如何比较两篇文章的相似度在互联网搜索引擎层面使用的非常广泛,试想,如果不进行类似的比较,在当前互联网信息抄来抄去的情况下,搜索引擎结果页排在前面的结果可能都是相似的内容。Google为了避免出现上述的问题,在WWW07的论文Detecting Near-Duplicates for Web Crawling基础上整出了simhash。
simhash的背景
常见的余弦夹角算法、欧式距离、Jaccard相似度、最长公共子串、编辑距离等。这些算法对于待比较的文本数据不多时还比较好用,如果我们的每天采集的数据以千万计算,性能就是一个非常大的瓶颈。传统的hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上相当于伪随机数产生算法。传统的hash算法产生的两个签名,如果相等,说明原始内容在一定概率下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别极大。所以hash算法只适合相同性的检测而不适合相似性检测。理想当中的hash函数,需要对几乎相同的输入内容,产生相同或者相近的hash值,换言之,hash值的相似程度要能直接反映输入内容的相似程度,故md5等传统hash方法也无法满足我们的需求。
simhash算法的原理
simhash是一种能计算文档相似度的hash算法。通过simhash能将一篇文章映射成64bit,再比较两篇文章的64bit的海明距离,就能知道文章的相似程序。若两篇文章的海明距离<=3,可认为这两篇文章很相近,可认为它们是重复的文章。
simhash作为locality sensitive hash(局部敏感哈希)的一种,其主要思想是降维,将高维的特征向量映射成低维的特征向量(把文档降维到hash数字),通过两个向量的海明距离来确定文章是否重复或者高度近似。在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。也就是说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:1011101与1001001之间的汉明距离是2。至于我们常说的字符串编辑距离则是一般形式的海明距离。如此,通过比较多个文档的simHash值的海明距离,可以获取它们的相似度。
simhash算法分为5个步骤:分词、hash、加权、合并、降维,具体过程如下所述:
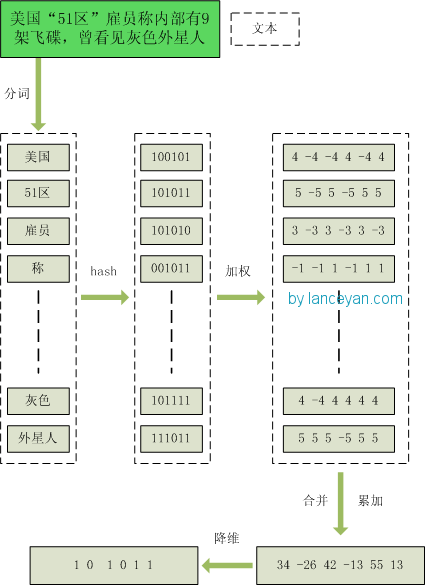
- 分词。把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:”美国”51区”雇员称内部有9架飞碟,曾看见灰色外星人”==>分词后为”美国(4)51区(5)雇员(3)称(1)内部(2)有(1)9架(3)飞碟(5)曾(1)看见(3)灰色(4)外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
- hash。通过hash算法把每个词变成hash值,比如”美国”通过hash算法计算为100101,”51区”通过hash算法计算为101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
- 加权。通过2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如”美国”的hash值为”100101″,通过加权计算为”4 -4 -4 4 -4 4″;”51区”的hash值为”101011″,通过加权计算为”5 -5 5 -5 5 5″。
- 合并。把上面各个单词算出来的序列值累加,变成只有一个序列串。比如”美国”的”4 -4 -4 4 -4 4″,”51区”的”5 -5 5 -5 5 5″,把每一位进行累加,”4+5 -4+-5 -4+5 4+-5 -4+5 4+5″==》”9 -9 1 -1 1 9″。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
- 降维。把4步算出来的”9 -9 1 -1 1 9″变成01串,形成我们最终的simhash签名。如果每一位大于0记为1,小于0记为0。最后算出结果为:”101011″。
相关工具:
- https://github.com/yanyiwu/simhash
- https://github.com/zyymax/text-similarity
- https://github.com/lrcUnlimited/check_file_system
其他算法:
- 百度的去重算法(直接找出此文章的最长的n句话,做一遍hash签名。n一般取3。工程实现巨简单,据说准确率和召回率都能到达80%以上。)
- shingle算法
- Minhash and LSH
参考文章:



想问一下 , 分词的词的重要程度是怎么决定的呢?
比较简单的方法可以用tf-idf