2024高考作文「新课标一卷」的作文题目:随着互联网的普及、人工智能的应用,越来越多的问题能很快得到答案。那么,我们的问题是否会越来越少?以上材料引发了你怎样的联想和思考?请写一篇文章。要求:选准角度,确定立意,明确文体,自拟标题;不要套作,不得抄袭;不得泄露个人信息;不少于800字。
出题老师或许有感于大火的ChatGPT。今天要讨论是的是人工智能到底能给我们带来什么?哪些问题人工智能暂时无法解决?
ChatGPT的原理
ChatGPT是在GPT(Generative Pre-training Transformer)模型的基础上通过改进优化得到的。GPT是一种大型语言模型,能够生成各种不同的文本类型,而ChatGPT则是针对对话场景特别优化过的,它可以根据上下文自动生成跟人类一样的文本对话。下图是OpenAI官方对ChatGPT的原理介绍。
GPT大模型
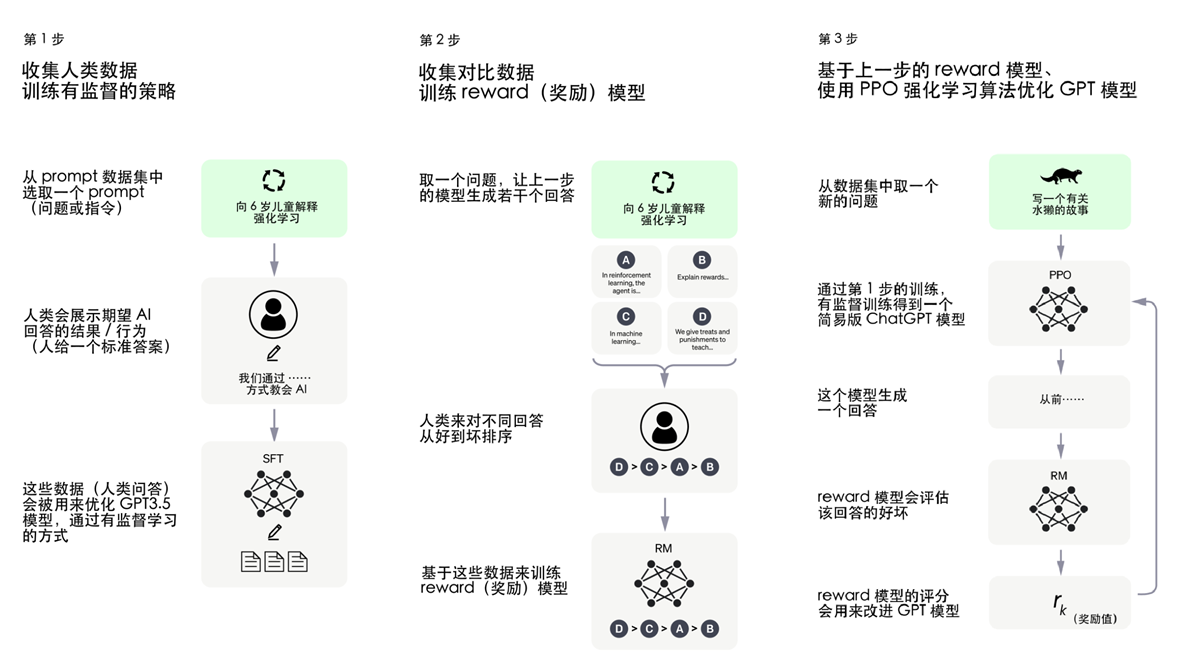
GPT系列模型基于这样的思路:让AI在通用的、海量的数据上学习文字接龙,即掌握基于前文内容生成后续文本的能力。这样的训练不需要人类标注数据,只需要给一段话的上文同时把下文遮住,将AI的回答与语料中下文的内容做对比,就可以训练AI。ChatGPT就是在GPT3.5模型上做的优化,作为GPT系列的第三代,GPT3.5在万亿词汇量的通用文字数据集上训练完成,几乎可以完成自然语言处理的绝大部分任务,例如完形填空、阅读理解、语义推断、机器翻译、文章生成和自动问答等等。
比如告诉GPT“花谢花飞花满”,GPT就能生成最有可能是下一个字的结果。但由于下一个字有各种可能性,比如“花满天”、“花满地”、“花满园”都说得通,所以GPT模型每次输出的结果是不同的。
第一步:有监督训练初始模型
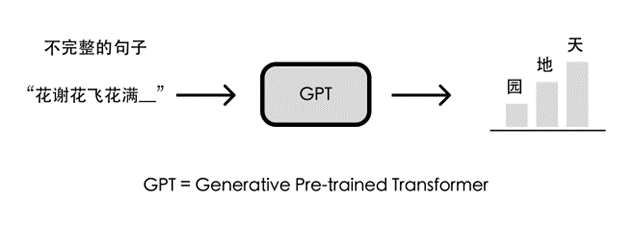
光靠学习文字接龙,GPT仍不知道该如何给出有用的回答。比如问GPT“世界上最高的山是哪座山?”,“你能告诉我么”、“珠穆朗玛峰”、“这是一个好问题”都是上下文通顺的回答,但显然“珠穆朗玛峰”是更符合人类期望的回答。
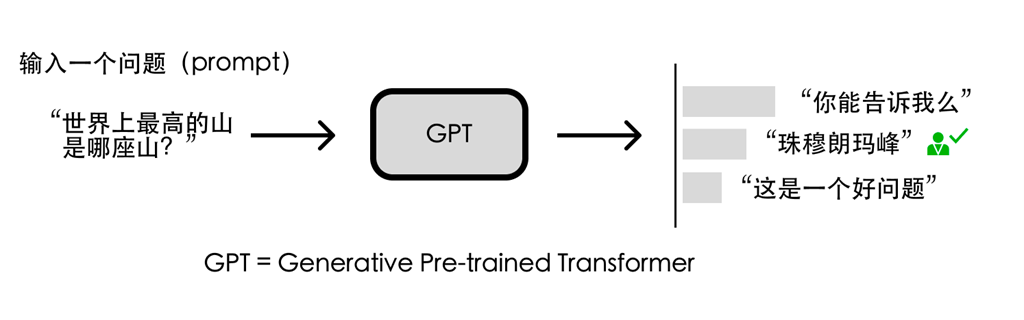
因此研究人员让人类就一些问题写出人工答案,再把这些问题和答案丢给GPT学习。这便是有监督训练,即对于特定问题告诉AI人类认可的答案,让AI依葫芦画瓢。这种方法可以引导AI往人类期望的方向去做文字接龙,也就是给出正确且有用的回答。通过这种有监督训练的方法,我们可以得到一个简易版的ChatGPT模型。
需要注意的是,这里并不需要人类穷举出所有可能的问题和答案,这既代价高昂又不甚现实。实际上研究人员只提供了数万条数据让AI学习,因为GPT本来就有能力产生正确答案,只是尚不知道哪些是人类所需的;这几万条数据主要是为了告诉AI人类的喜好,提供一个文字接龙方向上的引导。
第二步:Reward模型
如何让这个简易版的ChatGPT模型变得更强呢?我们可以参考其他AI模型的训练思路,前几年轰动一时的围棋人工智能AlphaGo,是通过海量的自我对弈优化模型,最终超越人类;能不能让GPT通过大量对话练习提升其回答问题的能力呢?可以,但缺少一个“好老师”。
AlphaGo自我对弈,最终胜负通过围棋的规则来决定;但GPT回答一个问题,谁来告诉GPT回答的好坏呢?总不能让人来一一评定吧?人的时间精力有限,但AI的精力是无限的,如果有个能辨别GPT回答好坏的「老师模型」(即Reward模型),以人类的评分标准对GPT所给出的答案进行评分,那不就能帮助GPT的回答更加符合人类的偏好了么?
于是研究人员让GPT对特定问题给出多个答案,由人类来对这些答案的好坏做排序(相比直接给出答案,让人类做排序要简单的多)。基于这些评价数据,研究人员训练了一个符合人类评价标准的Reward模型。
第三步:强化学习优化模型
“你们已经是成熟的AI了,该学会自己指导自己了”。要实现AI指导AI,得借助强化学习技术;简单来说就是让AI通过不断尝试,有则改之、无则加勉,从而逐步变强。
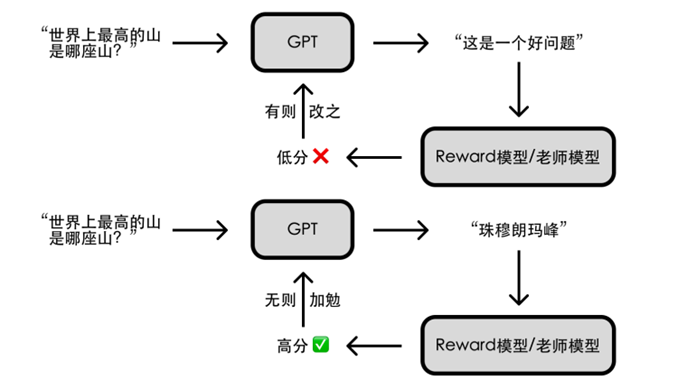
前两步训练得到的模型在这一步都能派上用场:我们随机问简易版ChatGPT一个问题并得到一个回答,让Reward模型(老师模型)给这个回答一个评分,AI基于评分去调整参数以便在下次问答中获得更高分。重复这个过程,完整版的ChatGPT就训练好啦!
从原理看,ChatGPT是一个擅长对话的文字接龙高手,它看似能生成自然流畅的回答,但实际上这些回答往往欠缺逻辑性和正确性的考虑,从某种意义上说都是“一本正经地胡说八道”,因而闹出很多笑话。
机器学习的能与不能
在了解完上述大概原理后,您应该ChatGPT能做什么,不能做什么有个大致的推论了。
在以下方面人工智能能有不错的表现:
- 事实查询:AI能够快速从大量的信息中查找事实,如历史事件、科学数据等。
- 常规问题:AI也可以通过搜索引擎等工具快速提供一些常规问题的答案,如菜谱、导航等。
- 模式识别:AI可以通过分析数据识别出模式或趋势,如社交媒体上的热门话题等。
- 数据预测:基于大量的历史数据,AI可以用来预测未来的情况,如天气预报、销售预测等。
人工智能当前很难有突破的内容:
- 抽象问题:涉及哲学、道德、伦理等主题的问题,通常需要深入的思考和理解,这是目前的AI无法做到的。
- 主观问题:涉及个人感受或观点的问题,如“我应该做什么才能更快乐?”或“我应该选择哪个职业?”AI无法为此类问题提供个性化的答案。
- 新颖问题:对于新的或前所未有的问题,由于缺乏足够的历史数据,AI可能无法提供准确的答案。
- 复杂问题:涉及多个领域或需要整合大量信息的问题,可能超出了AI的处理能力。
人工智能让旧知识(“通识”)更容易获取
人工智能,尤其是ChatGPT,更容易回答通识性问题的:
- 大规模训练数据:大语言模型通常基于数以亿计的网页、书籍、新闻和其他文本资料进行训练,这些资料包含了广泛的知识领域,使得模型能够学习到各种通识性的信息。
- 模式识别:AI通过机器学习算法,学会了识别和理解语言中的模式和结构。对于常见的通识问题,这些模式往往更为明显,因此AI可以更准确地匹配和生成答案。
- 统计推断:在处理大量数据后,模型能够进行统计推断,对于常见问题,它可以根据之前见过的类似问题和答案来预测最可能的正确响应。
- 知识库集成:一些AI系统还会与知识图谱或其他结构化知识库相连,这使得它们可以直接查询事实性信息,从而更好地回答具体问题。
- 泛化能力:由于训练数据的多样性,AI模型具有一定的泛化能力,能够处理未曾遇到但逻辑上相关的新问题。
人工智能的最大价值是提升信息获取效率
- 快速响应:相比于人工回答,AI可以在极短的时间内提供答案。用户不需要等待,可以即时获取所需信息。
- 综合信息:AI可以从大量的文本数据中提取和整合信息,提供一个综合的、简明的答案。这有助于用户快速了解某个主题,而不必花费时间去阅读大量资料。
- 自然语言理解:AI具备自然语言处理的能力,可以理解用户用日常语言提出的问题。这使得信息查询变得更加直观和方便,不需要使用特定的关键词或查询语言。
- 上下文理解:先进的AI模型能够理解对话的上下文,从而提供更相关和连贯的回答。这使得多轮对话中,用户无需重复背景信息,进一步提升了信息获取的效率。
- 多领域知识:AI模型在训练过程中接触了广泛的知识领域,因此可以回答涉及不同学科和话题的各种问题。用户不需要切换不同的工具或平台,就能获取多方面的信息。
个性化建议:通过分析用户的查询历史和偏好,AI 可以提供个性化的推荐和建议,使得信息获取更具针对性和效率。
在学习上:
- 个性化学习:人工智能可以根据每个学生的学习速度和能力提供个性化的学习路径。这种方式可以确保学生在他们个人的学习节奏中进行学习,从而提高学习效率。
- 互动学习:AI 技术可以用于创建互动的学习工具,如虚拟模拟、教育游戏等,这些工具可以提供更具吸引力和参与度的学习体验,从而提高学习效率。
- 智能辅导:通过机器学习算法,AI 可以分析学生的学习模式和进度,提供即时的反馈和建议,帮助学生解决问题和疑惑,提高学习效率。
- 自动评估:AI 可以用于自动评估学生的作业和测试,快速提供反馈,节省教师的时间,让他们可以专注于提供更有深度的教学。
- 在线学习平台:AI 可以通过在线课程和学习管理系统提供灵活的学习机会,学生可以在任何时间、任何地点进行学习,提高学习效率。
在工作上:
- 自动化任务:AI 能够处理大量的重复和繁琐的任务,如数据录入、预定会议等,从而让员工有更多的时间去处理更复杂和需要创新思考的任务。
- 数据分析:AI 能够快速地分析大量数据,提供有价值的洞见和预测,帮助决策者做出更好的决策。
- 个性化推荐:在销售和营销领域,AI 能够根据用户的行为和喜好进行个性化的推荐,提高销售和营销的效果。
- 客户服务:AI 可以用于提供 24/7 的在线客户服务,如使用 AI 聊天机器人进行客户咨询和问题解答,提高客户满意度。
人工智能能否发现“新知”?
人工智能在某种程度上可以帮助我们产生新的知识发现。这是因为 AI 能够处理和分析的数据量远远超过了任何一个人类的能力。通过机器学习和深度学习,AI 可以从海量的数据中找出模式、关联和趋势,这在许多情况下已经导致了新的知识和发现。例如:
- 在生物医学研究领域,AI 被用来分析复杂的基因数据和临床试验数据,这有助于研究者发现新的药物靶点,甚至预测药物的副作用。
- 在天文学领域,AI 被用来分析和解释从空间望远镜收集到的海量数据,帮助科学家发现新的星体,并理解宇宙的结构。
尽管 AI 可以帮助我们发现新的知识,但这些发现仍然需要人类的专家来解释和验证。AI 可以看作是一种强大的工具,而不是一个独立的发现者。此外,AI 的能力受限于它所处理的数据:如果数据是有误的或存在偏差,那么 AI 的分析结果也可能是错误或偏差的。
由于人工智能依赖语料库的训练,导致 AI 只能帮助探索“新知”,而无法独立的发现新知。例如,在物理学上,AI 主要是作为一种工具来协助物理学家进行研究,而不是独立地发现新的物理规律。尽管 AI 能够帮助我们处理数据和识别模式,但它并不能理解这些模式背后的物理原理。发现新的物理规律通常需要深入的理解和创新的思维,这是目前的 AI 技术所无法完成的。AI 可以提供洞见和启示,但真正的发现仍然需要人类物理学家的直觉、专业知识和创新思维。
“少数服从多数”与“真理掌握在少数人手中”
在人工智能(AI)领域,特别是在机器学习和集成学习的应用中,存在“少数服从多数”的现象,这主要体现在决策和预测的过程中。在实际应用中,这种方法已经被证明是有效的,并在许多领域得到了广泛应用。
- 训练数据中的多数类优势:在训练机器学习模型时,如果某一类的样本数量远大于其他类,那么模型可能会对这一类有所偏好,这就是所谓的类不平衡问题。例如,如果我们正在训练一个用于垃圾邮件检测的模型,而我们的数据中 90% 是正常邮件,只有 10% 是垃圾邮件,那么模型可能会倾向于预测邮件为正常邮件,因为这样做在训练数据上能取得更好的性能。
- 算法的集成学习:集成学习是一种常见的机器学习策略,它结合了多个学习算法的预测。在许多情况下,集成的结果是通过多数投票原则决定的。也就是说,少数的预测结果会服从多数的预测结果。
“真理掌握在少数人手里”这句话并不是绝对的,它在具体上下文中可能有不同的解释。但通常,这可能是因为以下几个原因:
- 深度知识和专业了解:对于很多专业领域或复杂的科学现象,真理往往需要经过深入研究和深度理解才能获得。这类深度了解往往在专家或者对这个领域有深度研究的少数人中得以实现。
- 创新思考:在科学、艺术、技术等领域,往往是那些敢于挑战现有认知,能够独立思考的人,能发现新的真理或者创造新的东西。
- 观点多样性:在任何一个问题上,都会有多种不同的观点。在这些观点中,可能只有少数几个是最接近实际真相的。
“真理掌握在少数人手里”这种说法只是强调在某些情况下,真理可能并不被大多数人所理解或接受。科学并不是根据多数人的观点来决定事实的真实性的。就算全世界的人都相信某个观点,但如果这个观点科学上不成立,那么它仍然是不正确的。反之,如果只有一个人提出的观点科学上成立,即使全世界的人都不相信,那么这个观点仍然是正确的。例如,哥白尼的日心说在最初是少数人的观点,大多数人都相信地心说。但随着科学研究的深入和更多证据的出现,最终证明了日心说的正确性。
人工智能的学习和理解能力在很大程度上取决于它的训练数据和算法设计。如果 AI 的训练数据包含了深度知识和专业理解,那么 AI 就有可能学习并理解这些知识。如果 AI 在哥白尼的时代,它的输出会基于那个时代可用的数据和信息。如果大部分可用的信息都支持地心说,那么 AI 可能会提供更多关于地心说的信息。然而,如果 AI 被提供了支持日心说的证据,那么它将能够处理和理解这些信息。总的来说,AI 的判断取决于训练它的数据,而不是个人的信仰或接受某种观点。



文章的浏览次数统计有问题哦
页面有缓存~