文章内容如有错误或排版问题,请提交反馈,非常感谢!
Doris简介
Apache Doris是一个现代化的实时数据分析数据库,旨在提供高性能的交互式SQL查询分析。它最初由百度开发,并贡献给Apache软件基金会。Doris的设计目标是为大规模数据分析提供简单易用、快速且高效的解决方案。
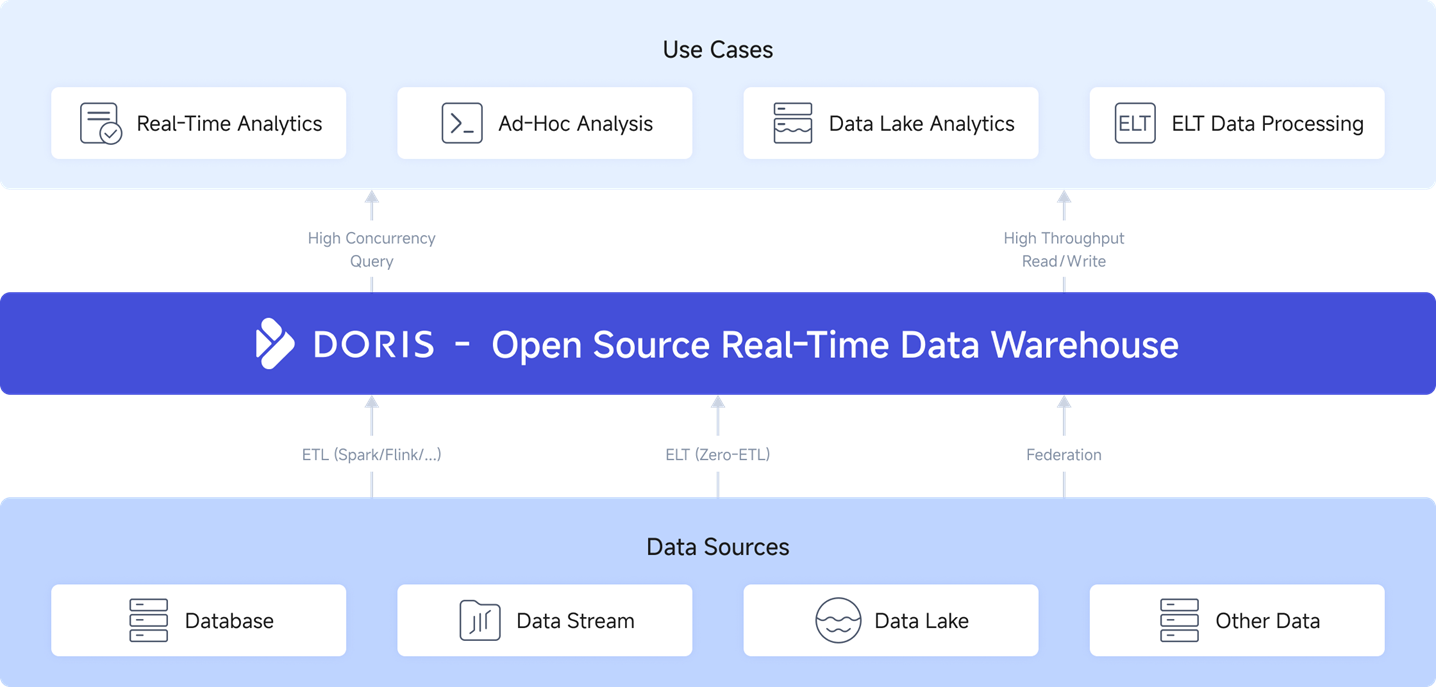
核心特性
- 高性能:
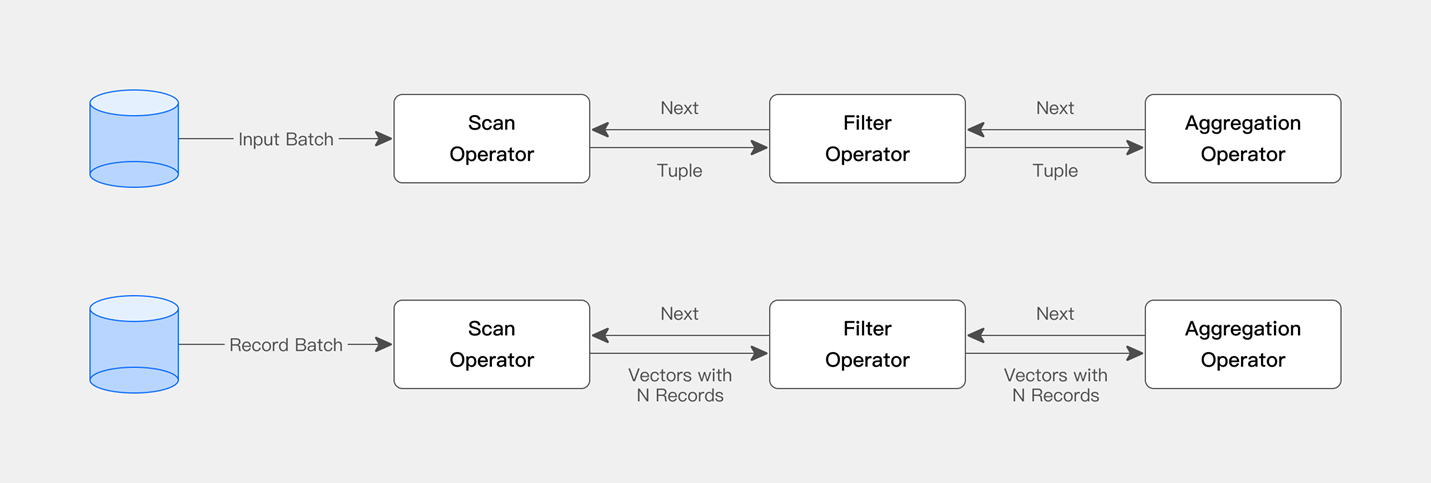
- Doris采用列式存储和多级索引技术,能够显著提高查询性能。
- 支持实时数据分析,能够在低延迟下处理大量并发查询。
- 简化架构:
- Doris提供了一体化的解决方案,集成了数据存储、查询和分析功能。
- 无需依赖外部组件,如HDFS或Hive,简化了系统架构和运维。
- 易用性:
- 提供了与MySQL兼容的SQL接口,使用户能够快速上手。
- 支持多种数据导入方式,包括批量导入和流式导入。
- 弹性扩展:
- 支持水平扩展,可以通过增加节点来提高系统的存储容量和计算能力。
- 具有良好的容错性和高可用性。
- 多种数据模型:
- 支持明细模型(Detail Model)、聚合模型(Aggregate Model)和唯一模型(Unique Model),适用于不同的应用场景。
使用场景
- 实时数据分析:适用于需要低延迟、高并发的实时数据分析场景,如实时报表、仪表盘和监控系统。
- 交互式BI分析:支持快速的交互式查询,适合与BI工具集成进行复杂的数据分析。
- 大规模数据处理:适合处理大规模的历史数据和日志数据,提供高效的数据聚合和分析能力。
Doris的系统架构
核心组件
Doris的架构主要包括以下几个组件:
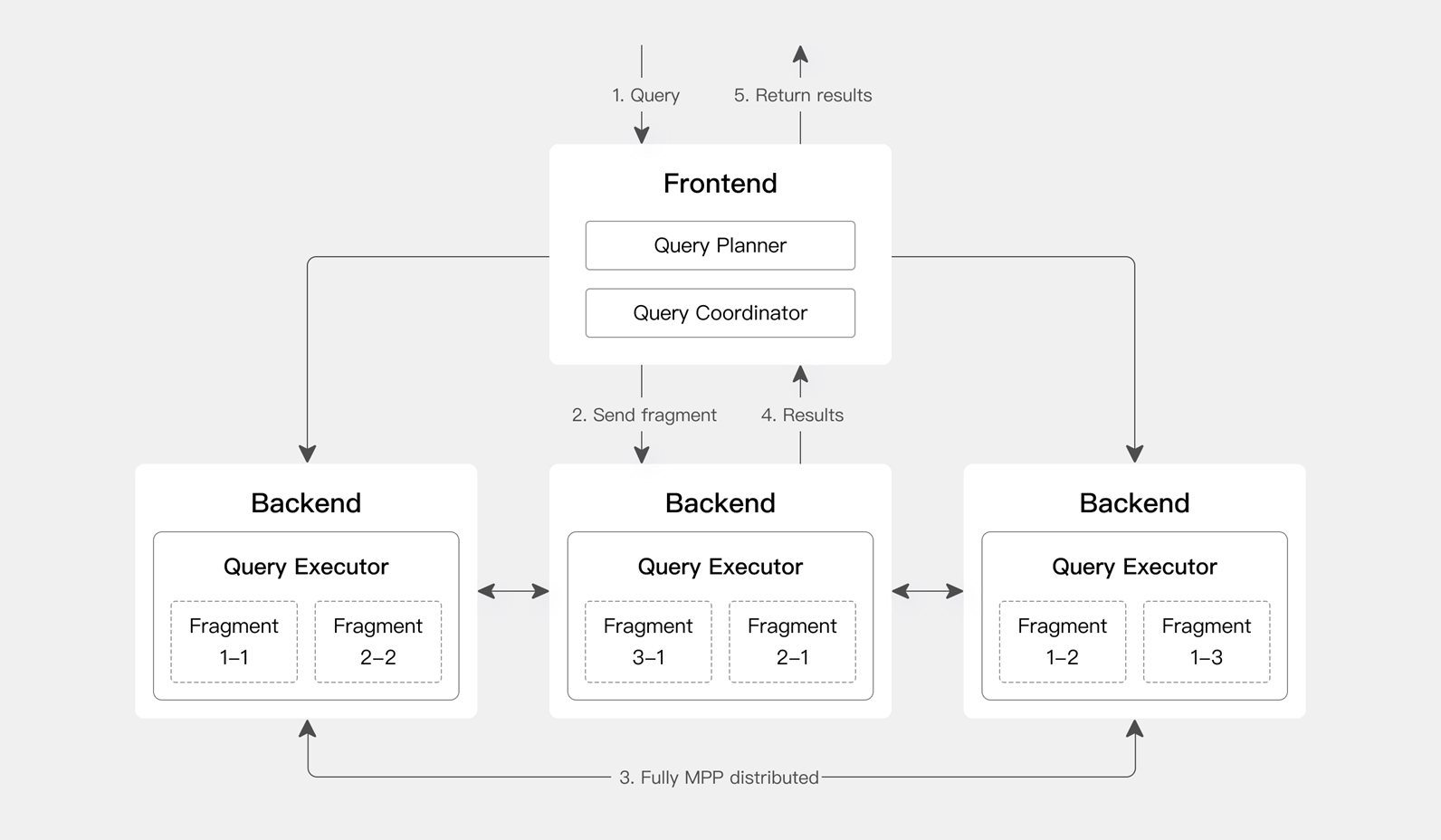
- Frontend(FE):
- 负责SQL解析、查询优化和计划生成。
- 管理元数据和用户请求,协调数据的读写操作。
- Backend(BE):
- 负责数据存储和计算。
- BE节点执行实际的数据查询和写入操作,支持列式存储和多级索引。
- Broker:
- 负责数据的导入和导出,支持从外部存储系统(如HDFS、S3)中读取数据。
- 提供了高效的数据加载能力。
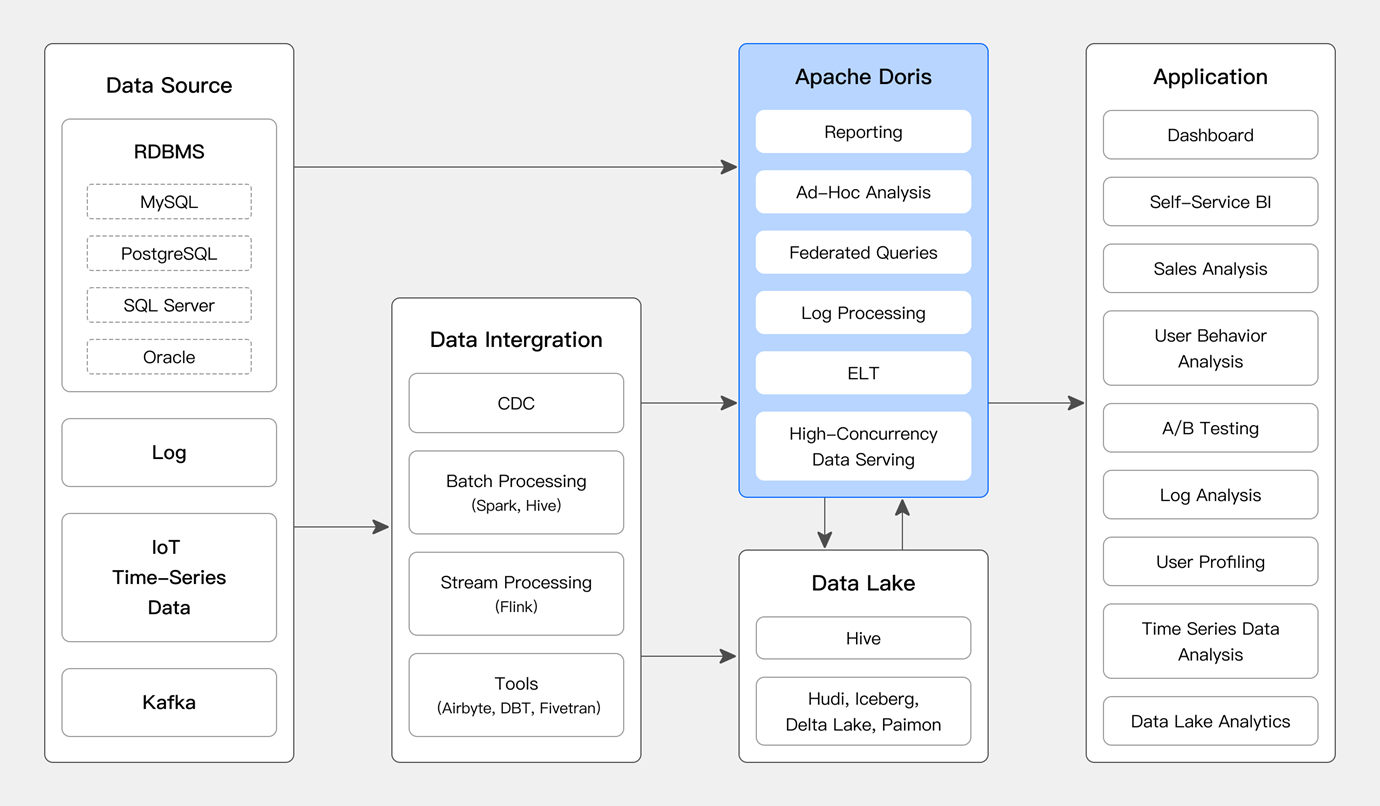
数据导入
Doris支持多种数据导入方式:
- Stream Load:支持通过HTTP协议进行流式数据导入,适用于实时数据写入。
- Broker Load:支持从外部存储系统(如HDFS、S3)中批量导入数据,适用于大规模数据导入。
- Routine Load:支持持续从消息队列(如Kafka)中导入数据,实现实时数据同步。
- Insert:支持通过SQL语句直接插入数据。
类似的开源项目
Apache Doris是一个专注于在线分析处理(OLAP)场景的开源MPP数据库。与之类似的开源实现主要集中在支持大规模数据分析、列式存储和高性能查询的数据库系统。以下是一些与Apache Doris类似的开源项目:
- Apache Druid:Apache Druid是一个实时分析数据库,专为高性能查询和实时数据摄取而设计。它支持列式存储、分布式架构和灵活的多维分析能力,适合需要低延迟查询的实时分析场景。
- ClickHouse:ClickHouse是一个面向实时分析的列式数据库管理系统,具有极高的查询性能和良好的压缩比。它适用于需要快速数据分析和高并发查询的应用场景。
- Apache Kylin:Apache Kylin是一个分布式分析引擎,提供多维分析(OLAP)能力。它通过预计算的方式支持大规模数据集上的快速查询,适合离线分析和报表生成。
- Greenplum:Greenplum是一个开源的分布式数据库系统,基于PostgreSQL构建,专为数据仓库和大规模并行处理(MPP)设计,支持复杂的分析查询和数据挖掘任务。
- Presto:Presto是一个分布式SQL查询引擎,能够对多个数据源进行交互式查询。虽然它不是一个存储引擎,但在处理大规模数据分析方面具有很高的灵活性和性能。
- Apache Hive:Apache Hive是一个数据仓库软件,构建在Hadoop之上,提供SQL风格的查询接口。虽然主要用于批处理,但也支持交互式查询和OLAP场景。
- Apache Impala:Apache Impala是一个为Hadoop设计的高性能SQL查询引擎,支持低延迟和高并发的交互式分析查询。
- Pinot:Apache Pinot是一个实时分布式OLAP数据存储和分析平台,专为低延迟查询和高吞吐量而设计,适合处理实时流数据和批量数据。
这些系统各有其独特的设计目标和适用场景。在选择具体的开源实现时,应该根据具体的业务需求、数据规模、查询复杂性和实时性要求进行评估。每个系统在性能、扩展性、功能特性和社区支持方面都有不同的优势,因此选择时需要综合考虑。
参考链接:


