Elasticsearch分析器原理
在安装分词工具前我们需要先了解下一个概念:分析器(Analyzer)。分析器是三个顺序执行的组件的结合(字符过滤器,分词器,标记过滤器)。即分词器包含在分析器中。分析器的内部就是一条流水线:
- Step1 字符过滤器(Character filters)
- Step2 分词器(Tokenization)
- Step3 标记过滤器(Token filters)

字符过滤器
字符过滤器是让字符串在被分词前变得更加”整洁”。例如,如果我们的文本是HTML格式,它可能会包含一些我们不想被索引的HTML标签,诸如<p>或<div>。我们可以使用html_strip字符过滤器来删除所有的HTML标签,并且将HTML实体转换成对应的Unicode字符,比如将&转成&。一个分析器可能包含零到多个字符过滤器。
Elasticsearch内置的character filter:
| character filter | logical name | description |
| mapping char filter | mapping | 根据配置的映射关系替换字符 |
| html strip char filter | html_strip | 去掉HTML元素 |
| pattern replace char filter | pattern_replace | 用正则表达式处理字符串 |
分词器
一个分析器必须包含一个分词器。分词器将字符串分割成单独的词(terms)或标记(tokens)。standard分析器使用standard分词器将字符串分割成单独的字词,删除大部分标点符号,但是现存的其他分词器会有不同的行为特征。
例如,keyword分词器输出和它接收到的相同的字符串,不做任何分词处理。whitespace分词器只通过空格来分割文本。pattern分词器可以通过正则表达式来分割文本。
Elasticsearch内置分词器:
| tokenizer | logical name | description |
| standard tokenizer | standard | |
| edge ngram tokenizer | edgeNGram | |
| keyword tokenizer | keyword | 不分词 |
| letter analyzer | letter | 按单词分 |
| lowercase analyzer | lowercase | letter tokenizer, lowercase filter |
| ngram analyzers | nGram | |
| whitespace analyzer | whitespace | 以空格为分隔符拆分 |
| pattern analyzer | pattern | 定义分隔符的正则表达式 |
| uax email url analyzer | uax_url_email | 不拆分url和email |
| path hierarchy analyzer | path_hierarchy | 处理类似/path/to/somthing样式的字符串 |
标记过滤器
分词结果的标记流 会根据各自的情况,传递给特定的标记过滤器。标记过滤器可能修改,添加或删除标记。每个词都通过所有标记过滤(token filters),它可以修改词(例如将”Quick”转为小写),去掉词(例如停用词像”a”、”and”、”the”等等),或者增加词(例如同义词像”jump”和”leap”)等。一个分析器可能包含零到多个标记过滤器。
Elasticsearch内置的token filter:
| token filter | logical name | description |
| standard filter | standard | |
| ascii folding filter | asciifolding | |
| length filter | length | 去掉太长或者太短的 |
| lowercase filter | lowercase | 转成小写 |
| ngram filter | nGram | |
| edge ngram filter | edgeNGram | |
| porter stem filter | porterStem | 波特词干算法 |
| shingle filter | shingle | 定义分隔符的正则表达式 |
| stop filter | stop | 移除stopwords |
| word delimiter filter | word_delimiter | 将一个单词再拆成子分词 |
| stemmer token filter | stemmer | |
| stemmer override filter | stemmer_override | |
| keyword marker filter | keyword_marker | |
| keyword repeat filter | keyword_repeat | |
| kstem filter | kstem | |
| snowball filter | snowball | |
| phonetic filter | phonetic | |
| synonym filter | synonyms | 处理同义词 |
| compound word filter | dictionary_decompounder,hyphenation_decompounder | 分解复合词 |
| reverse filter | reverse | 反转字符串 |
| elision filter | elision | 去掉缩略语 |
| truncate filter | truncate | 截断字符串 |
| unique filter | unique | |
| pattern capture filter | pattern_capture | |
| pattern replace filte | pattern_replace | 用正则表达式替换 |
| trim filter | trim | 去掉空格 |
| limit token count filter | limit | 限制token数量 |
| hunspell filter | hunspell | 拼写检查 |
| common grams filter | common_grams | |
| normalization filter | arabic_normalization,persian_normalization |
Elasticsearch已经默认构造了8个Analyzer。
| analyzer | logical name | description |
| standard analyzer | standard | 标准分析器是Elasticsearch默认使用的分析器。对于文本分析,它对于任何语言都是最佳选择。它根据Unicode Consortium的定义的单词边界(word boundaries)来切分文本,然后去掉大部分标点符号。最后,把所有词转为小写。standard tokenizer,standard filter,lowercase filter,stop filter |
| simple analyzer | simple | 简单分析器将非单个字母的文本切分,然后把每个词转为小写。 |
| stop analyzer | stop | lowercase tokenizer,stop filter |
| keyword analyzer | keyword | 不分词,内容整体作为一个token(not_analyzed) |
| pattern analyzer | whitespace | 空格分析器依据空格切分文本。它不转换小写。正则表达式分词,默认匹配\W+ |
| language analyzers | lang | 特定语言分析器适用于很多语言。它们能够考虑到特定语言的特性。例如,english分析器自带一套英语停用词库——像and或the这些与语义无关的通用词。这些词被移除后,因为语法规则的存在,英语单词的主体含义依旧能被理解。 |
| snowball analyzer | snowball | standard tokenizer,standard filter,lowercase filter,stop filter,snowball filter |
| custom analyzer | custom | 一个Tokenizer,零个或多个TokenFilter,零个或多个CharFilter |
虽然Elasticsearch内置了一系列的分析器,但是真正的强大之处在于定制你自己的分析器。你可以通过在配置文件中组合字符过滤器,分词器和标记过滤器,来满足特定数据的需求。可以通过「Setting API」构造Analyzer。
PUT /my-index/_settings
{
"index":{
"analysis":{
"analyzer":{
"customHTMLSnowball":{
"type":"custom",
"char_filter":[
"html_strip"
],
"tokenizer":"standard",
"filter":[
"lowercase",
"stop",
"snowball"
]
}}}}
以上自定义的Analyzer名为customHTMLSnowball,代表的含义:
- 移除html标签(html_strip character filter),比如<p><a><div>。
- standard分词,去除标点符号(standard tokenizer)
- 把大写的单词转为小写(lowercase token filter)
- 过滤停用词(stop token filter),比如「the」「they」「i」「a」「an」「and」。
- 提取词干(snowball token filter,snowball雪球算法是提取英文词干最常用的一种算法。)
- cats->cat
- catty->cat
- stemmer->stem
- stemming->stem
- stemmed->stem
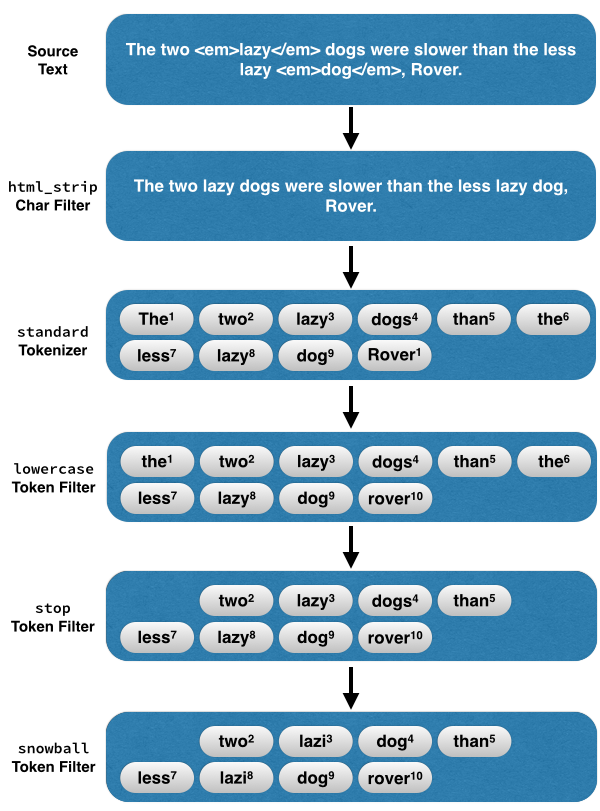
例如:The two <em>lazy</em> dogs,were slower than the less lazy <em>dog</em>
这段文本交给customHTMLSnowball,它是这样处理的:
第三方分词工具的安装
Elasticsearch 本身对中文分词和搜索比较局限。内置的标准分词器只是简单的将中文的每一个汉字作为一个词(token)分开。具体可以通过如下方式查看效果:
http://192.168.19.130:9200/_analyze?analyzer=standard&pretty=true&text=Elasticsearch 分词插件的安装
{
"tokens": [{
"token": "elasticsearch",
"start_offset": 0,
"end_offset": 13,
"type": "<ALPHANUM>",
"position": 0
}, {
"token": "分",
"start_offset": 13,
"end_offset": 14,
"type": "<IDEOGRAPHIC>",
"position": 1
}, {
"token": "词",
"start_offset": 14,
"end_offset": 15,
"type": "<IDEOGRAPHIC>",
"position": 2
}, {
"token": "插",
"start_offset": 15,
"end_offset": 16,
"type": "<IDEOGRAPHIC>",
"position": 3
}, {
"token": "件",
"start_offset": 16,
"end_offset": 17,
"type": "<IDEOGRAPHIC>",
"position": 4
}, {
"token": "的",
"start_offset": 17,
"end_offset": 18,
"type": "<IDEOGRAPHIC>",
"position": 5
}, {
"token": "安",
"start_offset": 18,
"end_offset": 19,
"type": "<IDEOGRAPHIC>",
"position": 6
}, {
"token": "装",
"start_offset": 19,
"end_offset": 20,
"type": "<IDEOGRAPHIC>",
"position": 7
}]
}
此分词方法可以保证查全率 100%,但是查准率却非常的低。所以就有必要引入其他的分词方法(细说分词)。
elasticsearch-analysis-ik 安装
在安装分词插件的时候需要注意必须选择对应的版本,由于安装的 elasticsearch 使用的是 2.4.0 版本,则对应的 IK 版本应该为 v1.10.0。
具体源代码及对应版本信息可在此页面获取:https://github.com/medcl/elasticsearch-analysis-ik/releases
安装 ik 分词插件,可以选择自己编译安装或选择下载已经编译好的文件进行安装。这里主要介绍的是编译安装。编译使用的是 Maven。
安装 meavn
从https://maven.apache.org/download.cgi 获取下载链接。并下载解压。
wget http://mirror.bit.edu.cn/apache/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz tar -zxvf apache-maven-3.3.9-bin.tar.gz ln -s apache-maven-3.3.9 maven
更新配置文件,设置 maven 环境变量:vi /etc/profile ,在文件中追加入内容:
export M2_HOME=/usr/local/maven export M2=$M2_HOME/bin PATH=$M2:$PATH
使用 source /etc/profile 使环境变量生效。完成后输入 mvn -version 查看是否安装成功。
[root@localhost local]# mvn -version Apache Maven 3.3.9 (bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015-11-11T00:41:47+08:00) Maven home: /usr/local/maven Java version: 1.8.0_101, vendor: Oracle Corporation Java home: /usr/local/jdk1.8.0_101/jre Default locale: en_US, platform encoding: UTF-8 OS name: "linux", version: "3.10.0-327.28.2.el7.x86_64", arch: "amd64", family: "unix"
编译 elasticsearch-analysis-ik
下载对应的版本,并进行编译:
wget https://github.com/medcl/elasticsearch-analysis-ik/archive/v1.10.0.tar.gz cd elasticsearch-analysis-ik-1.10.0 mvn package
编译完成后,生成的内容在:target/releases/elasticsearch-analysis-ik-1.10.0.zip
此编译好的版本也可从 https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v1.10.0/elasticsearch-analysis-ik-1.10.0.zip 下载。
安装 elasticsearch-analysis-ik
安装工作非常的简单,只需要将编译好的文件解压到相应的目录下,并重启 elasticsearch 即可。
unzip target/releases/elasticsearch-analysis-ik-1.10.0.zip -d /usr/local/elasticsearch-2.4.0/plugins/ik
重启方法见elasticsearch 安装注意:需要将插件的文件归属修改为安装过程中添加的 elastic 用户后再进行重启。
chown -R elastic:elastic /usr/local/elasticsearch-2.4.0/plugins/ik
至此,elasticsearch-analysis-ik 安装完毕elasticsearch-analysis-ik 分词的测试
http://192.168.19.130:9200/_analyze?analyzer=ik&pretty=true&text=Elasticsearch 分词插件的安装
{
"tokens": [{
"token": "elasticsearch",
"start_offset": 0,
"end_offset": 13,
"type": "CN_WORD",
"position": 0
}, {
"token": "elastic",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 1
}, {
"token": "分词",
"start_offset": 13,
"end_offset": 15,
"type": "CN_WORD",
"position": 2
}, {
"token": "词",
"start_offset": 14,
"end_offset": 15,
"type": "CN_WORD",
"position": 3
}, {
"token": "插件",
"start_offset": 15,
"end_offset": 17,
"type": "CN_WORD",
"position": 4
}, {
"token": "插",
"start_offset": 15,
"end_offset": 16,
"type": "CN_WORD",
"position": 5
}, {
"token": "件",
"start_offset": 16,
"end_offset": 17,
"type": "CN_CHAR",
"position": 6
}, {
"token": "安装",
"start_offset": 18,
"end_offset": 20,
"type": "CN_WORD",
"position": 7
}]
}
可以将链接中的 analyzer=ik 修改为 analyzer=ik_max_word 或 analyzer=ik_smart,ik 默认使用的是 ik_max_word。两者的区别:
- ik_max_word: 会将文本做最细粒度的拆分,比如会将”中华人民共和国国歌”拆分为”中华人民共和国, 中华人民, 中华, 华人, 人民共和国, 人民, 人, 民, 共和国, 共和, 和, 国国, 国歌”,会穷尽各种可能的组合;
- ik_smart: 会做最粗粒度的拆分,比如会将”中华人民共和国国歌”拆分为”中华人民共和国, 国歌”。
一般索引(文档)的时候用 ik_max_word,搜索(搜索词)的时候用 ik_smart。
elasticsearch-analysis-ansj 的安装
相关的流程与安装 ik 类似,这里就不做过多的介绍了。项目地址:https://github.com/4onni/elasticsearch-analysis-ansj
目前默认内置三个分词器
- index_ansj 是索引分词, 尽可能分词出所有结果
- query_ansj 是搜索分词, 是索引分词的子集, 保证了准确率
- dic_ansj 是用户自定义词典优先策略
同样可以类似 ik 分词的方法进行测试。
elasticsearch-analysis-mmseg 的安装
项目地址:https://github.com/medcl/elasticsearch-analysis-mmseg
注意到该项目的 releases 中 v2.3.4 的源码,而我们安装的是 2.4.0 版本的 maven,解决方案非常的简单,下载完 v2.3.4 的源代码以后,修改 pom.xml 文件,将文件中 <elasticsearch.version>2.3.4</elasticsearch.version> 修改为 <elasticsearch.version>2.4.0</elasticsearch.version>,然后再编译安装。
这个插件提供的
- analyzers: mmseg_maxword, mmseg_complex, mmseg_simple
- tokenizers: mmseg_maxword, mmseg_complex, mmseg_simple
- token_filter: cut_letter_digit
需要自定义分析器,可以将如下内容添加到 config/elasticsearch.yml 文件中。
index:
analysis:
analyzer:
mmseg_maxword:
type: custom
filter:
- lowercase
tokenizer: mmseg_maxword
mmseg_maxword_with_cut_letter_digi:
type: custom
filter:
- lowercase
- cut_letter_digit
tokenizer: mmseg_maxword
elasticsearch-analysis-jieba 安装
项目地址:https://github.com/huaban/elasticsearch-analysis-jieba
同样需要修改 pom.xml 中 elasticsearch 的版本后再进行编译。 本插件包括 jieba analyzer、jieba tokenizer、jieba tokenfilter,有三种模式供选择。
- jieba_index 主要用于索引分词,分词粒度较细
- jieba_search 主要用于查询分词,分词粒度较粗
- jieba_other 全角转半角、大写转小写、字符分词
elasticsearch-analysis-stconvert 安装
elasticsearch-analysis-stconvert 是一个简体繁体互转的插件,与分词的关系不大,但是原理上与分词相似。通过转换及时文档中出现繁简内容或搜索中出现繁简内容都可以匹配到有效的数据。
项目地址:https://github.com/medcl/elasticsearch-analysis-stconvert
此插件编译过程中会报如下错误:
[ERROR] Failed to execute goal on project elasticsearch-analysis-stconvert: Could not resolve dependencies for project com.infinitbyte: elasticsearch-analysis-stconvert: jar: 1.9.0: Failed to collect dependencies at log4j: log4j: jar: 1.2.17: Failed to read artifact descriptor for log4j: log4j: jar: 1.2.17: Could not transfer artifact log4j: log4j: pom: 1.2.17 from/to central (https://repo.maven.apache.org/maven2): Connection reset -> [Help 1]
解决方案是修改 pom.xml,将 log4j 的版本由 1.2.17 修改为 1.2.16。
<dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.16</version> </dependency>
此插件提供了
- analyzers: stconvert, tsconvert, stconvert_keep_both, tsconvert_keep_both
- tokenizers: stconvert, tsconvert, stconvert_keep_both, tsconvert_keep_both
- char-filters: stconvert, tsconvert.
token-filters: stconvert, tsconvert, stconvert_keep_both, tsconvert_keep_both
elasticsearch-analysis-pinyin 安装
pinyin 分词器可以让用户输入拼音,就能查找到相关的关键词。比如在用户输入 fenci,就能匹配到分词。这样的体验还是非常好的。
项目地址:https://github.com/medcl/elasticsearch-analysis-pinyin
这个插件提供了:
- analyzer: pinyin
- tokenizer: pinyin
- token-filter: pinyin
拼音分词还涉及 autocompletion(自动提示),涉及到很多其他的相关设置,下回再详细介绍。
至此,主流的分词工具 介绍完毕,安装完成分词工具以后如何应用到具体的项目中,尽情期待下一遍 elasticsearch 的文章,尽情期待。
参考链接:


