文件系统
文件系统是操作系统中负责管理持久数据的子系统,说简单点,就是负责把用户的文件存到磁盘硬件中,因为即使计算机断电了,磁盘里的数据并不会丢失,所以可以持久化的保存文件。
文件系统的基本数据单位是文件,它的目的是对磁盘上的文件进行组织管理,那组织的方式不同,就会形成不同的文件系统。
Linux最经典的一句话是:「一切皆文件」,不仅普通的文件和目录,就连块设备、管道、socket等,也都是统一交给文件系统管理的。
Linux文件系统会为每个文件分配两个数据结构:索引节点(index node)和目录项(directory entry),它们主要用来记录文件的元信息和目录层次结构。
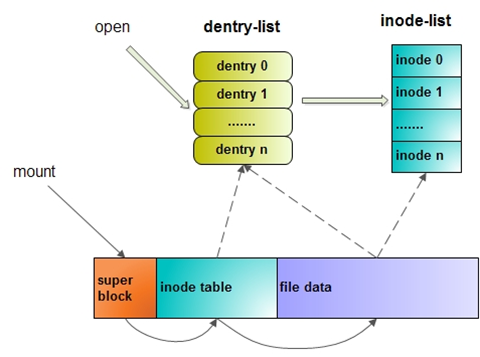
- 索引节点,也就是inode,用来记录文件的元信息,比如inode编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置等等。索引节点是文件的唯一标识,它们之间一一对应,也同样都会被存储在硬盘中,所以索引节点同样占用磁盘空间。
- 目录项,也就是dentry,用来记录文件的名字、索引节点指针以及与其他目录项的层级关联关系。多个目录项关联起来,就会形成目录结构,但它与索引节点不同的是,目录项是由内核维护的一个数据结构,不存放于磁盘,而是缓存在内存。
由于索引节点唯一标识一个文件,而目录项记录着文件的名,所以目录项和索引节点的关系是多对一,也就是说,一个文件可以有多个目录。比如,硬链接的实现就是多个目录项中的索引节点指向同一个文件。
注意,目录也是文件,也是用索引节点唯一标识,和普通文件不同的是,普通文件在磁盘里面保存的是文件数据,而目录文件在磁盘里面保存子目录或文件。
目录项和目录是一个东西吗?
虽然名字很相近,但是它们不是一个东西,目录是个文件,持久化存储在磁盘,而目录项是内核一个数据结构,缓存在内存。
如果查询目录频繁从磁盘读,效率会很低,所以内核会把已经读过的目录用目录项这个数据结构缓存在内存,下次再次读到相同的目录时,只需从内存读就可以,大大提高了文件系统的效率。
注意,目录项这个数据结构不只是表示目录,也是可以表示文件的。
文件数据是如何存储在磁盘的呢?
磁盘读写的最小单位是扇区,扇区的大小只有512字节,那么如果数据大于512字节时候,磁盘需要不停地移动磁头来查找数据,我们知道一般的文件很容易超过512字节那么如果把多个扇区合并为一个块,那么磁盘就可以提高效率了。那么磁头一次读取多个扇区就为一个块“block”(Linux上称为块,Windows上称为簇)。所以,文件系统把多个扇区组成了一个逻辑块,每次读写的最小单位就是逻辑块(数据块),Linux中的逻辑块大小为4KB,也就是一次性读写8个扇区,这将大大提高了磁盘的读写的效率。
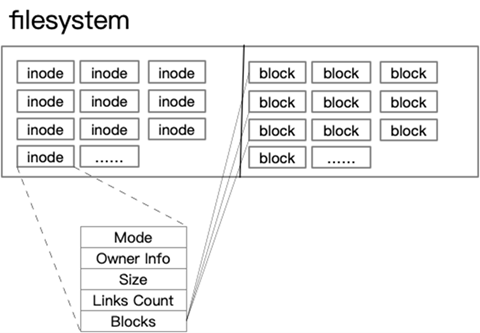
文件系统记录的数据,除了其自身外,还有数据的权限信息,所有者等属性,这些信息都保存在inode中,那么谁来记录inode信息和文件系统本身的信息呢,比如说文件系统的格式,inode与data的数量呢?那么就有一个超级区块(supper block)来记录这些信息了。
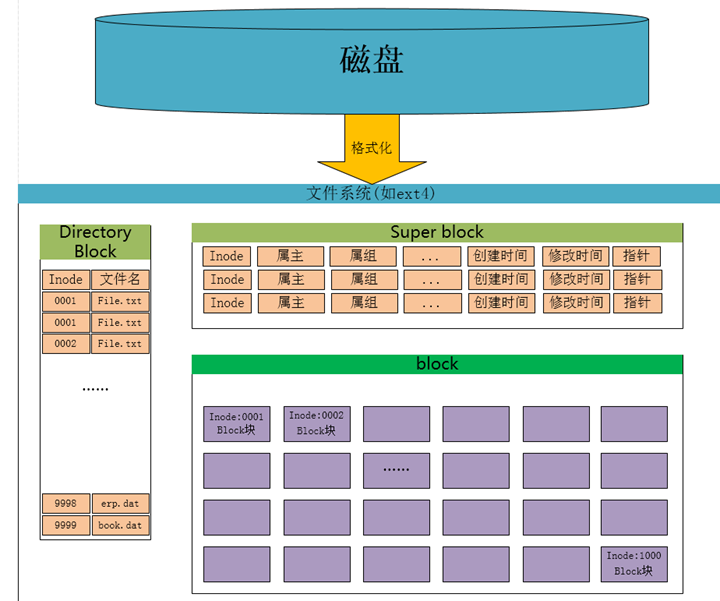
- super block:记录此filesystem的整体信息,包括inode/block的总量、使用量、剩余量,以及文件系统的格式与相关信息等
- inode:记录文件的属性信息,可以使用stat命令查看inode信息。
- block:实际文件的内容,如果一个文件大于一个块时候,那么将占用多个block,但是一个块只能存放一个文件。(因为数据是由inode指向的,如果有两个文件的数据存放在同一个块中,就会乱套了)
node用来指向数据block,那么只要找到inode,再由inode找到block编号,那么实际数据就能找出来了。
索引节点是存储在硬盘上的数据,为了加速文件的访问,通常会把索引节点加载到内存中。我们不可能把超级块和索引节点区全部加载到内存,这样内存肯定撑不住,所以只有当需要使用的时候,才将其加载进内存,它们加载进内存的时机是不同的:
- 超级块:当文件系统挂载时进入内存;
- 索引节点区:当文件被访问时进入内存;
虚拟文件系统
文件系统的种类众多,而操作系统希望对用户提供一个统一的接口,于是在用户层与文件系统层引入了中间层,这个中间层就称为虚拟文件系统(Virtual File System,VFS)。VFS定义了一组所有文件系统都支持的数据结构和标准接口,这样程序员不需要了解文件系统的工作原理,只需要了解VFS提供的统一接口即可。在Linux文件系统中,用户空间、系统调用、虚拟机文件系统、缓存、文件系统以及存储之间的关系如下图:
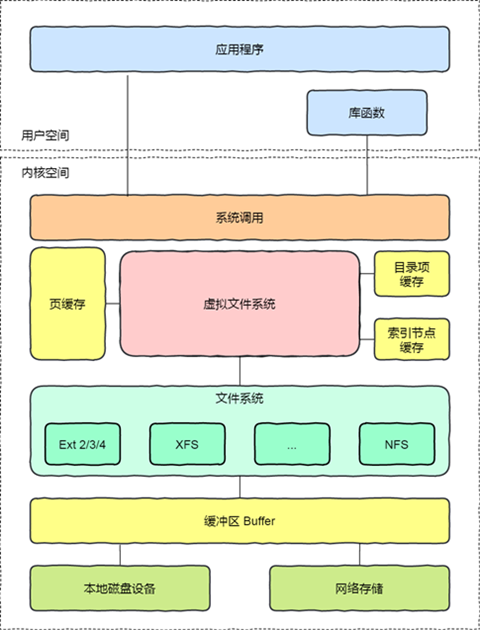
Linux支持的文件系统也不少,根据存储位置的不同,可以把文件系统分为三类:
- 磁盘的文件系统,它是直接把数据存储在磁盘中,比如Ext2/3/4、XFS等都是这类文件系统。
- 内存的文件系统,这类文件系统的数据不是存储在硬盘的,而是占用内存空间,我们经常用到的/proc 和 /sys 文件系统都属于这一类,读写这类文件,实际上是读写内核中相关的数据。
- 网络的文件系统,用来访问其他计算机主机数据的文件系统,比如NFS、SMB等等。
文件系统首先要先挂载到某个目录才可以正常使用,比如Linux系统在启动时,会把文件系统挂载到根目录。
Linux采用为分层的体系结构,将用户接口层、文件系统实现和存储设备的驱动程序分隔开,进而兼容不同的文件系统。虚拟文件系统(Virtual File System, VFS)是Linux内核中的软件层,它在内核中提供了一组标准的、抽象的文件操作,允许不同的文件系统实现共存,并向用户空间程序提供统一的文件系统接口。下面这张图展示了Linux虚拟文件系统的整体结构:
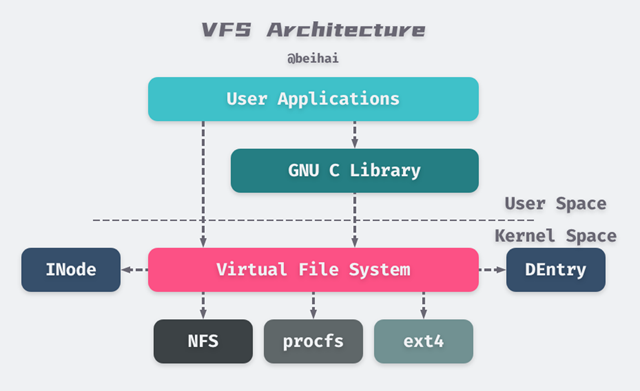
从上图可以看出,用户空间的应用程序直接、或是通过编程语言提供的库函数间接调用内核提供的 SystemCall 接口(如 open()、write() 等)执行文件操作。SystemCall 接口再将应用程序的参数传递给虚拟文件系统进行处理。
每个文件系统都为 VFS 实现了一组通用接口,具体的文件系统根据自己对磁盘上数据的组织方式操作相应的数据。当应用程序操作某个文件时,VFS 会根据文件路径找到相应的挂载点,得到具体的文件系统信息,然后调用该文件系统的对应操作函数。
VFS 提供了两个针对文件系统对象的缓存 INode Cache 和 DEntry Cache,它们缓存最近使用过的文件系统对象,用来加快对 INode 和 DEntry 的访问。Linux 内核还提供了 Buffer Cache 缓冲区,用来缓存文件系统和相关块设备之间的请求,减少访问物理设备的次数,加快访问速度。Buffer Cache 以 LRU 列表的形式管理缓冲区。
VFS 的好处是实现了应用程序的文件操作与具体的文件系统的解耦,使得编程更加容易:
- 应用层程序只要使用 VFS 对外提供的 read()、write() 等接口就可以执行文件操作,不需要关心底层文件系统的实现细节;
- 文件系统只需要实现 VFS 接口就可以兼容 Linux,方便移植与维护;
- 无需关注具体的实现细节,就实现跨文件系统的文件操作。
了解 Linux 文件系统的整体结构后,下面主要分析 Linux VFS 的技术原理。由于文件系统与设备驱动的实现非常复杂,笔者也未接触过这方面的内容,因此文中不会涉及具体文件系统的实现。
VFS 结构
Linux 以一组通用对象的角度看待所有文件系统,每一级对象之间的关系如下图所示:
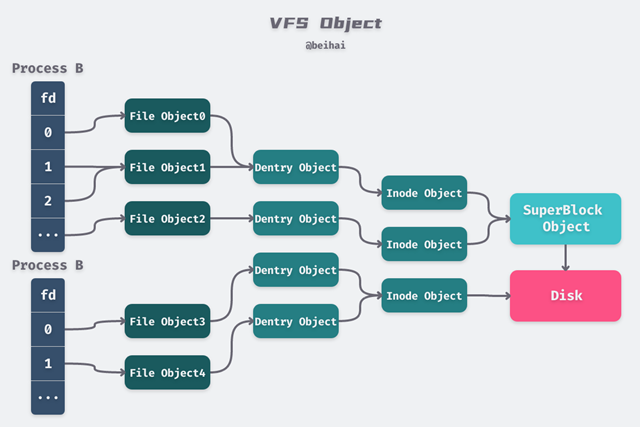
fd 与 file
每个进程都持有一个 fd[] 数组,数组里面存放的是指向 file 结构体的指针,同一进程的不同 fd 可以指向同一个 file 对象;
file 是内核中的数据结构,表示一个被进程打开的文件,和进程相关联。当应用程序调用 open() 函数的时候,VFS 就会创建相应的 file 对象。它会保存打开文件的状态,例如文件权限、路径、偏移量等等。
// https://elixir.bootlin.com/linux/v5.4.93/source/include/linux/fs.h#L936 结构体已删减
struct file {
struct path f_path;
struct inode *f_inode;
const struct file_operations *f_op;
unsigned int f_flags;
fmode_t f_mode;
loff_t f_pos;
struct fown_struct f_owner;
}
// https://elixir.bootlin.com/linux/v5.4.93/source/include/linux/path.h#L8
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
}
从上面的代码可以看出,文件的路径实际上是一个指向 DEntry 结构体的指针,VFS 通过 DEntry 索引到文件的位置。
除了文件偏移量 f_pos 是进程私有的数据外,其他的数据都来自于 INode 和 DEntry,和所有进程共享。不同进程的 file 对象可以指向同一个 DEntry 和 Inode,从而实现文件的共享。
DEntry 与 INode
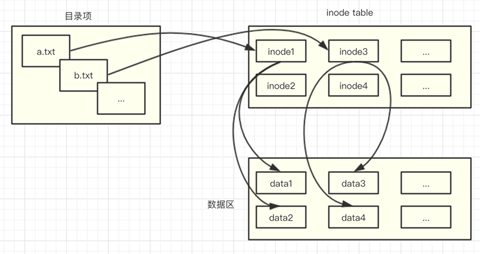
Linux 文件系统会为每个文件都分配两个数据结构,目录项(DEntry, Directory Entry)和索引节点(INode, Index Node)。
DEntry 用来保存文件路径和 INode 之间的映射,从而支持在文件系统中移动。DEntry 由 VFS 维护,所有文件系统共享,不和具体的进程关联。dentry 对象从根目录“/”开始,每个 dentry 对象都会持有自己的子目录和文件,这样就形成了文件树。举例来说,如果要访问 “/home/beihai/a.txt” 文件并对他操作,系统会解析文件路径,首先从“/”根目录的 dentry 对象开始访问,然后找到 “home/“ 目录,其次是 “beihai/”,最后找到 “a.txt” 的 dentry 结构体,该结构体里面 d_inode 字段就对应着该文件。
// https://elixir.bootlin.com/linux/v5.4.93/source/include/linux/dcache.h#L89 结构体已删减
struct dentry {
struct dentry *d_parent; // 父目录
struct qstr d_name; // 文件名称
struct inode *d_inode; // 关联的 inode
struct list_head d_child; // 父目录中的子目录和文件
struct list_head d_subdirs; // 当前目录中的子目录和文件
}
每一个 dentry 对象都持有一个对应的 inode 对象,表示 Linux 中一个具体的目录项或文件。INode 包含管理文件系统中的对象所需的所有元数据,以及可以在该文件对象上执行的操作。
// https://elixir.bootlin.com/linux/v5.4.93/source/include/linux/fs.h#L628 结构体已删减
struct inode {
umode_t i_mode; // 文件权限及类型
kuid_t i_uid; // user id
kgid_t i_gid; // group id
const struct inode_operations *i_op; // inode 操作函数,如 create,mkdir,lookup,rename 等
struct super_block *i_sb; // 所属的 SuperBlock
loff_t i_size; // 文件大小
struct timespec i_atime; // 文件最后访问时间
struct timespec i_mtime; // 文件最后修改时间
struct timespec i_ctime; // 文件元数据最后修改时间(包括文件名称)
const struct file_operations *i_fop; // 文件操作函数,open、write 等
void *i_private; // 文件系统的私有数据
}
虚拟文件系统维护了一个 DEntry Cache 缓存,用来保存最近使用的 DEntry,加速查询操作。当调用 open() 函数打开一个文件时,内核会第一时间根据文件路径到 DEntry Cache 里面寻找相应的 DEntry,找到了就直接构造一个 file 对象并返回。如果该文件不在缓存中,那么 VFS 会根据找到的最近目录一级一级地向下加载,直到找到相应的文件。期间 VFS 会缓存所有被加载生成的 dentry。
INode 存储的数据存放在磁盘上,由具体的文件系统进行组织,当需要访问一个 INode 时,会由文件系统从磁盘上加载相应的数据并构造 INode。一个 INode 可能被多个 DEntry 所关联,即相当于为某一文件创建了多个文件路径(通常是为文件建立硬链接)。
SuperBlock
SuperBlock 表示特定加载的文件系统,用于描述和维护文件系统的状态,由 VFS 定义,但里面的数据根据具体的文件系统填充。每个 SuperBlock 代表了一个具体的磁盘分区,里面包含了当前磁盘分区的信息,如文件系统类型、剩余空间等。SuperBlock 的一个重要成员是链表 s_list,包含所有修改过的 INode,使用该链表很容易区分出来哪个文件被修改过,并配合内核线程将数据写回磁盘。SuperBlock 的另一个重要成员是 s_op,定义了针对其 INode 的所有操作方法,例如标记、释放索引节点等一系列操作。
//https://elixir.bootlin.com/linux/v5.4.93/source/include/linux/fs.h#L1425 结构体已删减
struct super_block {
struct list_head s_list; // 指向链表的指针
dev_t s_dev; // 设备标识符
unsigned long s_blocksize; // 以字节为单位的块大小
loff_t s_maxbytes; // 文件大小上限
struct file_system_type *s_type; // 文件系统类型
const struct super_operations *s_op; // SuperBlock 操作函数,write_inode、put_inode等
const struct dquot_operations *dq_op; // 磁盘限额函数
struct dentry *s_root; // 根目录
}
SuperBlock 是一个非常复杂的结构,通过 SuperBlock 我们可以将一个实体文件系统挂载到 Linux 上,或者对 INode 进行增删改查操作。所以一般文件系统都会在磁盘上存储多份 SuperBlock,防止数据意外损坏导致整个分区无法读取。
inode 内容
inode 包含很多的文件元信息,但不包含文件名,例如:字节数、属主 UserID、属组 GroupID、读写执行权限、时间戳等。而文件名存放在目录当中,但 Linux 系统内部不使用文件名,而是使用 inode 号码识别文件。对于系统来说文件名只是 inode 号码便于识别的别称。
stat
查看 inode 信息
[root@localhost ~]# mkdir test [root@localhost ~]# echo "this is test file" > test.txt [root@localhost ~]# stat test.txt File: 'test.txt' Size: 18 Blocks: 8 IO Block: 4096 regular file Device: fd00h/64768d Inode: 33574994 Links: 1 Access: (0644/-rw-r--r--) Uid: (0/ root) Gid: (0/ root) Context: unconfined_u:object_r:admin_home_t:s0 Access: 2019-08-28 19:55:05.920240744 +0800 Modify: 2019-08-28 19:55:05.920240744 +0800 Change: 2019-08-28 19:55:05.920240744 +0800 Birth: -
三个主要的时间属性:
- ctime:change time 是最后一次改变文件或目录(属性)的时间,例如执行 chmod,chown 等命令。
- atime:access time 是最后一次访问文件或目录的时间。
- mtime:modify time 是最后一次修改文件或目录(内容)的时间。
file
查看文件类型
[root@localhost ~]# file test test: directory [root@localhost ~]# file test.txt test.txt: ASCII text
inode 号码
表面上,用户通过文件名打开文件,实际上,系统内部将这个过程分为三步:
- 系统找到这个文件名对应的 inode 号码;
- 通过 inode 号码,获取 inode 信息;
- 根据 inode 信息,找到文件数据所在的 block,并读出数据。
其实系统还要根据 inode 信息,看用户是否具有访问的权限,有就指向对应的数据 block,没有就返回权限拒绝。
ls -i
直接查看文件 i 节点号,也可以通过 stat 查看文件 inode 信息查看 i 节点号。
[root@localhost ~]# ls -i 33574991 anaconda-ks.cfg 2086 test 33574994 test.txt
inode 大小
inode 也会消耗硬盘空间,所以格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是 inode 区,存放 inode 所包含的信息。每个 inode 的大小,一般是 128 字节或 256 字节。通常情况下不需要关注单个 inode 的大小,而是需要重点关注 inode 总数。inode 总数在格式化的时候就确定了。
df -i
查看硬盘分区的 inode 总数和已使用情况
[root@localhost ~]# df -i Filesystem Inodes IUsed IFree IUse% Mounted on /dev/mapper/centos-root 8910848 260298 8848191% / devtmpfs 230602 384 230218 1% /dev tmpfs 233378 1 233377 1% /dev/shm tmpfs 233378 487 232891 1% /run tmpfs 233378 16 233362 1% /sys/fs/cgroup /dev/sda1 524288 328 523960 1% /boot tmpfs 233378 1 233377 1% /run/user/0
文件的读写
文件系统在打开一个文件时,要做的有:
- 系统找到这个文件名对应的 inode:在目录表中查找该文件名对应的项,由此得到该文件相对应的 inode 号
- 通过 inode 号,获取到磁盘中的 inode 信息,其中最重要的内容是磁盘地址表
- 通过 inode 信息中的磁盘地址表,文件系统把分散存放的文件物理块链接成文件的逻辑结构。在磁盘地址表中有 13 个块号,文件将以块号在磁盘地址表中出现的顺序依次读取相应的块。找到文件数据所在的 block,读出数据。
根据以上流程,我们可以发现,inode 应该是有一个专门的存储区域的,以方便系统快速查找。事实上,一块磁盘创建的时候,操作系统自动将硬盘分成两个区域:存放文件数据的数据区,与存放 inode 信息的 inode 区(inode table)。
每个 inode 的大小一般是 128B 或者 256B。inode 节点的总数,在格式化时就给定,一般是每 1KB 或每 2KB 就设置一个 inode。假定在一块 1GB 的硬盘中,每个 inode 节点的大小为 128 字节,每 1KB 就设置一个 inode,那么 inode table 的大小就会达到 128MB,占整块硬盘的 12.8%。
也就是说,每个分区的 inode 总数从格式化之后就固定了,因此有可能会出现存储空间没有占满,但因为小文件太多而耗尽了 inode 的情况。这个时候就只能清除 inode 占用高的文件或者目录或修改 inode 数量了,当然,inode 的调整需要重新格式化磁盘,需要确保数据已经得到有效备份后,再进行此操作。
这时候又产生了新的问题:文件创建时要为文件分配哪一个 inode 号呢?即如何保证分配的 inode 号没有被占用?
既然是”是否被占用”的问题,使用位图是最佳方案,像 bmap 记录 block 的占用情况一样。标识 inode 号是否被分配的位图称为 inode map 简称为 imap。这时要为一个文件分配 inode 号只需扫描 imap 即可知道哪一个 inode 号是空闲的。
(位图法就是 bitmap 的缩写。所谓 bitmap,就是用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况。)
类似 bmap 块位图一样,inode 号是预先规划好的。inode 号分配后,文件删除也会释放 inode 号。分配和释放的 inode 号,像是在一个地图上挖掉一块,用完再补回来一样。
imap 存在着和 bmap 和 inode table 一样需要解决的问题:如果文件系统比较大,imap 本身就会很大,每次存储文件都要进行扫描,会导致效率不够高。同样,优化的方式是将文件系统占用的 block 划分成块组,每个块组有自己的 imap 范围,以减少检索时间。
利用 df -i 命令可以查看 inode 数量方面的信息文件的操作
系统对文件的操作会可能影响 inode:
- 复制:创建一个包含全部数据与新 inode 号的新文件
- 硬链接:同一个 inode 号代表的文件有多个文件名,即可以用不同的文件名访问同一份数据,但是它们指向的 inode 编号是相同的,并且文件元数据中链接数会增加。不可以对目录创建硬链接。
- 软链接:软链接的本质是一个链接文件,其中存储的了对另一个文件的指针。所以对一个文件创建软链接,inode 号不相同,创建软链接文件的链接数不会增加。可以对目录创建软链接。
- 删除:当删除文件时,会先检查 inode 中的链接数。如果链接数大于 1,就只会删掉一个硬链接,不影响数据。如果链接数等于 1,那么这个 inode 就会被释放掉,对应的 inode 指向的块也会被标记为空闲的(数据不会被置零,所以硬盘数据被误删除后,若没有新数据写入可恢复)。如果是软链接,原文件被删除后链接文件就变成了悬挂链接(dangling link),无法正常访问了。
移动:在同一磁盘下移动时,所在目录改变,node号与实际数据存储的块的位置都不会变化。跨磁盘移动当然会删除本磁盘的数据并创建一条新的数据在另一块磁盘中。
利用 inode 还可以删除一些文件名中有转义字符或控制字符的文件,最典型的就是开头为减号 – 的文件。这种无法直接用 rm 命令来搞,就可以先查出它们的 inode 编号再删除:find ./ -inum 10086 -exec rm {}\
特有现象
由于 inode 号码与文件名分离,导致一些 Unix/Linux 系统具备以下几种特有的现象。
- 文件名包含特殊字符,可能无法正常删除。这时直接删除 inode,能够起到删除文件的作用;
find ./* -inum 节点号 -delete - 移动文件或重命名文件,只是改变文件名,不影响 inode 号码;
- 打开一个文件以后,系统就以 inode 号码来识别这个文件,不再考虑文件名。
这种情况使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过 inode 号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的 inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的 inode 则被回收。
inode 耗尽故障
由于硬盘分区的 inode 总数在格式化后就已经固定,而每个文件必须有一个 inode,因此就有可能发生 inode 节点用光,但硬盘空间还剩不少,却无法创建新文件。同时这也是一种攻击的方式,所以一些公用的文件系统就要做磁盘限额,以防止影响到系统的正常运行。至于修复,很简单,只要找出哪些大量占用 i 节点的文件删除就可以了。
硬链接与软链接
Linux 系统中有一种比较特殊的文件称之为链接(link)。通俗地说,链接就是从一个文件指向另外一个文件的路径。linux 中链接分为俩种,硬链接和软链接。简单来说,硬链接相当于源文件和链接文件在磁盘和内存中共享一个 inode,因此,链接文件和源文件有不同的 dentry,因此,这个特性决定了硬链接无法跨越文件系统,而且我们无法为目录创建硬链接。软链接和硬链接不同,首先软链接可以跨越文件系统,其次,链接文件和源文件有着不同的 inode 和 dentry,因此,两个文件的属性和内容也截然不同,软链接文件的文件内容是源文件的文件名。
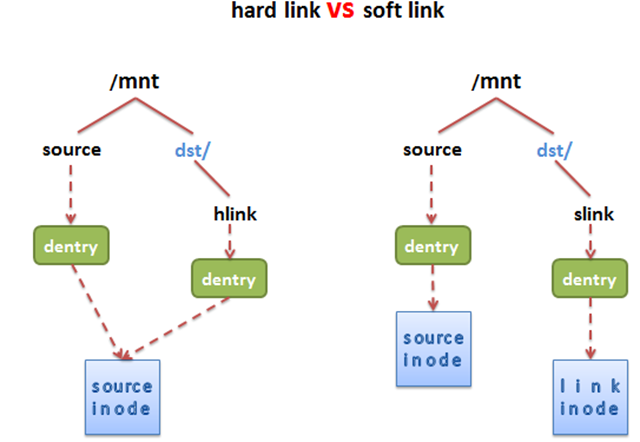
硬链接是多个目录项中的「索引节点」指向一个文件,也就是指向同一个 inode,但是 inode 是不可能跨越文件系统的,每个文件系统都有各自的 inode 数据结构和列表,所以硬链接是不可用于跨文件系统的。由于多个目录项都是指向一个 inode,那么只有删除文件的所有硬链接以及源文件时,系统才会彻底删除该文件。

软链接相当于重新创建一个文件,这个文件有独立的 inode,但是这个文件的内容是另外一个文件的路径,所以访问软链接的时候,实际上相当于访问到了另外一个文件,所以软链接是可以跨文件系统的,甚至目标文件被删除了,链接文件还是在的,只不过指向的文件找不到了而已。
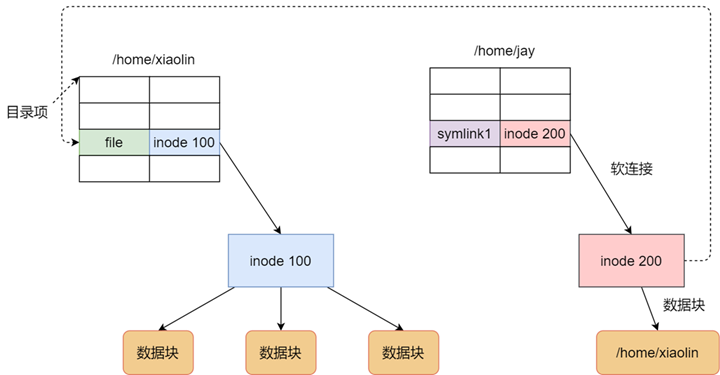
- 软硬链接实现的原理不同
- 硬链接是建立一个目录项,包含文件名和文件的 inode,但 inode 是原来文件的 inode 号,并不建立其所对应得数据。所以硬链接并不占用 inode。
- 软链接也创建一个目录项,也包含文件名和文件的 inode,但它的 inode 指向的并不是原来文件名所指向的数据的 inode,而是新建一个 inode,并建立数据,数据指向的是原来文件名,所以原来文件名的字符数,即为软链接所占字节数
- 软硬链接所能创建的目标有区别
- 因为每个分区各有一套不同的 inode 表,所以硬链接不能跨分区创建而软链接可以,因为软链接指向的是文件名。
- 硬链接不能指向目录
- 如果说目录有硬链接那么可能引入死循环,但是你可能会疑问软链接也会陷入循环啊,答案当然不是,因为软链接是存在自己的数据的,可以查看自己的文件属性,既然可以判断出来软链接,那么自然不会陷入循环,并且系统在连续遇到 8 个符号链接后就停止遍历。但是硬链接可就不行了,因为他的 inode 号一致,所以就判断不出是硬链接,所以就会陷入死循环了。
参考链接:



文章内容不错,纠个小错
“因为每个分区各有一套不同的inode表,所以硬链接不能跨分区创建而软连接可以,因为软连接指向的书文件名”
-> “是文件名”
还有文章中有时候写的是“软链接”有时候是“软连接”,最好能统一一下。
感谢指正
寫得不錯,頂一個