,分数值越高,代表文档相关性越高。自然而然,我们可以得出:两个不同的查询语句对同一个文档的打分将会有所不同,但是比较这两个得分是没有意义的。用户需要记住的是:我们不仅要避免去比较不同查询语句对同一个文档的打分结果,还要避免比较不同查询语句对文档打分结果的最大值。这是因为文档的得分是多个因素共同影响的结果,不仅有权重(boosts)和查询语句的结构起作用,还有匹配关键词的个数,关键词所在的域,查询归一化因子中用到的匹配类型……。在极端情况下,只是因为我们用了自定义打分的查询对象或者由于倒排索引中词的动态变化,相似的查询表达式对于同一个文档都会产生截然不同的打分。
暂时还是先回来继续探讨打分机制。为了计算出一个文档的得分,我们必须考虑如下的因素:
- 文档权重(Document boost):在索引时给某个文档设置的权重值。
- 域权重(Field boost):在查询的时候给某个域设置的权重值。
- 调整因子(Coord):基于文档中包含查询关键词个数计算出来的调整因子。一般而言,如果一个文档中相比其它的文档出现了更多的查询关键词,那么其值越大。
- 逆文档频率(Inerse document frequency):基于Term的一个因子,存在的意义是告诉打分公式一个词的稀有程度。其值越低,词越稀有(这里的值是指单纯的频率,即多少个文档中出现了该词;而非指Lucene中idf的计算公式)。打分公式利用这个因子提升包含稀有词文档的权重。
- 长度归一化(Length norm):基于域的一个归一化因子。其值由给定域中Term的个数决定(在索引文档的时候已经计算出来了,并且存储到了索引中)。域越的文本越长,因子的权重越低。这表明Lucene打分公式偏向于域包含Term少的文档。
- 词频(Term frequency):基于Term的一个因子。用来描述给定Term在一个文档中出现的次数,词频越大,文档的得分越大。
- 查询归一化因子(Query norm):基于查询语句的归一化因子。其值为查询语句中每一个查询词权重的平方和。查询归一化因子使得比较不同查询语句的得分变得可行,当然比较不同查询语句得分并不总是那么易于实现和可行的。
Lucene的打分公式
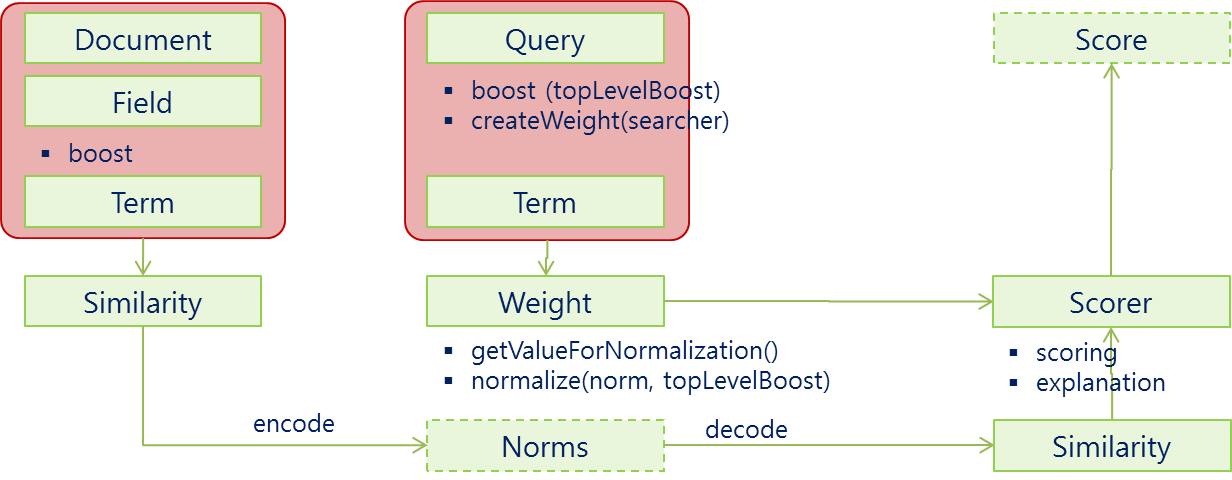
Lucene概念上的打分公式是这样的:(TF/IDF公式的概念版)
$$score(q,d)=coord(q,d)*queryBoost(q)*\frac{V(q)*V(d)}{|V(q)|}*lengthNorm(d)*docBoost(d)$$
上面的公式展示了布尔信息检索模型和向量空间信息检索模型的组合。我们暂时不去讨论它,直接见识下Lucene实际应用的打分公式:
$$score(q,d)=coord(q,d)*queryBoost(q)*\sum_{t\in q}(tf(t\in q)*idf(t)^2*boost(t)*norm(t,d))$$
可以看到,文档的分数实际上是由查询语句q和文档d作为变量的一个函数值。打分公式中有两部分不直接依赖于查询词,它们是coord和queryNorm。公式的值是这样计算的,coord和queryNorm两大部分直接乘以查询语句中每个查询词计算值的总和。另一方面,这个总和也是由每个查询词的词频(tf),逆文档频率(idf),查询词的权重,还有norm,也就是前面说的length norm相乘而得的结果。听上去有些复杂吧?不用担心,这些东西不需要全部记住。你只需要知道在进行文档打分的时候,哪些因素是起决定作用的就可以了。基本上,从前面的公式中可以提炼出以下的几个规则:
- 匹配到的关键词越稀有,文档的得分就越高。
- 文档的域越小(包含比较少的Term),文档的得分就越高。
- 设置的权重(索引和搜索时设置的都可以)越大,文档得分越高。
正如我们所看到的那样,Lucene会给具有这些特征的文档打最高分:文档内容能够匹配到较多的稀有的搜索关键词,文档的域包含较少的Term,并且域中的Term多是稀有的。
下面详细解释公式乘积的每个因子的含义,以及是如何计算的,这样能够加深对Lucene得分计算的理解,才能在实际应用中根据需要调整各个参数,从而制定满足应用的排序策略。
coord(q,d)
评分因子,是基于文档中出现查询项的个数。越多的查询项在一个文档中,说明些文档的匹配程序越高。默认是出现查询项的百分比。这个评分因子的计算公式是:
public float coord(int overlap, int maxOverlap) {
return overlap / (float)maxOverlap;
}
其中:
- overlap:检索命中query中term的个数
- maxOverlap:query中总共的term个数
比如检索”english book”,现在有一个文档是”this is an chinese book”。那么,这个搜索对应这个文档的overlap为1(因为匹配了book),而maxOverlap为2(因为检索条件有两个book和english)。最后得到的这个搜索对应这个文档的coord值为0.5。
queryNorm(q)
queryNorm(q)是查询权重对得分的影响,这个因素对所有文档都是一样的值,所以它不影响排序结果。比如如果我们希望所有文档的评分大一点,那么我们就需要设置这个值。它的计算公式如下:
public float queryNorm(float sumOfSquaredWeights) {
return (float)(1.0 / Math.sqrt(sumOfSquaredWeights));
}
tf(t in d)
即term t在文档d中出现的个数,它的计算公式官网给出的是:
public float tf(float freq) {
return (float)Math.sqrt(freq);
}
比如有个文档叫做”this is book about chinese book”,我的搜索项为”book”,那么这个搜索项对应文档的freq就为2,那么tf值就为根号2,即1.4142135idf(t)
关联到反转文档频率,文档频率指出现term t的文档数docFreq。docFreq越少idf就越高(物以稀为贵),但在同一个查询下些值是相同的。默认实现:
public float idf(long docFreq, long numDocs) {
return (float)(Math.log(numDocs / (double)(docFreq + 1)) + 1.0);
}
这里的两个值解释下
- docFreq指的是项出现的文档数,就是有多少个文档符合这个搜索
- numDocs指的是索引中有多少个文档。
- this book is about english
- this book is about chinese
- this book is about japan
我要搜索的词语是”chinese”,那么对第二篇文档来说,docFreq值就是1,因为只有一个文档符合这个搜索,而numDocs就是3。最后算出idf的值是:(float)(Math.log(numDocs/(double)(docFreq+1))+1.0)=ln(3/(1+1))+1=ln(1.5)+1=0.40546510810816+1=1.40546510810816
boost(t)
查询时期term的加权,这个就是一个影响值,比如我希望匹配chinese的权重更高,就可以把它的boost设置为2norm(t,d)
这个项是长度的加权因子,目的是为了将同样匹配的文档,比较短的放比较前面。
比如两个文档:
- chinese
- chinese book
我搜索chinese的时候,第一个文档会放比较前面。因为它更符合”完全匹配”。
m(t,d)=doc.getBoost()·lengthNorm·∏f.getBoost()
这里的doc.getBoost表示文档的权重,f.getBoost表示字段的权重,如果这两个都设置为1,那么nor(t,d)就和lengthNorm一样的值。
public float lengthNorm(FieldInvertState state){
final int numTerms;
if(discountOverlaps)
numTerms=state.getLength()-state.getNumOverlap();
else
numTerms=state.getLength();
return state.getBoost()*((float)(1.0/Math.sqrt(numTerms)));
}
比如我现在有一个文档:chinese book,搜索的词语为chinese,那么numTerms为2,lengthNorm的值为1/sqrt(2)=0.71428571428571。
索引的时候,把norm值压缩(encode)成一个byte保存在索引中。搜索的时候再把索引中norm值解压(decode)成一个float值,这个encode/decode由Similarity提供。官方说:这个过程由于精度问题,以至不是可逆的,如:decode(encode(0.714))=0.625注意事项:
- TF-IDF算法是以term为基础的,term就是最小的分词单元,这说明分词算法对基于统计的ranking无比重要,如果你对中文用单字切分,那么就会损失所有的语义相关性,这个时候搜索只是当做一种高效的全文匹配方法。
- 按照规则1某个词或短语在一篇文章中出现的次数越多,越相关。一定要去除掉stopword,因为这些词出现的频率太高了,也就是TF的值很大,会严重干扰算分结果。
- TF在生成索引的时候,就会计算出来并保存,而IDF是在query的时候获取,包含t的文档数=length(term的postinglist)。


