文章内容如有错误或排版问题,请提交反馈,非常感谢!
Nextflow简介
Nextflow是一个用于数据驱动的计算管道(pipeline)开发和执行的开源框架,特别适合生物信息学和科学计算领域。它简化了复杂工作流程的创建和管理,使得科学家和工程师能够高效地处理大规模数据分析任务。
核心功能
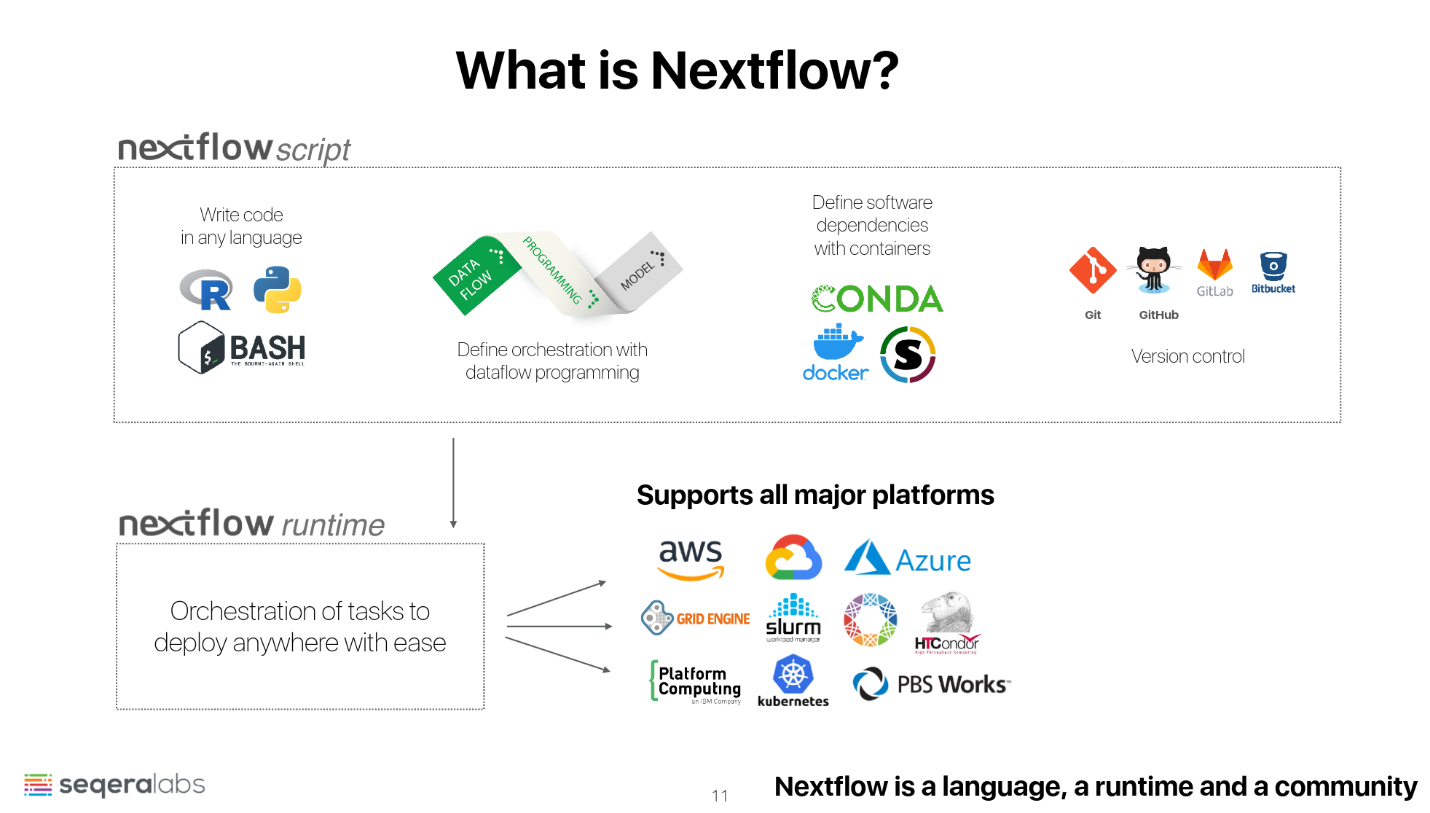
- 可重现性: Nextflow提供了高度可重现的计算环境,通过定义明确的工作流程和数据依赖关系,确保每次执行的结果一致。
- 模块化设计: 工作流程可以被分解为多个独立的模块(process),每个模块可以单独开发、测试和重用。这种模块化设计使得工作流程更易于管理和扩展。
- 数据流编程模型: 采用数据流编程模型,允许用户通过简单的声明式语法定义数据处理任务和数据依赖关系。Nextflow自动管理数据传输和任务调度。
- 容器支持: 原生支持Docker、Singularity等容器技术,确保环境的可移植性和一致性,方便在不同计算平台上运行。
- 多平台兼容性: 支持在多种计算环境中运行,包括本地计算机、集群、云平台(如AWS、Google Cloud、Azure)和高性能计算(HPC)系统。
- 版本控制: 集成版本控制系统(如Git),支持对工作流程的版本管理,便于团队协作和工作流程的演化。
应用场景
- 生物信息学分析: 常用于基因组测序、蛋白质组学、转录组学等生物信息学领域的复杂数据分析任务。
- 大规模数据处理: 适合处理需要在大规模数据集上进行的复杂计算任务,如气候模拟、物理模拟和图像处理。
- 科学研究与实验: 支持多种科学领域的研究工作流程,帮助科学家进行实验数据的分析和处理。
- 云计算与高性能计算: 支持在云平台和HPC系统上运行工作流程,方便进行大规模计算任务的部署和执行。
Nextflow的架构
Nextflow的架构设计旨在为复杂的数据驱动工作流程提供灵活、可扩展和高效的执行环境。它采用数据流编程模型和模块化设计,支持在多种计算平台上运行。以下是Nextflow的架构及其关键组件的详细介绍:
核心组件
- DSL(领域特定语言): Nextflow使用一种专门设计的领域特定语言(DSL)来定义工作流程。DSL提供了简单且强大的语法,用于描述数据处理任务、依赖关系和执行逻辑。
- Process(进程): 工作流程的基本构建块。每个进程定义一个独立的数据处理任务,包括输入、输出和要执行的命令。进程是可重用和可组合的,允许用户构建模块化的工作流程。
- Channel(通道): 用于在进程之间传递数据的抽象。通道支持多种数据传输模式(如一对一、一对多和多对多),Nextflow自动管理数据流和依赖关系,确保数据在进程之间的正确传递。
- Executor(执行器): 负责任务的调度和执行。Nextflow支持多种执行环境,包括本地计算、HPC集群和云平台(如AWS、Google Cloud、Azure)。执行器根据用户定义的配置选择合适的计算资源来执行任务。
- Script: 工作流程的定义文件,使用Nextflow DSL编写。脚本中包含了流程定义、通道声明和执行逻辑。
- Runtime Engine(运行时引擎): Nextflow的核心引擎,负责解析和执行用户定义的工作流程。它管理进程的生命周期、调度任务和处理数据流。
工作流程
- 定义流程: 用户使用Nextflow DSL编写脚本,定义工作流程的各个进程、数据通道和执行逻辑。
- 数据传输: 数据通过通道在进程之间传递,Nextflow负责管理数据流和依赖关系。
- 任务调度与执行: Nextflow的运行时引擎解析脚本并调度任务。根据配置,选择合适的执行器在指定的计算环境中运行任务。
- 结果收集: 每个进程的输出可以作为其他进程的输入,最终收集所有任务的结果并进行处理。
Nextflow使用示例
Nextflow是一个强大的工具,用于定义和执行数据驱动的工作流程。
假设我们有一个文本文件,其中包含多个样本的数据。我们希望对每个样本执行一些简单的数据处理任务,比如计算行数。这是一个简单的示例,但它展示了Nextflow的基本用法。
文件结构
假设我们有以下文件结构:
. ├── data │ ├── sample1.txt │ ├── sample2.txt │ └── sample3.txt └── main.nf
data目录下包含了多个文本文件,每个文件代表一个数据样本。
main.nf 脚本
这是我们的Nextflow脚本,定义了工作流程:
#!/usr/bin/env nextflow
// Define the input channel
Channel.fromPath('data/*.txt')
.set { sample_files }
// Define the process to count lines in each sample file
process countLines {
input:
path sample_file from sample_files
output:
stdout result
script:
"""
wc -l< $sample_file
"""
}
// Print the result
result.view { it }
解释
- Channel定义:
- fromPath('data/*.txt'):创建一个通道,从 data 目录中读取所有 .txt 文件,并将其路径传递到名为 sample_files 的通道中。
- Process定义:
- process countLines:定义一个名为 countLines 的进程,用于处理每个样本文件。
- input: path sample_file from sample_files:指定进程的输入为 sample_files 通道中传递的文件路径。
- output: stdout result:将进程的标准输出捕获到 result 通道中。
- script: "wc -l< $sample_file":在脚本块中执行 wc -l 命令来计算文件的行数。
- 结果查看:
- view { it }:打印 result 通道中的输出结果。
运行工作流程
要运行这个Nextflow工作流程,确保已经安装了Nextflow,然后在终端中执行以下命令:nextflow run main.nf结果
运行后,你将看到类似以下的输出,每行显示一个样本文件的行数:
10 15 8
每个数字对应于一个样本文件的行数。
这个简单的示例展示了如何使用Nextflow定义和执行一个基本的数据处理工作流程。通过定义通道和进程,你可以轻松管理数据流和任务执行。Nextflow的模块化和灵活性使其适用于各种复杂的数据分析任务,尤其是在生物信息学和科学计算领域。
参考链接:


