文章内容如有错误或排版问题,请提交反馈,非常感谢!
Kedro简介
Kedro是一个开源的Python框架,用于构建可重用、可扩展和可维护的数据科学项目。由QuantumBlack(隶属于麦肯锡公司)开发,Kedro的设计理念是将软件工程的最佳实践应用于数据科学和机器学习项目中。
核心理念
- 模块化: Kedro强调项目的模块化和结构化,确保代码的可重用性和可维护性。
- 可重现性: 提供机制来确保数据处理管道的可重现性,支持版本控制和环境管理。
- 可扩展性: 支持将项目扩展到生产环境,能够与各种数据存储和计算平台集成。
核心组件
- 目录结构: Kedro使用标准化的目录结构来组织项目,包括src(源代码)、data(数据)、conf(配置)等文件夹。
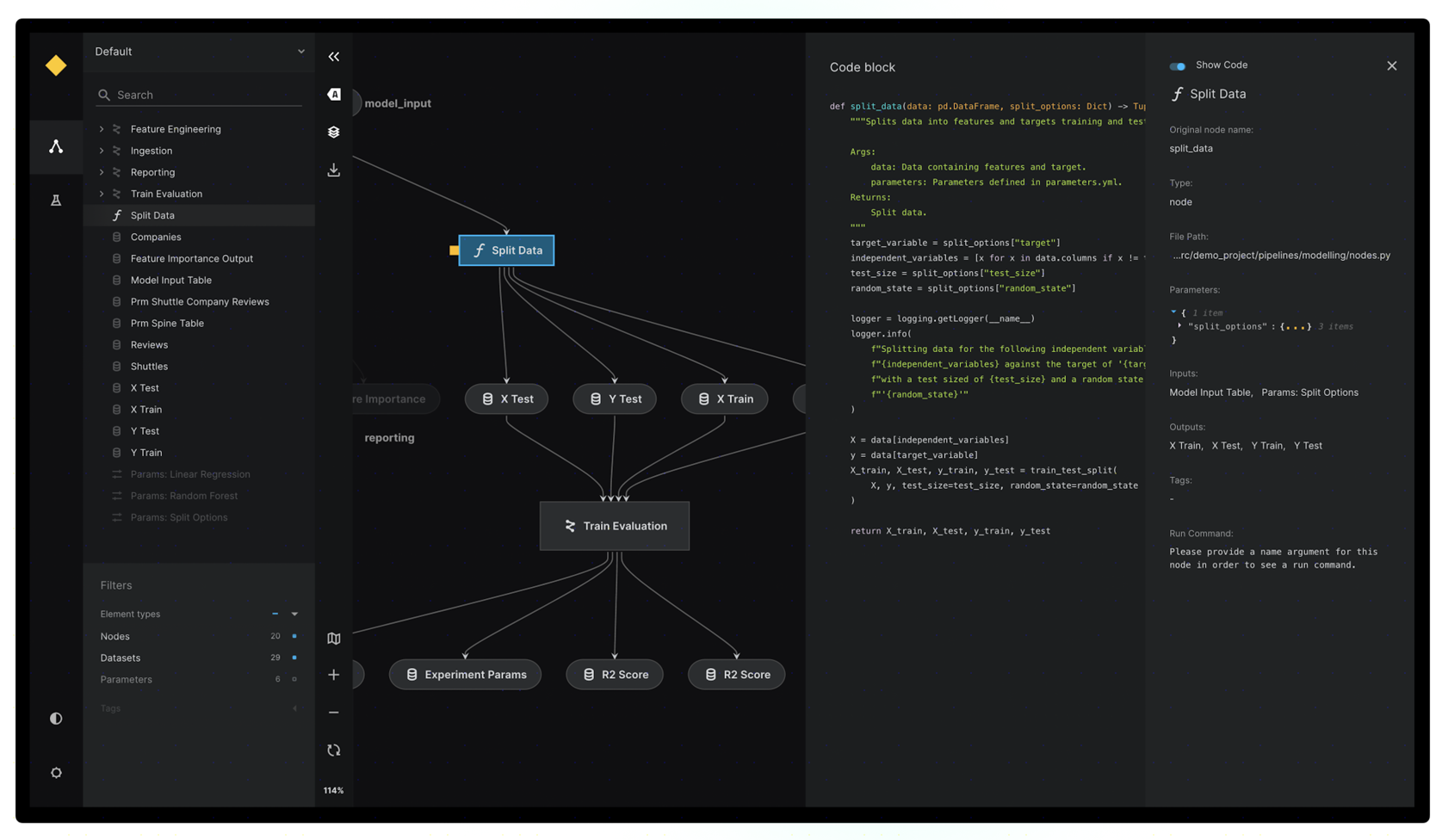
- 数据管道(Pipelines): 管道由节点(Node)组成,每个节点代表一个函数,处理数据并生成输出。节点之间通过数据集(Dataset)连接。
- 数据集(Datasets): 数据集是Kedro中用于读写数据的抽象层,支持多种数据格式和存储位置(如CSV、Parquet、SQL、S3等)。
- 配置管理: 使用配置文件(YAML格式)来管理参数、数据源和其他项目设置,支持多环境配置。
- 插件系统: Kedro支持插件扩展,允许开发者添加自定义功能或集成第三方工具。
主要特性
- 结构化项目模板: 提供预定义的项目模板,帮助团队快速启动新项目,确保一致性和最佳实践。
- 数据工程工具: 支持数据处理、数据清洗和特征工程,适合构建复杂的数据管道。
- 版本控制: 集成版本控制工具(如Git),支持数据和代码的版本化管理。
- 可视化: 提供Kedro-Viz插件,用于可视化数据管道,帮助开发者理解和优化工作流。
- 生产化准备: 设计时考虑到生产环境的需求,支持与Airflow、MLflow等工具集成,便于部署和监控。
典型使用场景
- 数据准备和清洗: 构建数据管道以提取、清洗和转换原始数据,生成用于建模的数据集。
- 特征工程: 设计和实现特征工程管道,生成用于机器学习模型的特征。
- 模型训练和评估: 管理模型训练、验证和评估过程,确保实验的可重现性。
- 生产部署: 准备将数据管道和模型部署到生产环境,支持自动化和持续交付。
安装与使用
安装Kedro
使用pip安装Kedro:pip install kedro创建新项目
使用Kedro命令行工具创建新项目:
kedro new --starter=pandas-iris
选择项目名称和目录,Kedro会生成标准化的项目结构。
定义数据管道
在src/<project_name>/pipelines目录下定义管道和节点。
示例节点定义:
from kedro.pipeline import node, Pipeline
def preprocess_data(data):
# 数据处理逻辑
return processed_data
def create_pipeline(**kwargs):
return Pipeline([
node(
func=preprocess_data,
inputs="raw_data",
outputs="processed_data",
name="preprocess_data_node"
)
])
配置项目
在conf/base目录下管理项目配置,包括数据源、参数等。
使用YAML文件定义配置,例如catalog.yml定义数据集:
raw_data:
type: pandas.CSVDataSet
filepath: data/01_raw/data.csv
运行项目
使用Kedro CLI运行数据管道:kedro run可视化管道
安装Kedro-Viz插件以可视化管道:
pip install kedro-viz
运行可视化工具:kedro viz参考链接:


