TexSmart 简介
TexSmart是由腾讯人工智能实验室的自然语言处理团队开发的一套自然语言理解工具与服务,用以对中文和英文两种语言的文本进行词法、句法和语义分析。除了支持分词、词性标注、命名实体识别(NER)、句法分析、语义角色标注等常见功能外,TexSmart 还提供细粒度命名实体识别、语义联想、深度语义表达等特色功能。文本理解技术广泛应用于搜索、个性化推荐、广告匹配、智能对话等场景,用来对自然语言文本进行结构化分析与处理。
相比目前公开的自然语言处理工具,TexSmart 系统具有以下特色。
特色 1:细粒度命名实体识别
TexSmart 支持上千种实体类型,类型之间具有层级结构,而目前多数公开的文本理解工具只支持人、地点、机构等几种或者十几种(粗粒度的)实体类型。大规模细粒度的实体类型有望为下游的 NLP 应用提供更为丰富的语义信息。
TexSmart 与现有开源文本理解工具在一个示例中文句子上的对比。输入文本为:”上个月 30 号,南昌王先生在自己家里边看流浪地球边吃煲仔饭。”


可以看到,TexSmart 识别了更多类型的实体(如电影、食物等),支持更细粒度的实体类型标注(如把”南昌”的类型从”地点”细化为”城市”)。
TexSmart 能够识别的实体类型包括人、地点、机构、产品、商标、作品、时间、数值、生物、食物、药品、病症、学科、语言、天体、器官、事件、活动等上千种。在常见的人、地点、机构等大类中,能够识别出常见的细粒度子类型,如演员、政治人物、运动员、国家、城市、公司、大学、金融机构等。
特色 2:增强的语义理解功能
除了细粒度命名实体识别之外,TexSmart 还提供了两项增强的语义理解功能:语义联想和针对特定类型实体的深度语义表达。这两个功能是多数现有的开源文本理解系统所不具备的。
语义联想
语义联想的功能是,对句子中的实体,给出与其相关的一个实体列表。语义联想是增强理解实体语义的一种方式,它在工业界有着广泛的应用,比如搜索和推荐。在上述例子中,TexSmart 可以从”流浪地球”这一部作品,联想到其它的影视剧如”战狼二”、”上海堡垒”等;从”煲仔饭”联想到其它的食物如”兰州拉面”,”热干面”等。
特定类型实体的深度语义表达
针对时间、数量等特定类型的实体,TexSmart 能够分析它们潜在的结构化表达,以便进一步推导出这些实体的精准语义。例如在图 1 的例子中,TexSmart 对”上个月 30 号”给出的深度语义表达为 JSON 格式:{“value”:[2020,3,30]}。深度语义理解对某些类型的 NLP 应用至关重要,比如在智能对话中,某用户于 2020 年 4 月 20 日向对话系统发出请求,”帮我预定一张后天下午四点去北京的机票”。智能对话系统不但需要知道”后天下午四点”是一个时间实体,还需要知道这个实体的语义是”2020 年 4 月 22 日 16 点”。目前大多数公开的 NLP 工具不提供这样的深度语义表达功能,需要应用层自己去实现。
特色 3:为多维度应用需求而设计
学术界和工业界不同的应用场景对速度、精度和时效性的要求有所不同,而速度和精度通常是很难兼得的。TexSmart 的目标是在一套系统中尽可能地考虑这三个方面的需求。首先,TexSmart 针对一项功能(比如词性标注或命名实体识别)实现了多种不同速度和精度的算法与模型供上层应用按需选择,以便满足工业界和学术界不同场景下的多样化应用需求。其次,TexSmart 的构建利用了大规模的无结构化数据以及无监督或弱监督方法。一方面这些无结构化数据覆盖大量时效性很强的词和实体(比如上文中的”流浪地球”,再比如新的疾病”新冠肺炎”);另一方面无监督或弱监督方法的采用使得该系统可以以较低的代价进行更新,从而保证它具有较好的时效性。

TexSmart 功能介绍
分词
自动分词(Automatic Word Segmentation)任务是将输入的字符串切分成以单词为单位的序列,并以空格间隔。自动分词是自然语言处理的基础任务,因为分词的结果可作为许多下游任务的输入。为适用于不同的应用场景,TexSmart 提供了两种粒度的自动分词功能支持:基础粒度与复合粒度。它们之间的区别可通过下图可看出。

在基础粒度下,”30″与”号”被切分为两个词;而在复合粒度下,”30 号”这一复合词不再进行更细粒度的切分,被归为一个词。需要说明的是,TexSmart 也支持对英文的分词,基础粒度的分词结果,也即英文的输入,因为英文的输入本身已经按照空格切分了;而复合粒度的分词结果是 TexSmart 特有的,如下图:
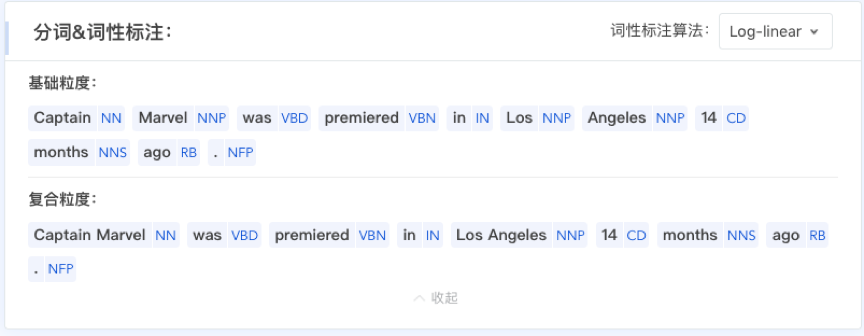
词性标注
词性(Part-of-Speech, POS)是句子中每个单词句法角色的标记,又被称作词类(word classes)或句法范畴(syntactic categories),最常见的词性标签有名词、动词、形容词等。了解一个单词的词性,可以揭示其在语境中的使用规律与搭配习惯;例如,若一个单词为动词,可以推测其前搭配的单词很有可能是名词或代词。
词性标注(POS Tagging)任务是为输入的词序列中的每个单词赋予一个词性标签的过程。上图中除分词结果外,还给出了该句子在不同的分词粒度下得到的每个单词的词性标签。例如在基础粒度下,”30″与”号”分别标注为基数词(CD)和量词(M);而在复合粒度下,”30 号”被标注为时间名词(NT)。TexSmart 支持的中文和英文词性标签集分别是CTB 和 PTB,具体如下:
中文词性标签集合:
| Tag | Description | Example |
| VA | Predicative adjective | 典型[VA]的例子 |
| VC | Copula | 他是[VC]学生 |
| VE | you3 as the main verb | 有[VE]数十人 |
| VV | Other verb | 缩短[VV]了研制周期 |
| NR | Proper Noun | 四川省[NR]政府 |
| NT | Temporal Noun | 十二月[NT] |
| NN | Other Noun | 深圳证券[NN]交易所[NN] |
| LC | Localizer | 八十年代以来[LC] |
| PN | Pronoun | 他[PN]说 |
| DT | Determiner | 这[DT]一成果 |
| CD | Cardinal Number | 一亿[CD] |
| OD | Ordinal Number | 第一[OD] |
| M | Measure word | 三名[M]运动员 |
| AD | Adverb | 十分[AD]重要 |
| P | Preposition | 到[P]目前为止 |
| CC | Coordinating conjunction | 工作或[CC]学习 |
| CS | Subordinating conjunction | 虽然[CS]历经风雨 |
| DEC | de5 as a complementizer or a nominalizer | 重要的[DEC]能源 |
| DEG | de5 as genitive marker and an associative marker | 合作的[DEG]新篇章 |
| DER | Resultative de5 | 他跑得[DER]很快 |
| DEV | Manner de5 | 高兴地[DEV]说 |
| AS | Aspect Particle | 拓宽了[AS]贸易渠道 |
| SP | Sentence-final particle | 他还好吧[SP] |
| ETC | used for word 等 and 等等 | 科技文教等[ETC]领域 |
| MSP | Other particle | 他所[MSP]需要的 |
| IJ | Interjection | 啊[IJ] |
| ON | Onomatopoeia | 雨哗哗[ON]地下 |
| LB | bei4 in long bei-construction | 他被[LB]我训了 |
| SB | bei4 in short bei-construction | 他被[SB]训了 |
| BA | ba3 in ba-construction | 他把[BA]你骗了 |
| JJ | other noun-modifier | 共同[JJ]的目标 |
| FW | Foreign Word | 卡拉OK[FW] |
| PU | Punctuation | ,[PU] |
| EM | Emoticons | 呵呵:)[EM] |
| IC | Typo | – |
| NOI | Grammar error | – |
| URL | URL | tencent.com[URL] |
| X | Multiplication sign | 130x[X]194cm |
英文词性标签集合:
| Tag | Description | Example |
| CC | Coordinating conjuction | and, but |
| CD | Cardinal number | one, 4000 |
| DT | Determiner | the, a |
| EX | Existential “there” | there |
| FW | Foreign word | de facto |
| IN | Preposition or subordinating conjunction | in, of |
| JJ | Adjective | Canadian, many |
| JJR | Adjective, comparative | more, higher |
| JJS | Adjective, superlative | most, best |
| LS | List item marker | a.b.c. |
| MD | Modal | can, will |
| NN | Noun, singular or mass | spokesman, school |
| NNS | Noun, plural | lawyers, skills |
| NNP | Proper noun, singular | Los Angeles, Hurricane Hugo |
| NNPS | Proper noun, plural | Americans, Asians |
| PDT | Predeterminer | all, such |
| POS | Possessive ending | ‘s |
| PRP | Personal pronoun | he, she |
| PRP$ | Possessive pronoun | his, her |
| RB | Adverb | ultimately, generally |
| RBR | Adverb, comparative | earlier, further |
| RBS | Adverb, superlative | most, least |
| RP | Particle | through, off |
| SYM | Symbol | /, – |
| TO | “to” | to |
| UH | Interjection | Hello, Well |
| VB | Verb, base form | make, draw |
| VBD | Verb, past tense | was, had |
| VBG | Verb, gerund or present participle | going, getting |
| VBN | Verb, past participle | been, taken |
| VBP | Verb, non-3rd person singular present | are, have |
| VBZ | Verb, 3rd person singular present | is, has |
| WDT | Wh-determiner | which, that |
| WP | Wh-pronoun | who, what |
| WP$ | Possessive wh-pronoun | whose |
| WRB | Wh-adverb | where, when |
| $ | Dollar symbol | $ |
| “ | Double quotes | “ |
| , | Comma | , |
| -LRB- | Left round bracket | ( |
| -RRB- | Right round bracket | ) |
| . | Period | . |
| : | Colon | : |
| AFX | Unbound affix | non |
| HYPH | Unbound hyphen | – |
| NFP | Non-functional (superfluous or decorative) punctuation | /* |
| “ | Double quotes | “ |
TexSmart 实现了三种词性标注算法:对数线性模型(Log-Linear Model)、条件随机场模型(Conditional Random Field, CRF)与深度神经网络(Deep Neural Network, DNN)。在网页版 demo 中,用户可以通过上图中的”词性标注算法”下拉框切换不同的算法;在调用 HTTP API 的时候,也可以进行算法选择,三个算法的名字分别为:log_linear、crf、dnn。
命名实体识别(NER)
命名实体(Named Entity)是指自然语言句子或篇章中拥有名字的实体,粗略来讲,例如:一个人、一个地点或一个机构则对应了其人名、地名与机构名。命名实体识别(Named Entity Recognition, NER)任务是将上述不同类别的实体识别出来的过程,具体来讲,即为输入的单词序列打上不同的命名实体的类别标签。NER 任务对于文本分析、信息抽取、知识图谱构建等下游任务是不可或缺的;其在信息检索与电商领域已经充分部署,近年来也应用于许多科技前沿领域,例如生物、医疗大数据的信息处理与知识挖掘。
TexSmart 提供粗粒度与细粒度两种模式下的命名实体识别功能:粗粒度 NER 采用有监督学习方法,提供两种不同模型(CRF 与 DNN),用于识别人名、地名、机构名等命名实体;细粒度 NER 则采用有监督和无监督相结合的方法,可以识别出一千多种细粒度实体。
中文粗粒度 NER 的实体类型:
| Tag | Description | Example |
| person.generic | 人物,既包括实际存在的人,也包括出现于作品或传说中的角色、神仙鬼怪等 | 刘德华、孙悟空、王先生 |
| loc.generic | 地点,包括国家、行政区(省市县区镇等)、山脉河流、景点等 | 俄罗斯、南山区、科技路、黄河、喜马拉雅山、故宫、火星、中东 |
| org.generic | 机构,包括公司、学校、政府机构、运动队、俱乐部、乐队等 | 中国驻美大使馆、腾讯、清华大学、曼联、湖南卫视 |
| product.generic | 产品,包括车、数码电子、工具、衣服、游戏、软件等 | 华为 Mate20、牛仔裤、锄头、王者荣耀 |
| work.generic | 作品,包括小说、散文、诗词、电影、音乐、绘画、雕塑、戏剧、民间传说等 | 红楼梦、流浪地球、乱世佳人、望庐山瀑布 |
| life.organism | 生物,包括动物、植物、微生物等 | 狗、蜜蜂、柳树、草履虫 |
| food.generic | 食物,包括食品、饮料、水果、蔬菜、菜名等 | 柠檬汁、大米、香蕉、芹菜、鱼香肉丝 |
| medicine | 医药相关实体,包括疾病、药物、症状等 | 新冠肺炎、头孢、皮肤红肿 |
| event.generic | 事件,包括历史事件、国际会议、体育赛事等 | 第二次世界大战、亚洲羽毛球锦标赛 |
| quantity.generic | 数量,包括数值、数值加单位、数值加量词、数量范围、序数词等 | 2 万、三米五、一百匹、三到五个、一些 |
| time.generic | 时间,包括日期、节日、时长、岁数等 | 9 月中旬、上星期三、五年、12 岁、今天 |
| other | 其他实体,如星座、语言、颜色、技术等 | 摩羯座、汉语、C++、红色、自然语言处理 |
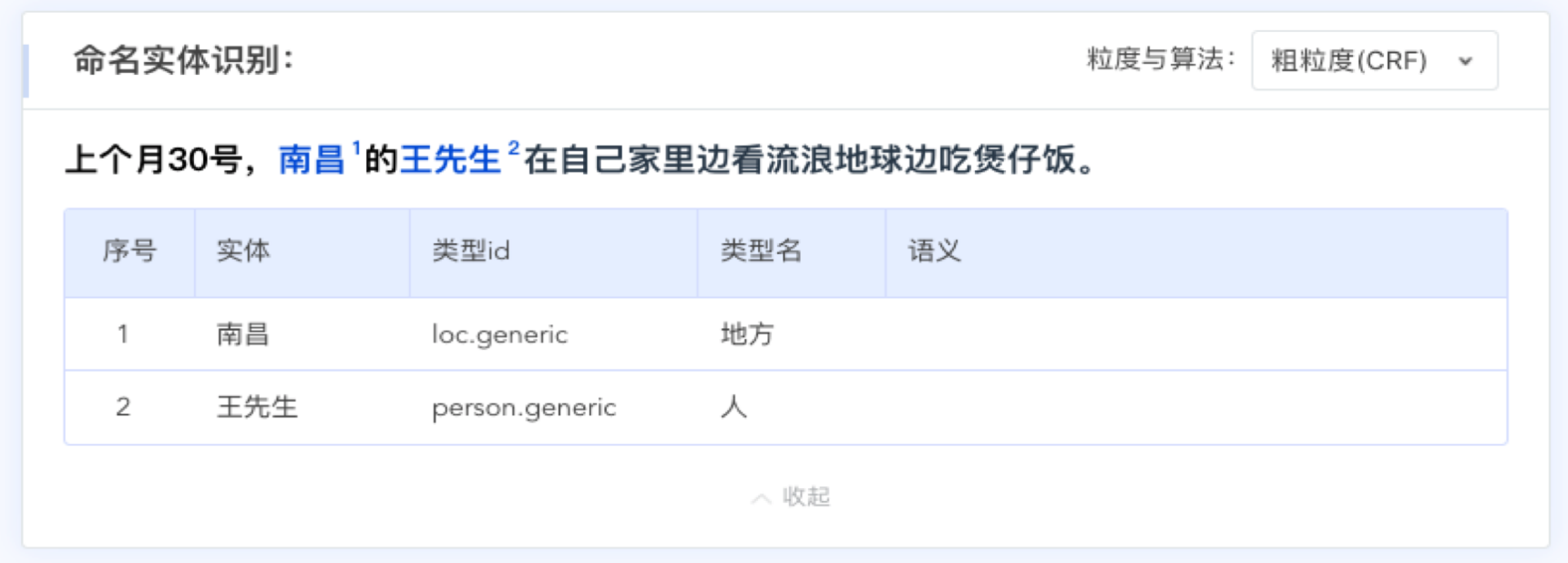
上图为例句在粗粒度模式下命名实体识别的结果,识别出地名“南昌”与人名“王先生”两种类型名。下图为例句在细粒度模式下命名实体识别的结果,可以看到,更丰富的实体类型名被识别出来,“城市”、“电影”、“食物”;除此之外,TexSmart还给出该命名实体对应的其他相关命名实体,进行实体联想,如“流浪地球”对应的“战狼二”、“上海堡垒”等。

成分句法分析
成分句法分析(Constituency Parsing)是基于语言学家乔姆斯基提出的短语结构文法(Phrase Structure Grammar)将输入的单词序列组合成一棵短语结构树的过程。所谓短语结构,例如下图中“南昌”、“王先生”所组成的名词短语(Noun Phrase, NP),或“边”、“吃”、“煲仔饭”所组成的动词短语(Verb Phrase, VP)等。
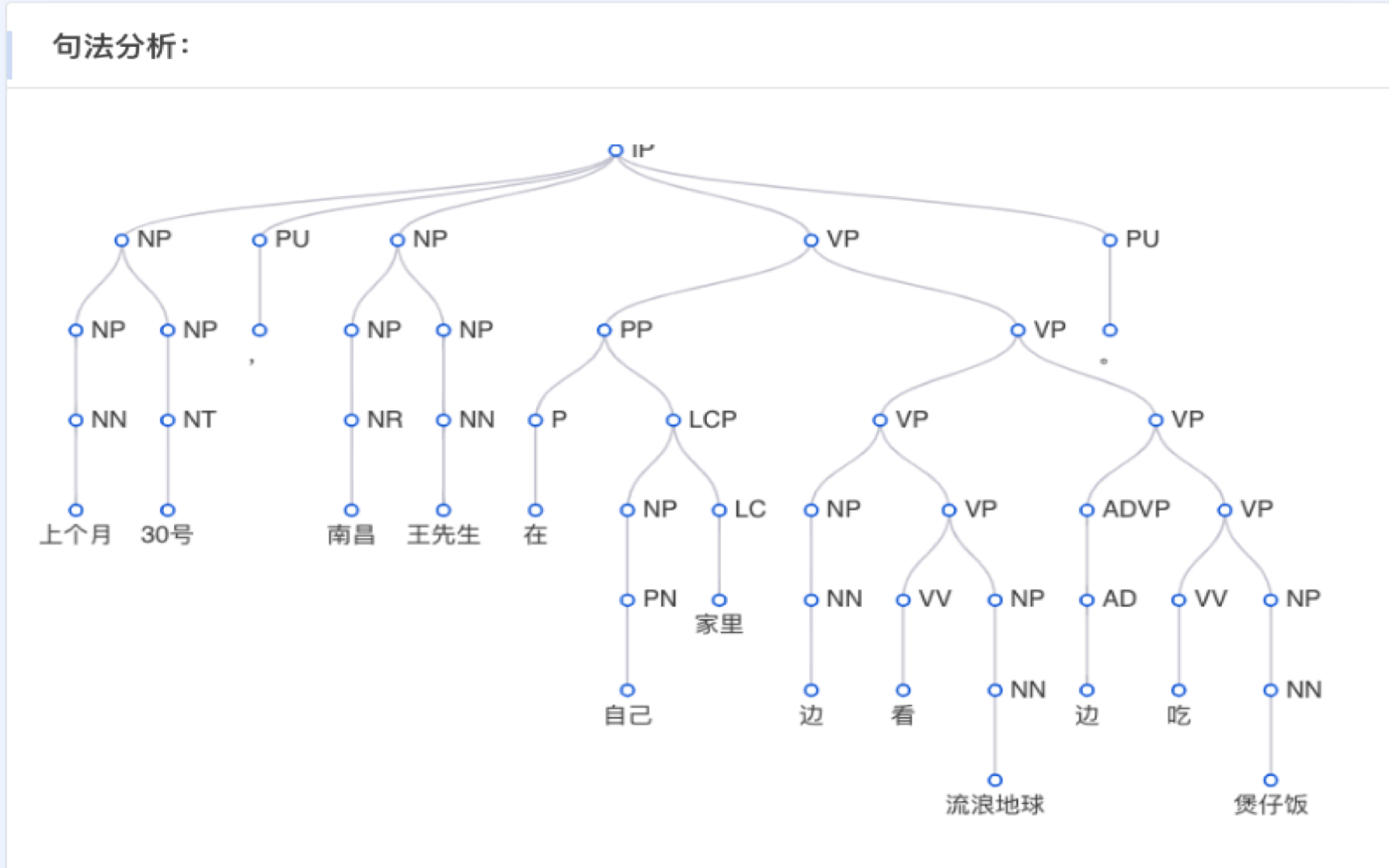
成分句法树的叶子结点为输入句子的每一个单词;叶子节点的上一层是每个单词的词性标签;往树的根节点移动,则是所构成的短语结构的名称,中英文上的短语结构标签(CTB和PTB标准)。
中文短语结构标签:
| Label | Description | Example |
| ADJP | adjective phrase (形容词短语) | 现代 |
| ADVP | adverb phrase (副词短语) | 尽快 |
| CLP | classifier phrase (量词短语) | 平方公里 |
| CP | clause headed by C (complementizer) (以标句词为首的短语) | 恢复法律和秩序 |
| DNP | phrase formed by “XP+DEG” (由某类短语和DEG类词构成的短语) | 此次访问的 |
| DP | determiner phrase (限定短语) | 此次 |
| DVP | phrase formed by “XP+DEV” (由某类短语和DEV类词构成的短语) | 更加广泛地 |
| FRAG | fragment (片段/碎片) | (闽东南热线) |
| IP | simple clause headed by INFL (以INFL为首的简单小句) | 质量先进 |
| LCP | phrase formed by “XP+LC” (由某类短语和LC类词构成的短语) | 大连市出口商品结构中 |
| LST | list marker (列表标记符) | 1) |
| NP | noun phrase (名词短语) | 开发与法制建设 |
| PP | prepositional phrase (介词短语) | 比去年同期 |
| PRN | parenthetical (圆括号) | ( |
| QP | quantifier phrase (数词短语) | 百分之三十二点五 |
| UCP | unidentical coordination phrase (不可识别的并列短语) | 标题及一段中 |
| VP | verb phrase (动词短语) | 出现无序现象 |
英文短语结构标签:
| Label | Description | Example |
| ADJP | Adjective phrase (形容词短语) | fareastern |
| ADVP | Adverb phrase (副词短语) | sovaguely |
| NP | Noun phrase (名词短语) | moneymanagers |
| PP | Prepositional phrase (介词短语) | asawhole |
| S | Simple declarative clause (简单陈述小句) | thenpollinatethemale-sterileplants |
| SBAR | Subordinate clause (从属小句) | tostayout |
| SBARQ | Direct question introduced by wh-element (wh开头的直接疑问句) | What’shedoing |
| SINV | Declarative sentence with subject-aux inversion (带主语-限定助动词倒装的陈述句) | |
| SQ | Yes/no questions and subconstituent of SBARQ excluding wh-element (是非疑问句和SBARQ中除去wh词的子成分) | (How)couldhebe |
| VP | Verb phrase (动词短语) | wereinthe1960s |
| WHADVP | Wh-adverb phrase (wh-副词短语) | how |
| WHNP | Wh-noun phrase (wh-名词短语) | that,which |
| WHPP | Wh-prepositional phrase (wh-介词短语) | inwhich |
| X | Constituent of unknown or uncertain category (类别未知或不定的组分) | until mid-November |
| * | “Understood” subject of infinitive or imperative (不定式或祈使句里的默认主语) | |
| 0 | Zero variant of that in subordinate clauses (从属小句中省略的that) | |
| T | Trace of wh-Constituent (wh组分的句法位移迹) |
TexSmart中的成分句法分析采用的是伯克利大学发表在ACL 2018的基于自注意力机制(self-attention)的模型,该模型取得优异的性能并且搜索复杂度很低,我们在底层采用预训练过的BERT模型提供特征进一步提升模型的鲁棒性。
语义角色标注
自然语言的语义理解往往包括分析构成一个事件的行为、施事、受事等主要元素,以及其他附属元素(adjuncts),例如事件发生的时间、地点、方式等。在事件语义学(Event semantics)中,构成一个事件的各个元素被称为语义角色(Semantic Roles);而语义角色标注(Semantic Role Labeling)任务就是识别出一个句子中所有的事件及其组成元素的过程,例如:其行为(往往是句子中的谓词部分),施事,事件,地点等。下图中,例子中的两个事件”看”和”吃”均被识别出来,而”看”对应的施事”南昌的王先生”和受事”流浪地球”以及附属的事件发生的时间”上个月30号”和地点”在自己家里”均被准确标注出来。语义角色标注可为许多下游任务提供支持,例如:更深层的语义分析(AMR Parsing,CCG Parsing等),任务型对话系统中的意图识别,事实类问答系统中的实体打分等。

TexSmart同样支持中文与英文文本上的语义角色标注。
中文语义角色标注标签集合:
| ADV | adverbial, default tag (附加的,默认标记) |
| BNE | beneficiary (受益人) |
| CND | condition (条件) |
| DIR | direction (方向) |
| DGR | degree (程度) |
| EXT | extent (扩展) |
| FRQ | frequency (频率) |
| LOC | locative (地点) |
| MNR | manner (方式) |
| PRP | purpose or reason (目的或原因) |
| TMP | temporal (时间) |
| TPC | topic (主题) |
| CRD | coordinated arguments (并列参数) |
| PRD | predicate (谓语动词) |
| PSR | possessor (持有者) |
英文语义角色标注标签集合:
| Core semantic role | Arg0 | Agent, Experiencer |
| Arg1 | Theme, Topic, Patient | |
| Arg2 | Recipient, Extent, Predicate | |
| Arg3 | Asset, Theme2, Recipient | |
| Arg4 | Beneficiary | |
| Arg5 | Destination | |
| Adjunctive semantic role | ArgM-ADV | Adverbials (附加的) |
| ArgM-BNE | Beneficiary (受益者) | |
| ArgM-CND | Condition (条件) | |
| ArgM-DIR | Direction (方向) | |
| ArgM-DGR | Degree (程度) | |
| ArgM-EXT | Extent (延展) | |
| ArgM-TMP | Temporal (时间) | |
| ArgM-TPC | Topic (主题) | |
| ArgM-PRP | Purpose or Reason (目的或原因) | |
| ArgM-FRQ | Frequency (频率) | |
| ArgM-LOC | Locative (方位) | |
| ArgM-MNR | Manner (方式) |
TexSmart采用了基于BERT的自注意力神经网络模型(self-attention)来进行语义角色标注。
TexSmart技术方案简介
对于分词、词性标注、句法分析等较为成熟的NLP任务,TexSmart实现了多种代表性的方法:
- John Lafferty, Andrew McCallum, and Fernando Pereira. Conditional random fields: Probabilistic models for segmenting and labeling sequence data, ICML 2001.
- Alan Akbik, Duncan Blythe, and Roland Vollgraf. Contextual String Embeddings for Sequence Labeling. COLING 2018.
- Nikita Kitaev and Dan Klein. Constituency Parsing with a Self-Attentive Encoder. ACL 2018.
- Peng Shi and Jimmy Lin. Simple BERT Models for Relation Extraction and Semantic Role Labeling. Arxiv 2019.
下面将简要地介绍其特色功能的技术实现。
细粒度命名实体识别
现有的命名实体识别(NER)系统大多依赖于一个带有粗粒度实体类型标注的人工标注数据集来作为训练集。而TexSmart中的实体类型多达千种,人工标注一个带有全部类型标注的训练集是非常耗时的。为减少人工标注量,该模块采用了一种混合(hybrid)方法,它是如下三种方法的融合:
- 无监督的细粒度实体识别方法,基于两类数据:
- 从腾讯AI Lab所维护的知识图谱TopBase中所导出的实体名到类型的映射表;
- Marti A. Hearst. Automatic Acquisition of Hyponyms from Large Text Corpora. ACL 1992.
- Fan Zhang, Shuming Shi, Jing Liu, Shuqi Sun, Chin-Yew Lin. Nonlinear Evidence Fusion and Propagation for Hyponymy Relation Mining. ACL 2011.
采用以下文献中的无监督方法从大规模文本数据中所抽取到的词语上下位关系信息:
- 有监督的序列标注模型,基于一个经过人工标注的包含十几种粗粒度实体类型的数据集所训练而成。
- 腾讯AI Lab在国际大赛夺冠的实体链接方法。
这三种方法的结果都会有一些错误和缺陷,实验证明三种方法结合起来能够达到更好的效果。
语义联想
上下文相关的语义联想(context-aware semantic expansion,简称CASE)是腾讯AI Lab从工业应用中抽象出的一个新NLP任务[Jialong Han, Aixin Sun, Haisong Zhang, Chenliang Li, and Shuming Shi. CASE: Context-Aware Semantic Expansion. AAAI 2020.]。该任务的难点在于缺乏有标注的训练数据。该模块采用了两种方法来构建语义联想模型。
- 第一种方法结合词向量技术、分布相似度技术和模板匹配技术来产生一个语义相似度图,然后利用相似度图和上下文信息来产生相关的实体集合。
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. NIPS 2013.
- Yan Song, Shuming Shi, Jing Li, and Haisong Zhang. Directional Skip-Gram: Explicitly Distinguishing Left and Right Context for Word Embeddings. NAACL 2018.
- Shuming Shi, Huibin Zhang, Xiaojie Yuan, and Ji-Rong Wen. Corpus-based Semantic Class Mining: Distributional vs. Pattern-Based Approaches. COLING 2010.
- 另一种方法是基于大规模的无结构化数据构建一个规模相当的伪标注数据集,并训练一个充分考虑上下文的神经网络模型。
特定类型实体的深度语义表达
对于时间和数量两种实体,TexSmart可以推导出它们具体的语义表达。一些NLP工具利用正则表达式或者有监督的序列标注方法来识别时间和数量实体。但是,这些方法很难推导出实体的结构化语义信息。为了克服这个问题,该模块的实现采用了比正则表达式表达能力更强的上下文无关文法(CFG)。基本流程是:先根据特定类型实体的自然语言表达格式来编写CFG的产生式,然后利用Earley算法[Jay Earley. An Efficient Context-Free Parsing Algorithm. Communications of the ACM, 13(2), 94-102, 1970.]来把表示这种实体的自然语言文本解析为一棵语法树,最后通过遍历语法树来生成实体的深度语义表达。
TexSmart的使用
系统说明
TexSmart提供了HTTP API调用和离线SDK两种使用方式。请注意,对于同样的文本输入,这两种方式的解析结果可能会有区别。这是因为HTTP API版本采用了更大的知识库,并支持更多的文本理解任务和算法。两种形态的对比如下:
| 离线工具包 | HTTP API | ||
| 功能 | 分词 | 无监督分词算法 | 无监督分词算法 |
| 词性标注 | log-linear算法 | 算法:log-linear, CRF, DNN | |
| 粗粒度NER | CRF算法 | 算法:CRF, DNN | |
| 细粒度NER | 基于小知识库的std算法 | 基于大知识库的std算法 | |
| 句法分析 | 不支持 | 支持 | |
| 语义角色标注 | 不支持 | 支持 | |
| 语义联想 | 基于小知识库的std算法 | 基于大知识库的std算法 | |
| 深度语义表达 | 上下文无关文法 | 上下文无关文法 | |
| 知识库大小 | 小 | 大 | |
| 支持的自然语言 | 中文、英文 | 中文、英文 | |
相关链接:
Python调用示例:
#-*- encoding=utf-8 -*-
import sys
lib_dir = r'D:\texsmart\lib'
data_dir = r'D:\texsmart\data'
sys.path.append(lib_dir)
# tencent_ai_texsmart 直接能从上面的 sys.path.append(lib_dir) 中导入,无需安装对应的包
from tencent_ai_texsmart import *
print('Stdout encoding: ' + sys.stdout.encoding)
print('Creating and initializing the NLU engine...')
engine = NluEngine(data_dir + '/nlu/kb/', 1)
# disable fine-grained NER:
print('Options: Enable NER but disable fine-grained NER')
options = '{"ner": {"enable": true, "fine_grained": false}}'
print(u'===解析一个中文句子===')
output = engine.parse_text_ext(u"上个月30号,南昌王先生在自己家里边看流浪地球边吃煲仔饭", options)
print(u'Norm text: {0}'.format(output.norm_text()))
print(u'细粒度分词:')
for item in output.words():
print(u'\t{0}\t{1}\t{2}\t{3}'.format(item.str, item.offset, item.len, item.tag))
print(u'粗粒度分词:')
for item in output.phrases():
print(u'\t{0}\t{1}\t{2}\t{3}'.format(item.str, item.offset, item.len, item.tag))
print(u'命名实体识别(NER):')
for entity in output.entities():
print(u'\t{0}\t({1},{2})\t{3}\t{4}'.format(entity.str, entity.offset, entity.len, entity.type.name, entity.meaning))
参考链接:


