Pinot 简介
Apache Pinot 是一个实时分布式 OLAP 数据存储和分析系统,专为低延迟、高吞吐量的查询而设计。Pinot 最初由 LinkedIn 开发,用于支持其内部的分析应用,如 LinkedIn 的 “Who Viewed My Profile” 和其他商业智能应用。Pinot 的设计目标是提供快速的 OLAP 查询性能,同时支持从流数据源中摄取实时数据。

Apache Pinot 的产生背景
Apache Pinot 的产生背景源于 LinkedIn 的需求。LinkedIn 作为全球最大的职业社交平台,需要处理和分析海量的用户行为数据,以支持实时分析应用和仪表盘。
初始动机
- 实时分析需求:LinkedIn 需要一个系统来支持实时数据分析应用,例如“Who Viewed My Profile”和“Company Analytics”。这些应用需要对大量用户行为数据进行快速分析,以提供实时反馈和洞察。
- 低延迟、高吞吐量:由于用户期望实时获取信息,LinkedIn 需要一个能够提供低延迟查询响应的系统。该系统还需要处理高吞吐量的数据摄取,以便实时更新分析结果。
技术挑战
- 数据量大:
- LinkedIn 处理的数据量非常庞大,包括用户行为日志、点击流数据等。
- 需要一个能够水平扩展以处理数 TB 甚至 PB 级数据的系统。
- 复杂查询需求:
- 需要支持复杂的 OLAP 查询,包括多维分析、聚合、过滤和排序。
- 系统需要提供灵活的查询能力,以支持各种分析场景。
- 实时与批处理结合:
- LinkedIn 的分析需求不仅包括实时数据处理,还包括对历史数据的批量分析。
- 需要一个能够同时支持实时和批处理的统一平台。
开发历程
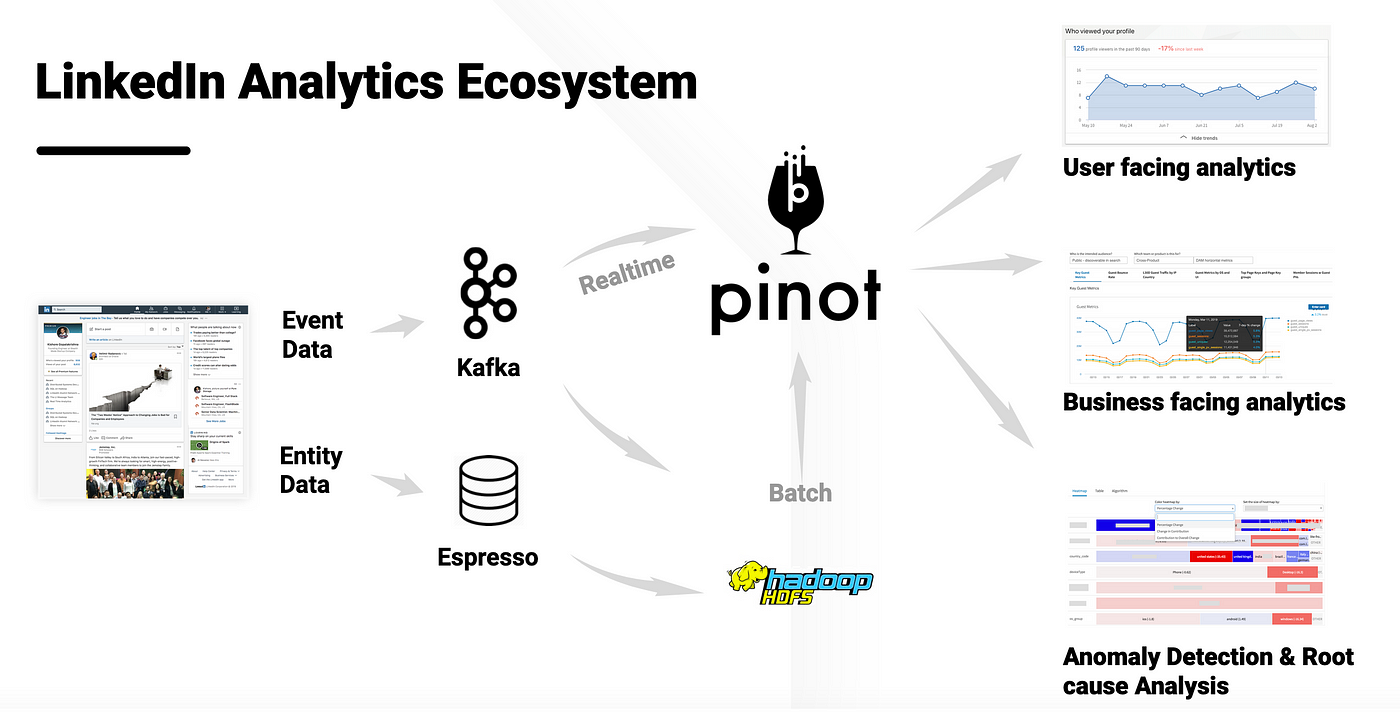
- 内部开发:
- LinkedIn 的工程团队在 2014 年开始开发 Pinot,以满足其特定的实时分析需求。
- Pinot 在 LinkedIn 内部广泛部署,用于支持多个关键的实时分析应用。
- 开源发布:
- 由于 Pinot 的成功应用,LinkedIn 决定将其开源,以便其他公司和开发者也能受益。
- 开源之后,Pinot 吸引了广泛的社区关注,并得到了不断的发展和改进。
社区和生态系统
- 活跃的开源社区:
- Pinot 的开源推动了其社区的发展,吸引了来自世界各地的开发者和企业的贡献。
- 社区不断为 Pinot 引入新特性和优化,以提高其性能和适用性。
- 广泛的行业应用:
- 除了 LinkedIn,许多其他公司也开始使用 Pinot 来支持其实时分析需求,特别是在互联网、广告技术和电商领域。
Pinot 的核心特性
Pinot 的优点
- 实时数据摄取:
- 支持从流数据源(如 Apache Kafka、Amazon Kinesis)中实时摄取数据,能够快速处理和查询最新的数据。
- 支持批处理数据摄取,可以从 Hadoop、S3 等批量数据源中导入数据。
- 低延迟查询:
- 通过列式存储和多种索引技术(如倒排索引、位图索引、StarTree 索引),Pinot 能够提供毫秒级的查询响应时间。
- 适用于需要快速响应的应用,如实时仪表盘和监控系统。
- 水平扩展性:
- 分布式架构允许通过添加节点来水平扩展,支持从 TB 到 PB 级别的数据处理。
- 支持数据分片和复制,确保高可用性和数据冗余。
- 高可用性和容错性:
- 通过数据分片和复制机制,Pinot 提供高可用性,确保系统在节点故障时仍能正常运行。
- 支持自动故障恢复和数据再平衡。
- 灵活的数据模型:
- 支持 schema-on-read,允许灵活处理和查询半结构化数据。
- 支持 JSON 和其他复杂数据类型。
- 丰富的索引类型:
- 提供多种索引类型,包括倒排索引、位图索引、StarTree 索引等,以优化不同类型的查询。
- 集成能力:
- 支持与多种数据源和流处理平台的集成,如 Apache Kafka、Hadoop、AWS S3 等。
- 提供 REST API 和 SQL 查询接口,便于与各种 BI 工具和应用进行集成。
Pinot 的缺点
- 复杂性:
- Pinot 的架构较为复杂,需要对多个组件进行配置和管理,包括 Controller、Broker、Server 和 Minion。
- 新用户可能需要一定的学习成本来理解和使用 Pinot。
- 数据更新限制:
- Pinot 更适合追加写入的场景,虽然支持数据更新和删除,但这些操作相对复杂且资源密集。
- 更新操作可能会导致数据不一致或性能下降。
- 存储成本:
- 为了优化查询性能,Pinot 会创建大量的索引和预聚合数据,这可能导致较高的存储成本。
- 需要仔细规划存储策略,以平衡查询性能和存储成本。
- 资源消耗:
- 高性能查询和实时数据摄取需要较大的计算资源,特别是内存和 CPU。
- 需要合理配置和优化硬件资源,以确保系统的稳定性和性能。
- 社区和文档:
- 相比于一些成熟的大数据技术,Pinot 的社区相对较小,文档和案例研究可能不如其他技术丰富。
- 新用户在遇到问题时可能需要更多的自我探索和调试。
Pinot 的应用场景
Apache Pinot 是一个专为实时分析和低延迟查询设计的分布式 OLAP 数据存储系统,其设计使其非常适合以下应用场景:
- 实时仪表盘:
- Pinot 能够处理和展示实时数据更新,适用于需要即时反馈的业务场景,如监控系统、运营仪表盘和实时数据可视化工具。
- 常用于金融、广告技术和电商等行业,以便决策者能够快速响应市场变化。
- 用户行为分析:
- 支持对用户活动和行为进行实时分析,如点击流分析、用户行为路径分析等。
- 适用于社交网络、在线零售和媒体平台,帮助企业了解用户行为模式和优化用户体验。
- 个性化推荐:
- 通过分析用户的实时活动数据,Pinot 可以帮助构建个性化推荐系统。
- 适用于电商平台、内容推荐引擎和广告技术公司,以提高用户参与度和满意度。
- 广告技术:
- Pinot 常用于实时竞价、广告效果分析和广告投放优化等场景。
- 支持高吞吐量和低延迟的广告数据处理,帮助广告商优化投放策略和提高广告效果。
- 能够实时处理和分析来自各种监控工具和传感器的数据,支持异常检测和趋势分析。
- 适用于 IT 运维、物联网和智能制造领域,实现系统健康状态监控和故障快速响应。
- 支持实时业务分析和决策支持,如销售数据分析、财务监控和客户关系管理。
- 适用于需要实时获取业务洞察的企业和组织,帮助优化运营和提高效率。
- 处理和分析来自社交媒体平台的实时数据流,支持社交趋势分析和品牌舆情监控。
- 适用于市场营销、品牌管理和公共关系领域,帮助企业了解市场动态和用户反馈。
- 支持处理和分析来自各种 IoT 设备的实时数据流,如传感器数据、设备状态监控等。
- 适用于智能城市、工业自动化和智能家居等领域,实现实时数据处理和决策支持。
Pinot 的架构
架构组件

Apache Pinot 的架构设计旨在支持实时数据摄取、低延迟查询和高可用性。Pinot 的架构由多个关键组件组成,每个组件都有其特定的功能和作用。以下是 Pinot 的主要架构组件的详细介绍:
Controller
- 功能:
- 管理集群的元数据和协调任务。
- 负责表的创建、配置和管理。
- 处理分片(segment)的分配和再平衡。
- 提供集群的健康状态监控和管理接口。
- 特点:
- 通常以高可用的方式部署,支持多实例运行以确保故障时的自动切换。
- 通过 Helix(一个用于分布式系统的集群管理框架)来管理集群状态。
Broker
- 功能:
- 处理查询请求,是用户与 Pinot 集群的接口。
- 接收用户的查询请求,将其分解并转发给相关的 Server 节点。
- 汇总各个 Server 节点的查询结果,并返回给用户。
- 特点:
- 支持查询路由和负载均衡,确保查询请求的高效处理。
- 可以水平扩展以提高查询处理能力。
Server
- 功能:
- 存储和管理实际的数据分片(segments)。
- 执行具体的数据查询操作,并将结果返回给 Broker。
- 特点:
- 支持列式存储和多种索引,以优化查询性能。
- 可以水平扩展以增加数据存储容量和处理能力。
Minion
- 功能:
- 负责后台任务的执行,如数据归档、索引创建和数据清理等。
- 用于实现数据的长期存储和管理策略。
- 特点:
- 作为 Pinot 的异步任务执行组件,Minion 提供了灵活的任务管理能力。
- 任务可以根据需求进行配置和调度。
Segment
- 功能:
- 数据的基本存储单元,类似于数据库中的表分区。
- 包含原始数据和索引数据,支持高效的查询和数据管理。
- 特点:
- 由实时数据摄取任务或批量导入任务生成。
- 支持多种索引类型,如倒排索引、位图索引和 StarTree 索引,以提高查询性能。
Zookeeper
- 功能:
- 作为分布式协调服务,负责存储集群的元数据和配置信息。
- 管理集群节点的状态和任务的分配。
- 特点:
- 提供一致性和高可用的分布式协调服务。
- 在 Pinot 中用于节点发现、任务协调和状态管理。
Apache Pinot 的架构通过分离不同的功能组件,实现了高效的数据摄取、存储和查询。Controller、Broker 和 Server 是 Pinot 的核心组件,负责集群管理、查询处理和数据存储。Minion 提供了后台任务处理能力,Zookeeper 作为协调服务确保了集群的稳定运行。通过这些组件的协同工作,Pinot 能够支持实时分析和低延迟查询,满足各种复杂的数据分析需求。
数据处理流程
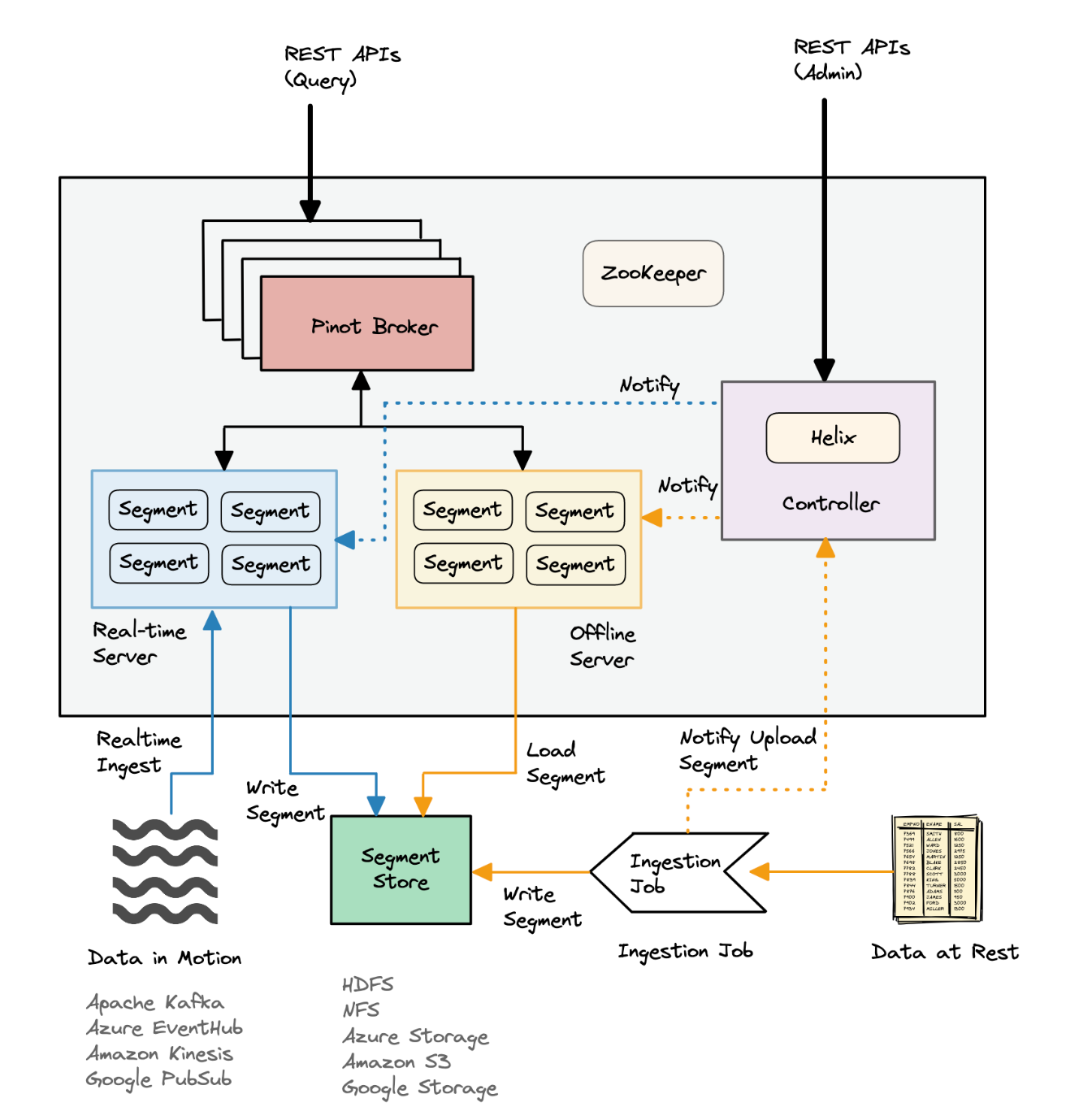
Apache Pinot 的数据处理流程涉及数据摄取、存储、索引和查询等多个阶段。以下是 Pinot 的详细数据处理流程:
数据摄取
Pinot 支持实时和批量两种数据摄取模式:
- 实时摄取:
- 数据源: 常用的实时数据源包括 Apache Kafka 和 Amazon Kinesis。
- 实时表(Realtime Table): 用于处理实时数据流。在实时表中,Pinot 从流数据源消费数据,并将其转换为 Pinot 内部的段(segment)格式。
- 数据处理: 数据被消费后,Pinot 会根据表的 schema 进行解析、转换和处理。实时节点负责将数据写入内存,并在达到一定条件(如时间或大小)后,生成段并持久化到存储中。
- 批量摄取:
- 数据源: 常用的批量数据源包括 HDFS、Amazon S3 和 Google Cloud Storage。
- 离线表(Offline Table): 用于处理批量数据。在离线表中,数据通过批处理任务(如 Apache Spark 或 Hadoop)预处理,并以 Pinot 段的格式导入。
- 数据导入: 预处理后的数据通过 Pinot 提供的批量导入工具(如 SegmentCreationJob)生成段,并上传到 Pinot 集群。
数据存储
- 列式存储:
- Pinot 使用列式存储格式,这种格式有助于提高查询性能,特别是对于只需要访问部分列的查询。
- 每个段包含多个列文件,每个文件存储一列的数据。
- 索引创建:
- Pinot 支持多种索引类型,包括倒排索引、位图索引、范围索引和 StarTree 索引。索引的创建可以在摄取过程中配置,以优化特定查询的性能。
- 索引有助于加速过滤、聚合和排序操作。
查询处理
- Broker 角色:
- Broker 是 Pinot 的查询入口,接收用户的查询请求,并将其分解为多个子查询,分发到相关的 Server 节点。
- Broker 负责将 Server 节点返回的结果进行合并和聚合,并最终返回给用户。
- Server 角色:
- Server 节点执行具体的查询操作。每个 Server 负责处理其存储的段上的查询。
- Server 利用索引加速查询处理,并在本地执行聚合操作以减少数据传输量。
- 查询优化:
- Pinot 提供了查询优化功能,如谓词下推、列剪裁和分片裁剪,以提高查询效率。
结果返回
- 合并与聚合:
- Broker 收集所有相关 Server 的查询结果后,进行必要的合并和全局聚合操作。
- 最终的查询结果通过 Broker 返回给用户。
Pinot 的数据处理流程通过结合实时和批量摄取模式,支持灵活的数据导入。通过列式存储和多种索引机制,Pinot 优化了查询性能。在查询处理阶段,Broker 和 Server 之间的协同工作确保了高效的查询执行和结果返回。这一流程使得 Pinot 能够支持实时分析和低延迟查询,满足各种复杂的数据分析需求。
参考链接:


