小红书是一个分享社区加电商的APP,主要用户群体为女性。小红书主要包含两大部分:
- 分享社区:分享精致生活的社区,主要分享内容(笔记)包括美装、穿搭,喜欢去的餐馆,新发现的旅行地点、酒店,最新的母婴和家居生活。
- 商城:类似天猫商城的B2C平台,非自营。主要是基于社区内容做盈利和转化。
我们这里要分析的内容主要针对的是小红书的分享社区。小红书首页的内容主要由分享社区的内容通过推荐算法给到的用户。
备注:个人平时不用小红书,以下内容仅为网上资料的整理,正确性有待验证。
内容在小红书站内的主要曝光渠道:
- 关注逻辑
- 推荐逻辑
- 搜索逻辑
对爆款笔记来说,首页发现tab的推荐逻辑是最大的曝光渠道。
在下面五个主要曝光渠道中,1和2属于关注逻辑,3和4属于推荐逻辑,5属于。对于爆款笔记来说,3是最大的曝光渠道。
内容识别
小红书的首页feed流主要也是基于内容的相似性进行推荐,即:如果你喜欢A内容,则会推荐与A内容有相似标签的B内容。在推荐系统中,你喜好的内容标签与你曾经的浏览记录强相关,系统会推荐你浏览过或点赞过(主要权重应该是点赞收藏)内容的相似内容。小红书现有的推荐算法对用户喜爱的内容标签进行实时反馈推荐,即你现在点赞了一个早餐的笔记,接下来会立刻出现相关内容。
小红书系统如何判断两个内容相似呢?小红书采用的策略主要是给内容分类:
- 通过CNN(卷积神经网络)提取图片特征,对图片分类。
- 在Caffe Model Zoo模型里选出一个VGG的16层神经网络,标注了少量小红书上的图片,把它的主题标上去,然后再fine-tune这个神经网络,最后就达到期望的效果。
- 通过Doc2Vec提取文本特征,将文本内容划分到特定主题
- 结合图像特征和文本特征提升判断准确度
小红书的算法理念:非常注重算法的实际效果,远超过这个算法先进不先进,比如上面提取图像特征的模型,并不是CNN里效果最好的,而是一个相对简单的模型,16层神经网络相对简单,容易理解,比较能Hold住。
经过上述处理后,会把笔记分类到对应的类目下:
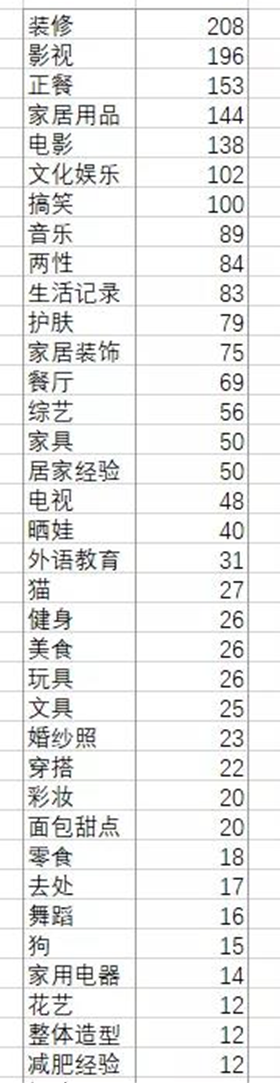
内容过滤
内容平台一个比较大的挑战是需要对内容进行审核,小红书直接使用的是数美科技的外部服务。对图片和文章等内容进行过滤:
- 涉政违规识别:基于海量人脸库和专业审核人员的审核标准,利用深度学习技术,识别正常、漫画、恶搞、负面涉政人物的违规信息,降低违规风险,覆盖涉政人物500余个。政治敏感人物库尽可能覆盖全面,包括国家领导人、敏感事件人物、英雄烈士等,形式包括蓝底照片、生活照片、历史照片、漫画恶搞、代表形象等。实时监测政治敏感事件和热点事件,发现问题图片及时加入政治敏感人物库中。
- 暴力恐怖识别:通过海量暴恐图片库,依托深度学习引擎,支持国旗国徽,恐怖主义,军装,枪支道具,血腥暴乱,儿童邪典等不同类型的图片识别。国旗国徽包括主流国家国旗国徽、各大政党旗党徽、香港特别行政区区旗徽、澳门特别行政区旗徽、共青团旗帜或团徽、国内各种军徽章等。
- 色情污秽识别:利用大规模GPU集群和深度学习技术,准确快速稳定地识别色情,低俗,性感图片,解决直播,视频,电商,社区网站,论坛等图像内容的黄反问题。帮助企业降低传播污秽、色情、低俗内容的风险,大规模提升人工审核团队效率,增强用户浏览体验。支持重度色情、色情、性感、低俗、正常等多种级别,灵活适应不同应用、场景、角色的个性化审核标准。
- 广告及变体识别:通过OCR识别、垃圾文本识别、广告分类模型,识别手机号,微信,QQ,淘宝,微博,网址,二维码,水印等近10种联系方式及其变体。
内容分发
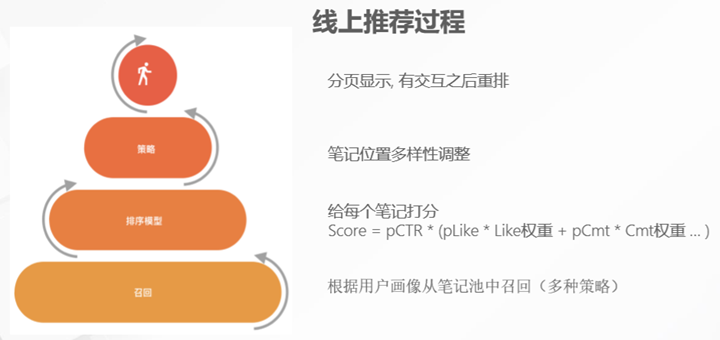
小红书线上推荐的流程主要可以分为三步。
- 第一步,从小红书用户每天上传的笔记池中选出候选集,即通过各种策略从近千万条的笔记中选出上千个侯选集进行初排。
- 第二步,在模型排序阶段给每个笔记打分,根据小红书用户的点赞和收藏行为给平台带来的价值设计了一套权重的评估体系,通过预估用户的点击率,评估点击之后的点赞、收藏和评论等的概率进行打分。
- 第三步,在将笔记展示给用户之前,选择分数高的笔记,通过各种策略进行多样性调整。
在此模型中最核心的点击率、点赞数、收藏、评论等都是通过机器学习模型训练对用户各项行为的预估并给出相应分数。
目前了解到的与笔记本相关的因素:
- 账号权重
- 原创率
- 垂直率:专注某个领域
- 内容质量率
- 账号活跃率
- 账号等级
- 是否品牌合作人
- 是否签约MCN
- 笔记权重
- 原创:如果字数超过100字,但原创度低于60%,就会”被限流”。而你的原创度越高,就越是能拿满该项权重分数,最高为5分。
- 转化率:这个转化率就是转发、评论、收藏、点赞。
- 内容长度:内容长度超过600字视为满足合格条件,可以获得内容长度的权重分,反之,不到600字则不增加此部分的权重,实践证明:有效。
- 关键词:关键词就是你文中提到的关键词或者标题中的关键词,与整个笔记的相关性,如果关联性比较小,系统就认为你可能是乱贴关键词恶意引流,此部分的权重会被扣掉。
- 标签:标签会分为两部分检查权重问题,一部分是看标签的内容是否是广告,另一部分是加与不加的区别
- 话题:话题和标签的理论是类似的,但一部分检查的是话题的关联性,另一部分才是加与不加的区别。另外话题选择要比较慎重,这决定了我们后期流量在搜索中的索引问题,如果选择了一个很弱的话题,以后距离搜索的流量就会远了一点。
- 违禁词:评论很注重出现违禁词也会产生影响,需要及时进行删除
推荐系统架构
在小红书线上推荐过程的背后是一套完整的从线上到线下的推荐系统,下图展示了小红书推荐系统架构,红色表示实时操作,灰色则是离线操作。通过算法推荐之后,用户和笔记进行交互,产生用户的曝光、点赞和点击的信息,这些信息被收集形成用户笔记画像,也会成为模型训练的训练样本,产生分析报表。训练样本最终生成预测模型,投入线上进行算法推荐,如此就形成了一个闭环,其中分析报表则由算法工程师或策略工程师进行分析,调整推荐策略,最后再投入到线上推荐中。

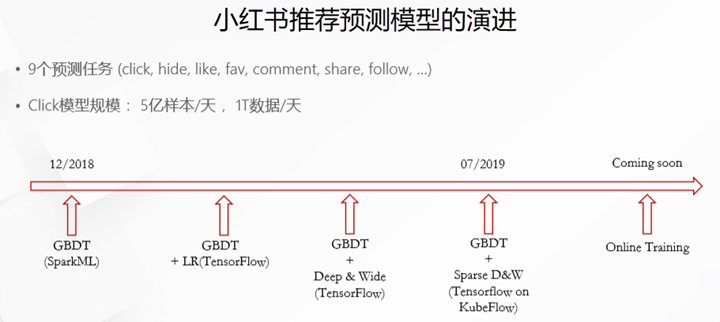
 2018年12月,小红书的推荐预测模型只是非常简单的Spark上的GBDT模型。后期在GBDT模型上加了LR层,后来还引入了Deep和Wide。到2019年7月,小红书推荐预测模型已经演化到了GBDT+SparseD&W的模型。小红书主要有9个预测任务,包括click、hide、like、fav、comment、share以及follow等。其中,Click是小红书最大的模型。
2018年12月,小红书的推荐预测模型只是非常简单的Spark上的GBDT模型。后期在GBDT模型上加了LR层,后来还引入了Deep和Wide。到2019年7月,小红书推荐预测模型已经演化到了GBDT+SparseD&W的模型。小红书主要有9个预测任务,包括click、hide、like、fav、comment、share以及follow等。其中,Click是小红书最大的模型。
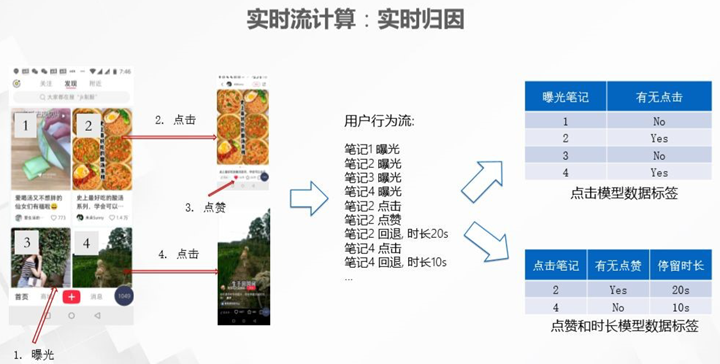
实时归因
实时归因将笔记推荐给用户后会产生曝光,随即产生打点信息,用户笔记的每一次曝光、点击、查看和回退都会被记录下来。如下图所示,四次曝光的用户行为会产生四个笔记曝光。如果用户点击第二篇笔记,则产生第二篇笔记的点击信息,点赞会产生点赞的打点信息;如果用户回退就会显示用户在第二篇笔记停留了20秒。实时归因会生成两份数据,第一份是点击模型的数据标签,在下图中,第一篇笔记和第三篇笔记没有点击,第二篇笔记和第四篇笔记有点击,这类数据对于训练点击模型至关重要。同样,点赞模型需要点击笔记数据,比如用户点击了第二篇笔记并发生点赞,反之点击了第四篇笔记但没有点赞,时长模型需要点击之后停留的时间数据。以上提到的数据需要与上下文关联,产生一组数据,作为模型分析和模型训练的原始数据。
参考链接:


