Datasette简介 Datasette是一个开源工具,用于将结构化数据发布为交互式浏览和查询的Web应用程序。它主要用于将SQLite数据库转换为易于浏览和共享的格式,适合数据分析、数据展示和快速原型设计等场景。 核心功…

RAWGraphs简介 RAWGraphs是一个开源的数据可视化框架,专为设计师和数据专家设计,旨在将复杂的数据集转换为丰富的可视化图表。它提供了一种简单而灵活的方式来创建定制化的数据可视化,并且不需要编程技能。RAWGra…

Datawrapper简介 Datawrapper是一个易于使用的在线数据可视化工具,专为记者、研究人员、数据分析师以及任何需要快速创建专业图表和地图的人设计。它不需要编程技能,可以帮助用户轻松地将数据转化为可视化的图表、…
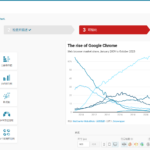
Bokeh简介 Bokeh是一个用于创建交互式和可视化丰富的web应用程序的Python库。它专为需要在现代Web浏览器中呈现复杂数据可视化的场景而设计,旨在帮助数据科学家、分析师和开发人员以简洁的方式创建高效和动态的数…

Polynote简介 Polynote是一个开源的多语言编程笔记本工具,专为数据科学和机器学习工作流程而设计。它由Netflix开发,旨在提供更好的多语言支持和数据可视化能力,帮助数据科学家和工程师更高效地进行数据分析和模…
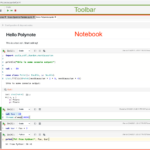
BeakerX简介 BeakerX 是一个扩展 Jupyter Notebook 功能的开源项目,旨在为数据科学家和分析师提供更多的工具和功能。它通过增加对多种编程语言的支持、提供丰富的交互式小部件(widgets)、以及数据可视化工具,增…

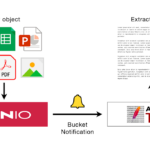
Apache Tika简介 Apache Tika是一个用于检测和提取各种文件格式的文本内容和元数据的开源框架。它能够处理多种文件类型,如文本文档、PDF、电子表格、图像、音频和视频文件等,提供了一种统一的接口来访问这些文件…
Elasticsearch简介 Elasticsearch是一个分布式、RESTful风格的搜索和分析引擎,广泛用于实时搜索、日志分析、监控和业务分析等场景。Elasticsearch由Elastic公司开发和维护,基于Apache Lucene构建,提供了一个强大…
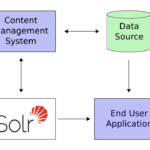
Apache Solr 简介 Apache Solr 是一个基于 Apache Lucene 的高性能、可扩展的搜索平台。Solr 不仅继承了 Lucene 的全文搜索功能,还增加了许多高级特性和管理工具,使其成为企业级搜索解决方案的首选。Solr 以其易…
TimescaleDB简介 TimescaleDB是一个开源的时间序列数据库,建立在PostgreSQL之上,专为高性能的时间序列数据存储和分析而设计。它扩展了PostgreSQL的功能,提供了处理时间序列数据所需的特殊优化和特性,如自动分区…






