在Python中,URL解析库可以在多种场景中使用,以下是一些常见的使用场景:
- Web爬虫和数据抓取:在编写网络爬虫时,需要解析HTML页面中的URL,以便抓取和访问其他页面。需要处理相对URL和绝对URL之间的转换。
- 构建和修改URL:在Web应用程序中,可能需要动态构建URL,比如生成链接或API调用。需要修改URL的不同部分,例如更改查询参数或路径。
- 处理用户输入:在用户输入的URL中提取特定信息,比如域名、路径、查询参数等。验证和标准化用户输入的URL。
- API集成:在与RESTful API集成时,通常需要解析和构建URL来发送请求和处理响应。处理API返回的URL以便进一步操作。
- URL重写和路由:在Web服务器或框架中实现URL重写规则和路由。解析请求URL以确定应该调用哪个视图或控制器。
- SEO和分析:在SEO工具中解析URL以分析链接结构和参数。在分析工具中解析URL以跟踪访问路径和流量来源。
- 安全检查:解析URL以检测和防范常见的安全漏洞,例如URL重定向攻击。验证URL是否符合特定的安全标准或规则。
这些场景展示了URL解析库在不同领域和应用中的重要性和多样性。选择合适的库和方法可以大大简化这些任务。
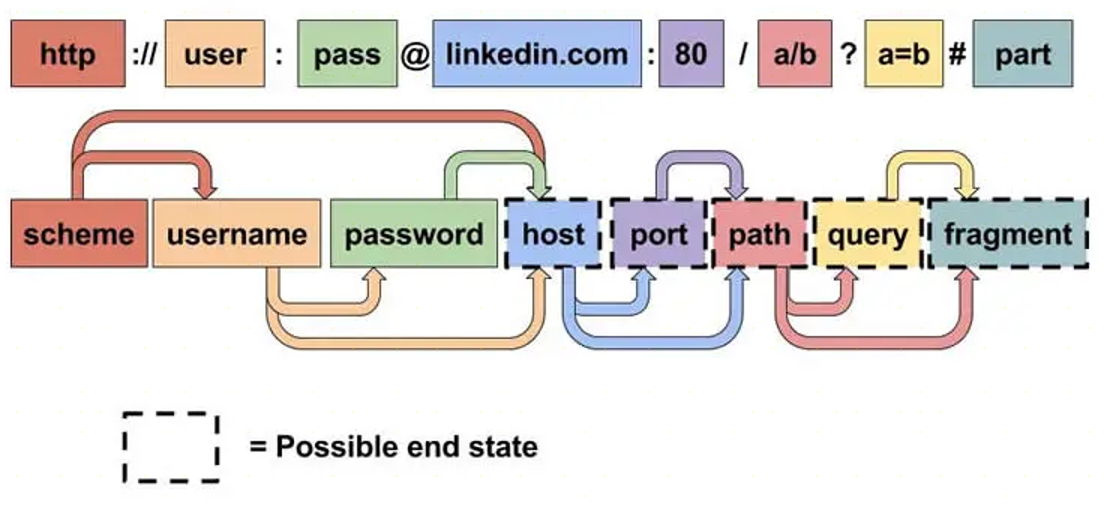
在Python中,有几个常用的库可以用来解析URL。以下是一些主要的选择:
urllib.parse
urllib.parse是Python标准库urllib模块中的一个子模块,专门用于解析URL。由于它是标准库的一部分,因此不需要额外安装。urllib.parse提供了一系列函数和类来处理URL的解析、构建和操作。
解析URL:
- urlparse(url, scheme=”, allow_fragments=True): 解析一个URL字符串,返回一个ParseResult对象,包含以下属性:scheme, netloc, path, params, query, fragment。
from urllib.parse import urlparse
result = urlparse('http://www.example.com:80/path;params?query=arg#fragment')
print(result.scheme) # 输出: 'http'
print(result.netloc) # 输出: 'www.example.com:80'
print(result.path) # 输出: '/path'
print(result.params) # 输出: 'params'
print(result.query) # 输出: 'query=arg'
print(result.fragment) # 输出: 'fragment'
构建URL:
- urlunparse(parts): 将一个包含URL各个组成部分的元组或列表组合成一个完整的URL字符串。
from urllib.parse import urlunparse
url = urlunparse(('http', 'www.example.com:80', '/path', 'params', 'query=arg', 'fragment'))
print(url) # 输出: 'http://www.example.com:80/path;params?query=arg#fragment'
处理查询参数:
- urlencode(query, doseq=False, safe=”, encoding=None, errors=None, quote_via=quote_plus): 将字典或序列转换为URL查询字符串。
- parse_qs(qs, keep_blank_values=False, strict_parsing=False, encoding=’utf-8′, errors=’replace’): 将查询字符串解析为字典。
- parse_qsl(qs, keep_blank_values=False, strict_parsing=False, encoding=’utf-8′, errors=’replace’): 将查询字符串解析为键值对的列表。
from urllib.parse import urlencode
from urllib.parse import parse_qs
from urllib.parse import parse_qsl
params = {'name': 'ferret', 'color': 'purple'}
query_string = urlencode(params)
print(query_string) # 输出: 'name=ferret&color=purple'
query = 'name=ferret&color=purple'
parsed_query = parse_qs(query)
print(parsed_query) # 输出: {'name': ['ferret'], 'color': ['purple']}
query = 'name=ferret&color=purple'
parsed_query = parse_qsl(query)
print(parsed_query) # 输出: [('name', 'ferret'), ('color', 'purple')]
合并URL:
- urljoin(base, url, allow_fragments=True): 将相对URL转换为绝对URL。
from urllib.parse import urljoin base_url = 'http://www.example.com/path/' new_url = urljoin(base_url, 'subpath/page.html') print(new_url) # 输出: 'http://www.example.com/path/subpath/page.html'
furl
furl是一个第三方Python库,用于简化URL的操作和管理。它提供了一种直观的方式来构建、解析和操作URL。与Python的标准库相比,furl更加面向对象,使URL操作更为简单和清晰。furl提供了一些便捷的类和方法来处理URL,以下是一些主要功能:
构建和解析URL:
furl提供了一个furl类,可以用于解析和构建URL。
from furl import furl
f = furl('http://www.example.com:80/path?arg=value#fragment')
print(f.scheme) # 输出: 'http'
print(f.host) # 输出: 'www.example.com'
print(f.port) # 输出: 80
print(f.path) # 输出: '/path'
print(f.args) # 输出: {'arg': 'value'}
print(f.fragment) # 输出: 'fragment'
修改URL:
furl提供了简单的方法来修改URL的各个部分。
f = furl('http://www.example.com/path')
f.path.add('to').add('resource')
f.args['key'] = 'value'
f.fragment = 'section'
print(f.url) # 输出: 'http://www.example.com/path/to/resource?key=value#section'
URL组合和拆分:
furl允许方便地组合和拆分URL。
base_url = furl('http://www.example.com/base')
full_url = base_url.copy().add(path='path/to/resource', args={'arg':'value'})
print(full_url.url) # 输出: 'http://www.example.com/base/path/to/resource?arg=value'
处理查询参数:
furl提供了便捷的方法来操作查询参数。
f = furl('http://www.example.com?name=ferret&color=purple')
f.args['color'] = 'blue'
f.args['age'] = 4
print(f.url) # 输出: 'http://www.example.com?name=ferret&color=blue&age=4'
复制和重置:
furl对象可以轻松复制和重置。
f1 = furl('http://www.example.com')
f2 = f1.copy()
f2.set(host='www.changed.com')
print(f1.url) # 输出: 'http://www.example.com'
print(f2.url) # 输出: 'http://www.changed.com'
purl
purl是一个轻量级的Python库,用于简化URL的解析和操作。与furl类似,purl提供了一种面向对象的方法来处理URL,使得URL操作更加直观和方便。
purl和furl都是用于处理URL的第三方Python库,它们都提供了一种面向对象的方法来解析和构建URL。然而,它们在设计理念、功能和用法上有一些区别。以下是purl和furl的一些主要区别:
设计理念
- furl:
- furl提供了更丰富的功能,适合需要复杂URL操作的场景。
- 它提供了更加全面的接口来操作URL的各个部分,包括路径、查询参数、片段等。
- purl:
- purl是一个轻量级库,设计上更为简单,适合需要基本URL操作的场景。
- 它的API更加简洁,专注于常用的URL操作。
功能特性
- 路径操作:
- furl提供了对路径的更细粒度的控制,例如可以轻松地添加、移除或替换路径段。
- purl也支持路径操作,但接口相对简单,适合基本路径修改。
- 查询参数:
- furl提供了一个强大的查询参数接口,支持添加、修改、删除参数,并支持参数的顺序。
- purl提供了简单的查询参数操作,适合处理常见的参数添加和修改。
- 复制和重置:
- furl支持复制和重置URL对象,允许在不影响原始对象的情况下进行操作。
- purl也支持类似的操作,但可能没有 furl 那么全面。
选择建议
- 如果你的项目需要处理复杂的URL操作,或者需要对URL的各个部分进行详细的管理,那么furl 可能更合适。
- 如果你需要一个简单的工具来处理基本的URL构建和解析,purl可能是一个不错的选择,因为它更轻量级且易于使用。
webargs
webargs是一个用于解析HTTP请求参数的Python库。它可以从请求的多种来源(如JSON、表单数据、查询字符串、cookies和headers)中提取参数,并将它们验证和转换为适当的类型。webargs的设计目标是简化参数解析和验证的过程,特别是在构建WebAPI时非常有用。
核心功能
- 参数解析:webargs支持从多种来源提取参数,包括:JSON请求体、表单数据、查询字符串、Cookies、HTTPHeaders
- 参数验证和转换:使用webargs,可以定义参数的验证规则和类型转换。它与marshmallow库集成,使用marshmallow的模式(schemas)来定义验证规则。
- 错误处理:webargs提供了灵活的错误处理机制,可以自定义错误响应。
以下是一些使用webargs的基本示例:
解析参数
假设我们正在使用Flask框架,以下是如何使用webargs从请求中解析参数的示例:
from flask import Flask, jsonify
from webargs import fields
from webargs.flaskparser import use_args
app = Flask(__name__)
# 定义参数模式
args_schema = {
"name": fields.Str(required=True),
"age": fields.Int(missing=18) # 如果未提供,则默认值为18
}
@app.route('/hello', methods=['GET'])
@use_args(args_schema, location="query")
def hello(args):
return jsonify({"message": f"Hello {args['name']}! You are {args['age']} years old."})
if __name__ == '__main__':
app.run()
在这个示例中,use_args装饰器用于从查询字符串中提取参数,并根据定义的模式进行验证。
验证参数
通过与marshmallow的集成,可以定义复杂的验证规则。例如,要求age在0到120之间:
from marshmallow import validate
args_schema = {
"name": fields.Str(required=True),
"age": fields.Int(missing=18, validate=validate.Range(min=0, max=120))
}
错误处理
可以自定义错误处理,以返回自定义的错误响应:
from webargs.flaskparser import parser
from flask import jsonify
@parser.error_handler
def handle_error(error, req, schema, *, error_status_code, error_headers):
"""自定义错误处理函数"""
response = jsonify({"errors": error.messages})
response.status_code = error_status_code or 400
return response
使用场景
- RESTful API 开发:在开发 RESTful API 时,webargs 可以简化请求参数的解析和验证。
- 输入验证:通过定义参数模式,可以确保输入数据符合预期的格式和范围。
- 简化代码:使用 webargs 可以减少手动解析和验证请求参数的代码量。
优点
- 与框架无关:虽然示例使用了 Flask,但 webargs 也支持其他框架,如 Django、Tornado 和 Pyramid。
- 强大的验证功能:通过与 marshmallow 的集成,webargs 提供了强大的数据验证和转换功能。
- 灵活性:支持从多种来源提取参数,提供灵活的使用方式。


