Requests 库是用来在 Python 中发出标准的 HTTP 请求。它将请求背后的复杂性抽象成一个漂亮,简单的 API,以便你可以专注于与服务交互和在应用程序中使用数据。

Requests POST/GET 参数
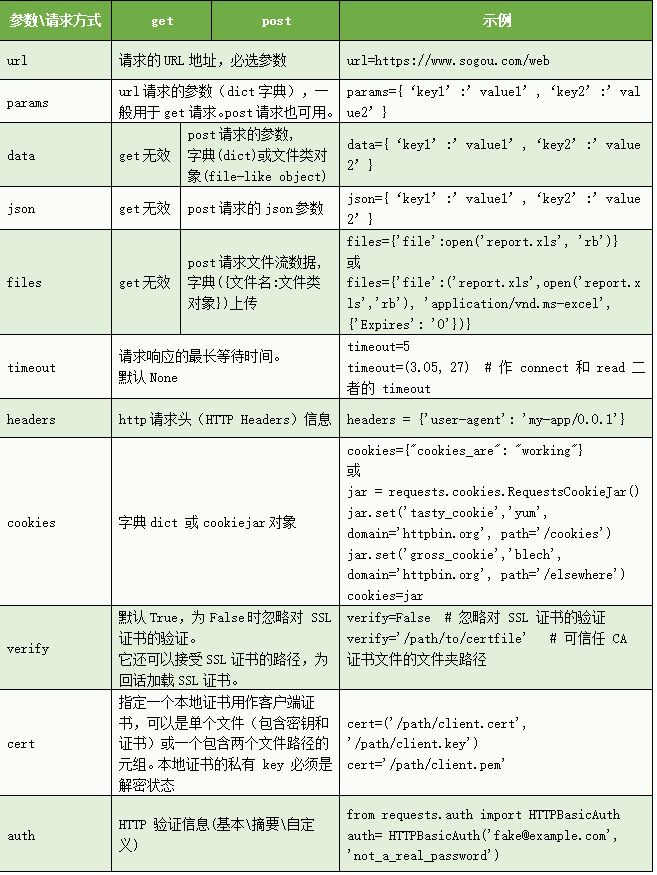
常用参数见下表:
Requests 返回对象 Response 常用方法
Response 响应类常用属性与方法:
Response.url 请求 url,[见示例 2.1]
Response.status_code 响应状态码,[见示例 2.1]
Response.text 获取响应内容,[见示例 2.1]
Response.json() 活动响应的 JSON 内容,[见示例 2.1]
Response.ok 请求是否成功,status_code < 400 返回 True
Response.headers 响应 header 信息,[见示例 2.1]
Response.cookies 响应的 cookie,[见示例 2.1]
Response.elapsed 请求响应的时间。
Response.links 返回响应头部的 links 连接,相当于 Response.headers.get('link')
Response.raw 获取原始套接字响应,需要将初始请求参数 stream=True
Response.content 以字节形式获取响应提,多用于非文本请求,[见示例 2.2]
Response.iter_content() 迭代获取响应数据,[见示例 2.2]
Response.history 重定向请求历史记录
Response.reason 响应状态的文本原因,如:"Not Found" or "OK"
Response.close() 关闭并释放链接,释放后不能再次访问’raw’对象。一般不会调用。
Requests 请求失败重试设置
在使用 requests 抓取数据时,经常遇到连接超时的问题,为了让程序更加稳健,需要对 requests 请求实现失败重试的逻辑。前面介绍过Python 中异常重试解决方案。今天要介绍的是 Requests 自带的失败重试机制。具体设置如下:
import requests
from requests.adapters import HTTPAdapter
s = requests.Session()
s.mount('http://', HTTPAdapter(max_retries=3))
s.mount('https://', HTTPAdapter(max_retries=3))
s.get('http://example.com', timeout=5)
通过对源码的解读可以大概了解其实现机制:
class HTTPAdapter(BaseAdapter):
"""The built-in HTTP Adapter for urllib3.
:param max_retries: The maximum number of retries each connection
should attempt. Note, this applies only to failed DNS lookups, socket
connections and connection timeouts, never to requests where data has
made it to the server. By default, Requests does not retry failed
connections. If you need granular control over the conditions under
which we retry a request, import urllib3's ``Retry`` class and pass
that instead.
Usage::
>>> import requests
>>> s = requests.Session()
>>> a = requests.adapters.HTTPAdapter(max_retries=3)
>>> s.mount('http://', a)
"""
__attrs__ = ['max_retries', 'config', '_pool_connections', '_pool_maxsize',
'_pool_block']
def __init__(self, pool_connections=DEFAULT_POOLSIZE,
pool_maxsize=DEFAULT_POOLSIZE, max_retries=DEFAULT_RETRIES,
pool_block=DEFAULT_POOLBLOCK):
if max_retries == DEFAULT_RETRIES:
self.max_retries = Retry(0, read=False)
else:
self.max_retries = Retry.from_int(max_retries)
class Retry(object):
"""Retry configuration.
Each retry attempt will create a new Retry object with updated values, so
they can be safely reused.
Retries can be defined as a default for a pool::
retries = Retry(connect=5, read=2, redirect=5)
http = PoolManager(retries=retries)
response = http.request('GET', 'http://example.com/')
Or per-request (which overrides the default for the pool)::
response = http.request('GET', 'http://example.com/', retries=Retry(10))
Retries can be disabled by passing ``False``::
response = http.request('GET', 'http://example.com/', retries=False)
Errors will be wrapped in :class:`~urllib3.exceptions.MaxRetryError` unless
retries are disabled, in which case the causing exception will be raised.
:param int total:
Total number of retries to allow. Takes precedence over other counts.
Set to ``None`` to remove this constraint and fallback on other
counts. It's a good idea to set this to some sensibly-high value to
account for unexpected edge cases and avoid infinite retry loops.
Set to ``0`` to fail on the first retry.
Set to ``False`` to disable and imply ``raise_on_redirect=False``.
....
:param iterable method_whitelist:
Set of uppercased HTTP method verbs that we should retry on.
By default, we only retry on methods which are considered to be
indempotent (multiple requests with the same parameters end with the
same state). See :attr:`Retry.DEFAULT_METHOD_WHITELIST`.
:param iterable status_forcelist:
A set of HTTP status codes that we should force a retry on.
By default, this is disabled with ``None``.
:param float backoff_factor:
A backoff factor to apply between attempts. urllib3 will sleep for::
{backoff factor} * (2 ^ ({number of total retries} - 1))
seconds. If the backoff_factor is 0.1, then :func:`.sleep` will sleep
for [0.1s, 0.2s, 0.4s, ...] between retries. It will never be longer
than :attr:`Retry.BACKOFF_MAX`.
By default, backoff is disabled (set to 0).
"""
DEFAULT_METHOD_WHITELIST = frozenset([
'HEAD', 'GET', 'PUT', 'DELETE', 'OPTIONS', 'TRACE'])
#: Maximum backoff time.
BACKOFF_MAX = 120
def __init__(self, total=10, connect=None, read=None, redirect=None,
method_whitelist=DEFAULT_METHOD_WHITELIST, status_forcelist=None,
backoff_factor=0, raise_on_redirect=True, raise_on_status=True,
_observed_errors=0):
self.total = total
self.connect = connect
self.read = read
if redirect is False or total is False:
redirect = 0
raise_on_redirect = False
self.redirect = redirect
self.status_forcelist = status_forcelist or set()
self.method_whitelist = method_whitelist
self.backoff_factor = backoff_factor
self.raise_on_redirect = raise_on_redirect
self.raise_on_status = raise_on_status
self._observed_errors = _observed_errors # TODO: use .history instead?
def get_backoff_time(self):
"""Formula for computing the current backoff
:rtype: float
"""
if self._observed_errors <= 1:
return 0
#重试算法,_observed_erros就是第几次重试,每次失败这个值就+1.
#backoff_factor=0.1,重试的间隔为[0.1,0.2,0.4,0.8,...,BACKOFF_MAX(120)]
backoff_value = self.backoff_factor * (2 ** (self._observed_errors - 1))
return min(self.BACKOFF_MAX, backoff_value)
def sleep(self):
"""Sleep between retry attempts using an exponential backoff.
By default, the backoff factor is 0 and this method will return
immediately.
"""
backoff = self.get_backoff_time()
if backoff <= 0:
return
time.sleep(backoff)
def is_forced_retry(self, method, status_code):
"""Is this method/status code retryable? (Based on method/codes whitelists)
"""
if self.method_whitelist and method.upper() not in self.method_whitelist:
return False
return self.status_forcelist and status_code in self.status_forcelist
# For backwards compatibility (equivalent to pre-v1.9):
Retry.DEFAULT = Retry(3)
Retry的设计比较简单,在HTTPConnectionPool中根据返回的异常和访问方法,区分是哪种链接失败(connect?read?),然后减少对应的值即可。然后再判断是否所有的操作重试都归零,归零则报MaxRetries异常即可。不过对于每次重试之间的间隔使用了一个简单的backoff算法。
使用重试有几点需要注意:
- 如果使用get等简单形式,默认会重试3次
- 重试只有在DNS解析错误、链接错误、链接超时等异常是才重试。在比如读取超时、写超时、HTTP协议错误等不会重试
- 使用重试会导致返回的错误为MaxRetriesError,而不是确切的异常。
参考链接:
Requests中文编码乱码问题
使用requests时,有时会出现编码错误的问题,导致的主要原因是编码识别出错了。当获取到的内容出现乱码时,最常出现的错误是将编码识别成了ISO-8859-1。
ISO-8859-1是什么?
ISO-8859-1,正式编号为ISO/IEC 8859-1:1998,又称Latin-1或”西欧语言”,是国际标准化组织内ISO/IEC 8859的第一个8位字符集。它以ASCII为基础,在空置的0xA0-0xFF的范围内,加入96个字母及符号,藉以供使用附加符号的拉丁字母语言使用。
为什么会被识别成ISO-8859-1?
通过出错的页面,我们发现即时在HTML中按如下方式已经指明了页面具体的编码还是会出错:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
通过查看源码,可以发现Requests默认的编码识别逻辑非常简单:只要服务器响应头里无法获取到编码信息即默认使用ISO-8859-1,具体逻辑可从Lib\site-packages\requests\utils.py文件中获得:
def get_encoding_from_headers(headers):
"""Returns encodings from given HTTP Header Dict.
:param headers: dictionary to extract encoding from.
"""
content_type = headers.get('content-type')
if not content_type:
return None
content_type, params = cgi.parse_header(content_type)
if 'charset' in params:
return params['charset'].strip("'\"")
if 'text' in content_type:
return 'ISO-8859-1'
从代码中可见:requests会先找HTTP头部的”Content-Type”字段,如果没有,默认的编码格式正是”ISO-8859-1″。代码中并没有去获取HTML页面中指定的编码格式,关于这样的处理,很多人也在官方的issues中提交了吐槽,但是作者回复是严格http协议标准写这个库的,HTTP协议RFC2616中提到,如果HTTP响应中Content-Type字段没有指定charset,则默认页面是’ISO-8859-1’编码。
When you receive a response, Requests makes a guess at the encoding to use for decoding the response when you call the Response.text method. Requests will first check for an encoding in the HTTP header, and if none is present, will use charade to attempt to guess the encoding.
The only time Requests will not do this is if no explicit charset is present in the HTTP headers and the Content-Type header contains text. In this situation, RFC2616 specifies that the default charset must be ISO-8859-1. Requests follows the specification in this case. If you require a different encoding, you can manually set the Response.encoding property, or use the raw Response.content.
找到了乱码的原因后如何解决问题?
如果你知道明确的编码,解决方案非常简单,只需指定具体的编码即可。
resp = requests.get(url) resp.encoding = 'utf-8' print(resp.text)
或对数据进行重编码:
resp = requests.get(url)
print(resp.text.encode(resp.encoding).decode('utf-8'))
当不清楚具体编码的情况下,如何获取准确的页面编码?
其实Requests提供了从HTML内容获取编码,只是在默认中没有使用,见Lib\site-packages\requests\utils.py:
def get_encodings_from_content(content):
"""Returns encodings from given content string.
:param content: bytestring to extract encodings from.
"""
warnings.warn((
'In requests 3.0, get_encodings_from_content will be removed. For'
'more information, please see the discussion on issue #2266. (This'
'warning should only appear once.)'),
DeprecationWarning)
charset_re = re.compile(r'<meta.*?charset=["\']*(.+?)["\'>]', flags=re.I)
pragma_re = re.compile(r'<meta.*?content=["\']*;?charset=(.+?)["\'>]', flags=re.I)
xml_re = re.compile(r'^<\?xml.*?encoding=["\']*(.+?)["\'>]')
return (charset_re.findall(content) +
pragma_re.findall(content) +
xml_re.findall(content))
另外Requests还提供了使用chardet的编码检测,见models.py:
@property
def apparent_encoding(self):
"""The apparent encoding, provided by the chardet library."""
return chardet.detect(self.content)['encoding']
针对这三种方式,识别编码的速率及需要的资源不同:
import requests
import cProfile
r = requests.get("https://www.biaodianfu.com")
def charset_type():
char_type = requests.utils.get_encoding_from_headers(r.headers)
return(char_type)
def charset_content():
charset_content = requests.utils.get_encodings_from_content(r.text)
return charset_content[0]
def charset_det():
charset_det = r.apparent_encoding
return charset_det
if __name__ == '__main__':
cProfile.run("charset_type()")
cProfile.run("charset_content()")
cProfile.run("charset_det()")
charset_type() 25 function calls in 0.000 seconds charset_content() 2137 function calls (2095 primitive calls) in 0.007 seconds charset_det() 292729 function calls (292710 primitive calls) in 0.551 seconds
最终解决方案,创建一个 requests_patch.py 文件,并在代码使用前 import 它,问题即可解决:
# 以下 hack 只适合 Python2
import requests
def monkey_patch():
prop = requests.models.Response.content
def content(self):
_content = prop.fget(self)
if self.encoding == 'ISO-8859-1':
encodings = requests.utils.get_encodings_from_content(_content)
if encodings:
self.encoding = encodings[0]
else:
self.encoding = self.apparent_encoding
_content = _content.decode(self.encoding, 'replace').encode('utf8', 'replace')
self._content = _content
return _content
requests.models.Response.content = property(content)
monkey_patch()
上述代码在 Python3 下执行会报 TypeError: cannot use a string pattern on a bytes-like object 的错误,主要原因是 python3 中 .content 返回的非字符串数据。想在 Python 下获取正确的编码,具体代码如下:
# 此 hack 针对是是 Python3
import requests
def charsets(res):
_charset = requests.utils.get_encoding_from_headers(res.headers)
if _charset == 'ISO-8859-1':
__charset = requests.utils.get_encodings_from_content(res.text)
if __charset:
_charset = __charset[0]
else:
_charset = res.apparent_encoding
return _charset
使用 Requests 下载图片或文件
在使用 Python 进行数据抓取的时候,有时候需要保持文件或图片等,在 Python 中可以有多种方式实现。
使用requests 下载图片或文件
import requests
r = requests.get(url)
with open('./image/logo.png', 'wb') as f:
f.write(r.content)
# Retrieve HTTP meta-data
print(r.status_code)
print(r.headers['content-type'])
print(r.encoding)
from PIL import Image
from io import BytesIO
import requests
# 请求获取图片并保存
r = requests.get(url)
i = Image.open(BytesIO(r.content))
# i.show() # 查看图片
# 将图片保存
with open('img.jpg', 'wb') as fd:
for chunk in r.iter_content():
fd.write(chunk)
使用urlretrieve 方法下载图片或文件
# 已被淘汰,不建议使用 import urllib.request url = 'https://www.baidu.com/img/superlogo_c4d7df0a003d3db9b65e9ef0fe6da1ec.png' urllib.request.urlretrieve(url, './image/logo.png')
使用wget 方法下载图片或文件
# wget 是 Linux 下的一个命令行下载工具,在 Python 中可通过安装对应包后使用。 import wget url = 'https://www.baidu.com/img/superlogo_c4d7df0a003d3db9b65e9ef0fe6da1ec.png' wget.download(url, './image/logo.png')
参考链接:


