文章内容如有错误或排版问题,请提交反馈,非常感谢!
Pandas-profiling(2016)被称为EDA(Exploratory Data Analysis)分析的典型工具,然而Pandas-profiling的一个主要缺点是它提供的是数据集的侧写,而EDA是一个迭代的过程,分析过程中会对对数据不断进行质疑、理解、处理、转换等。Pandas-profiling严格的分析框架与当前EDA的最佳实践背道而驰。
Dataprep.eda(2020)是一个Python库,它支持迭代和以任务为中心的分析,就像EDA注定要做的那样。dataprep.eda比Pandas-profiling更适合进行探索分析主要有以下四点:
1.更好的API设计
dataprep.eda中的plot()函数。为了理解如何使用这个函数有效地执行EDA,下面给出了分析人员意图的函数调用的语法:
- plot(df):我想要一个数据集的概览
- plot(df,”col_1″):我想要深入了解col_1这一列
- plot(df,”col_1″,”col_2″):我想了解col_1与col_2之间的关系
为了看到这一点的实际应用,我们将使用一个韩国新冠肺炎数据集,我们从数据集的概述开始:
# pip install dataprep
from dataprep.eda import plot
import pandas as pd
df = pd.read_csv("data/PatientInfo.csv")
df["confirmed_date"] = pd.to_datetime(df["confirmed_date"])
plot(df)
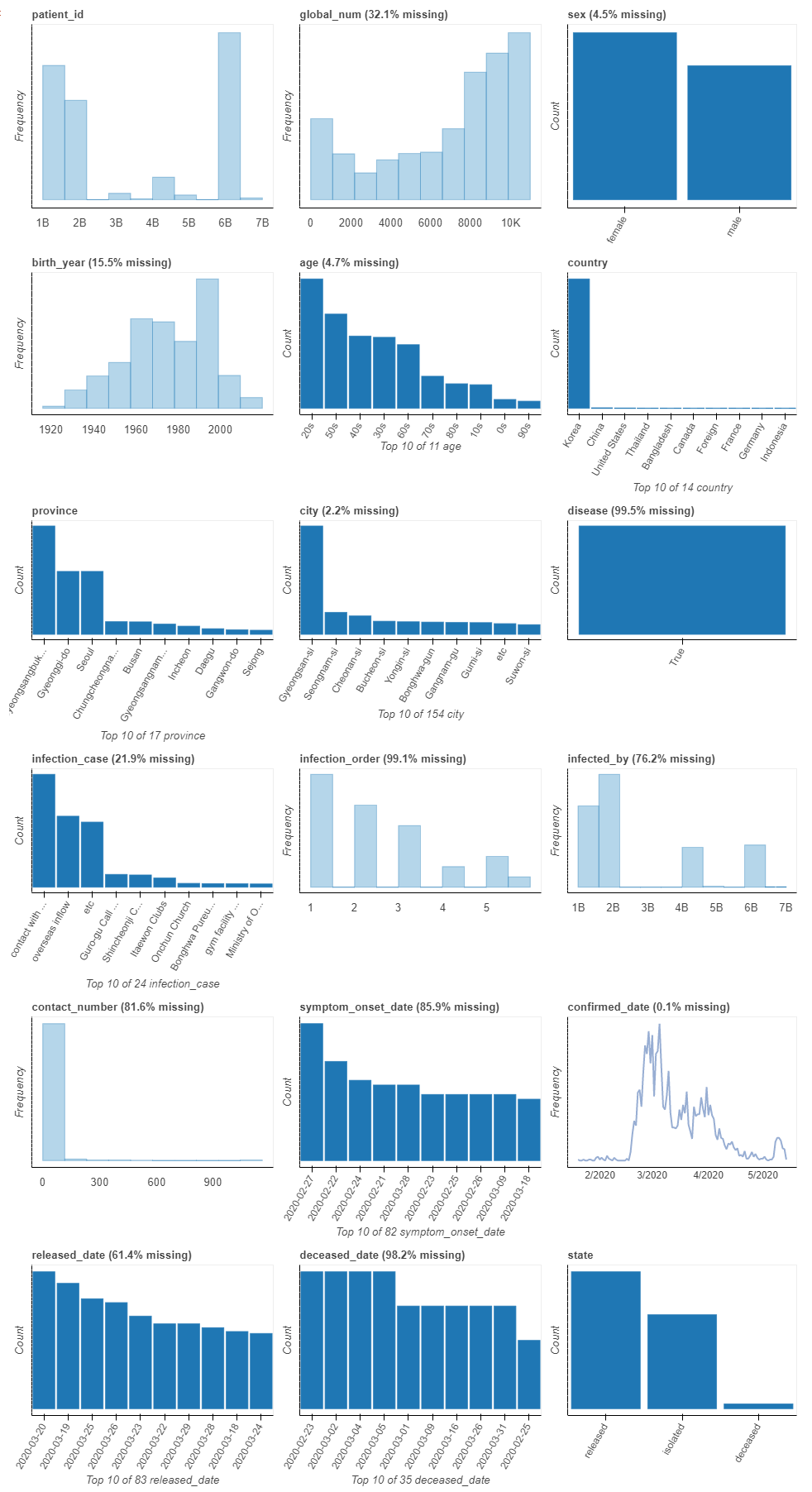
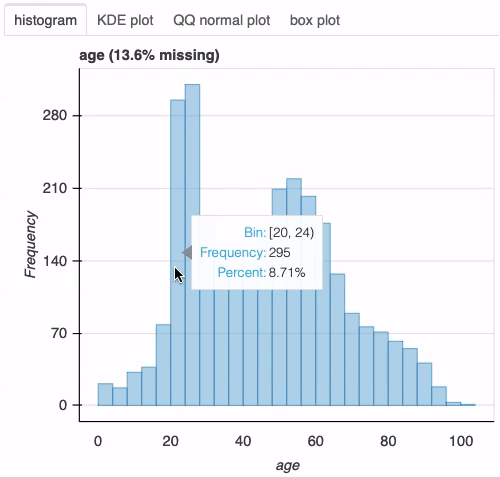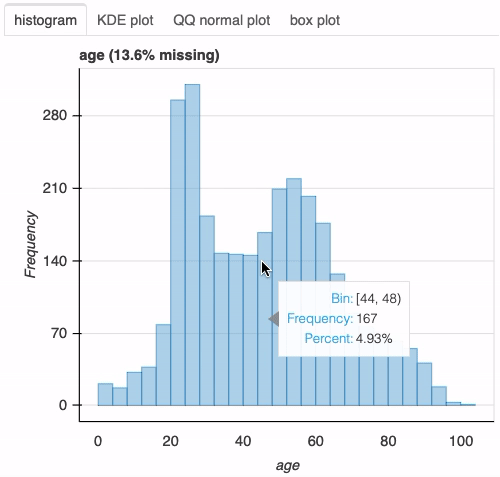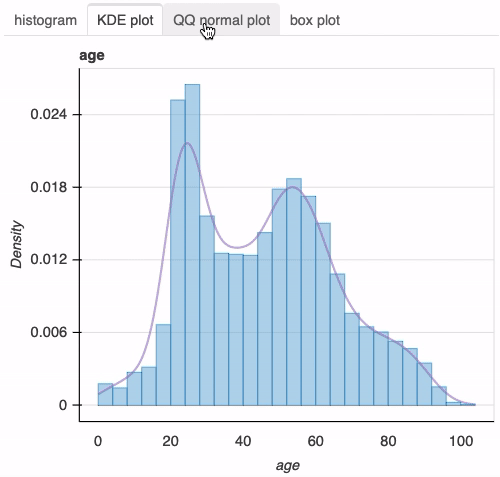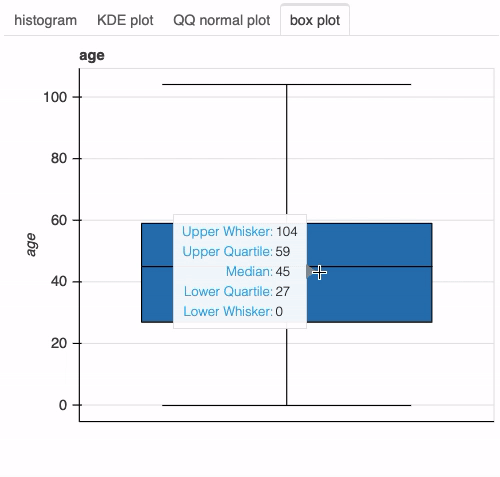
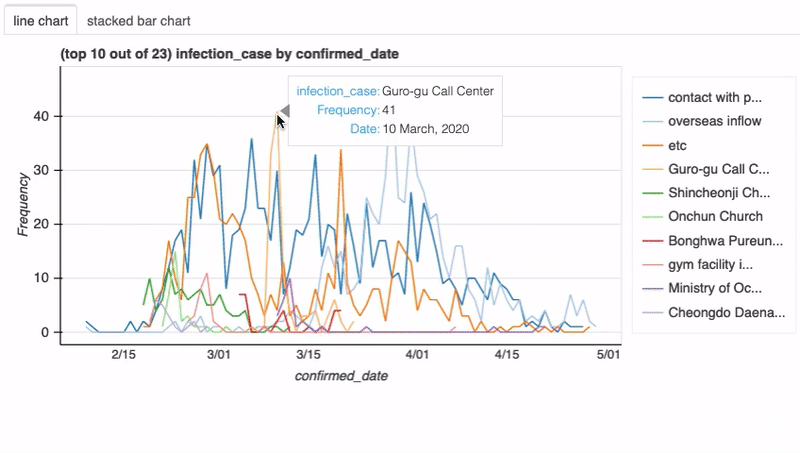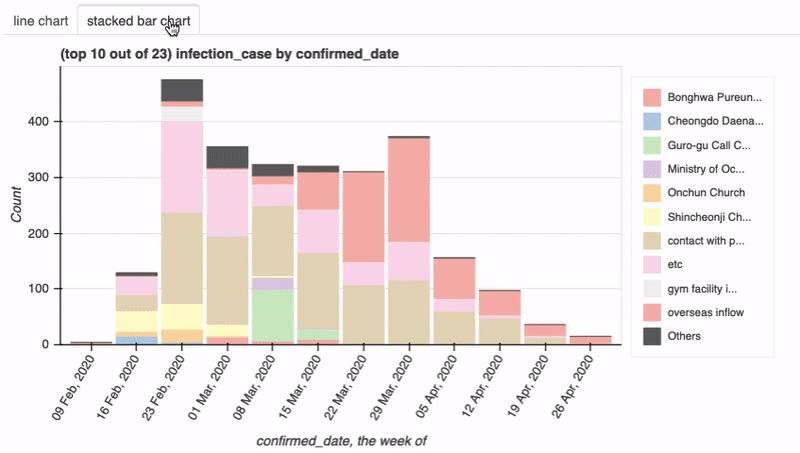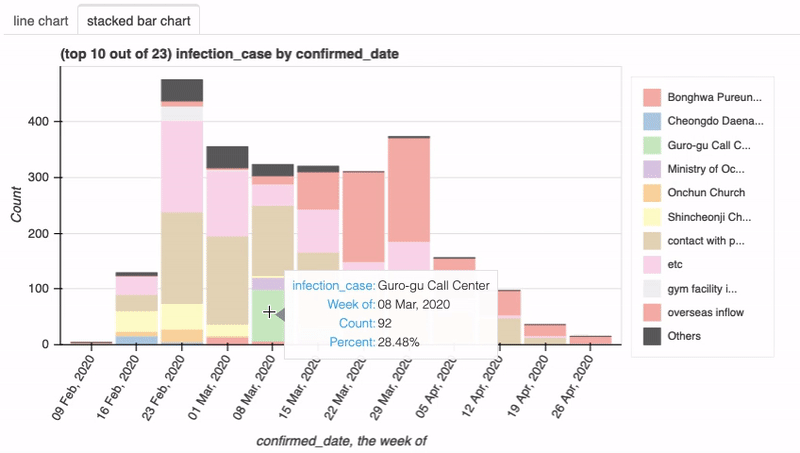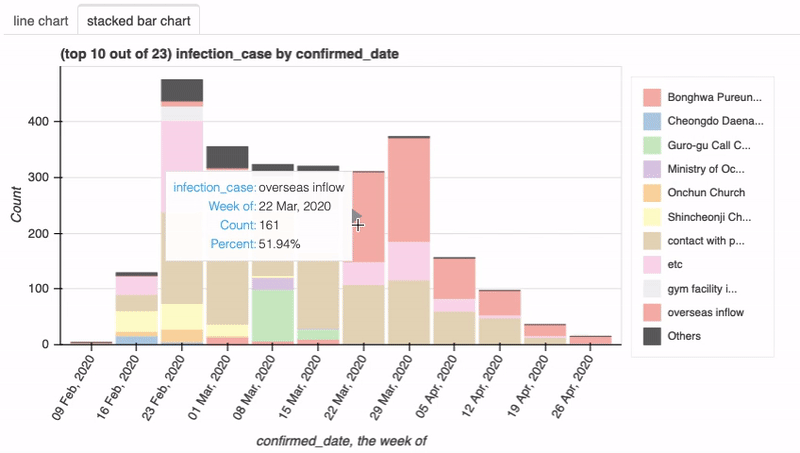
注意到birth_year这有一个双峰分布,让我们了解更多关于这个列的信息:
df["age"] = 2020 - df["birth_year"] plot(df, "age", bins=26)
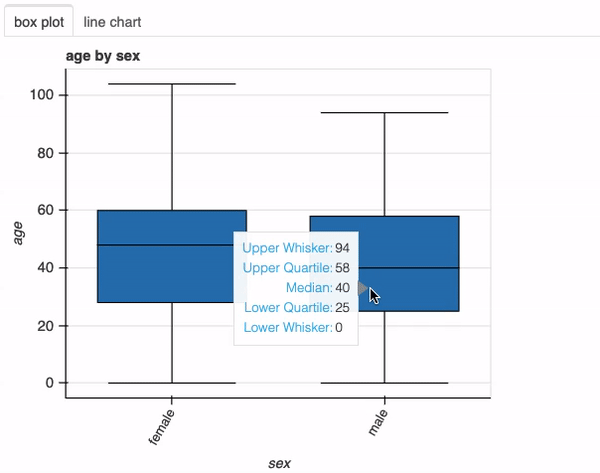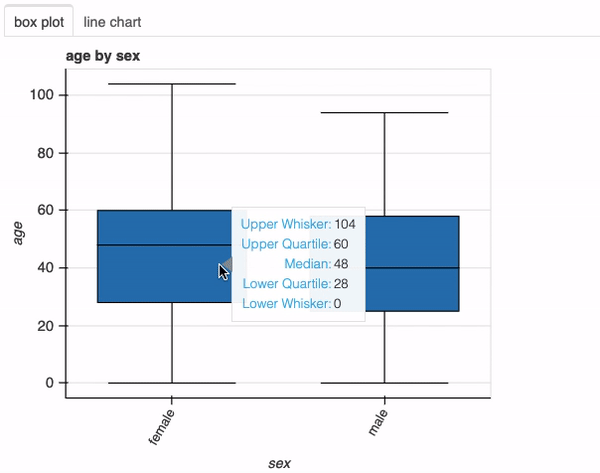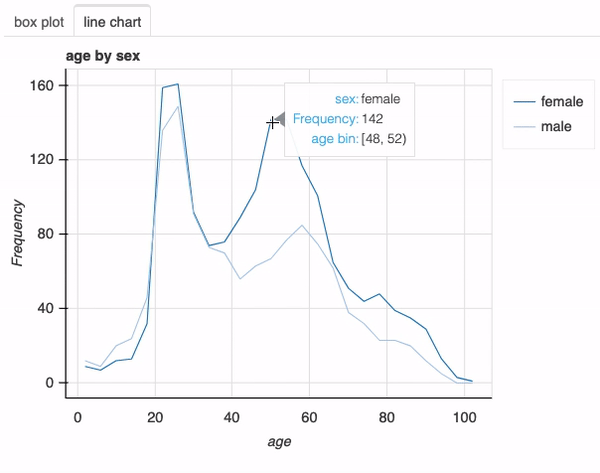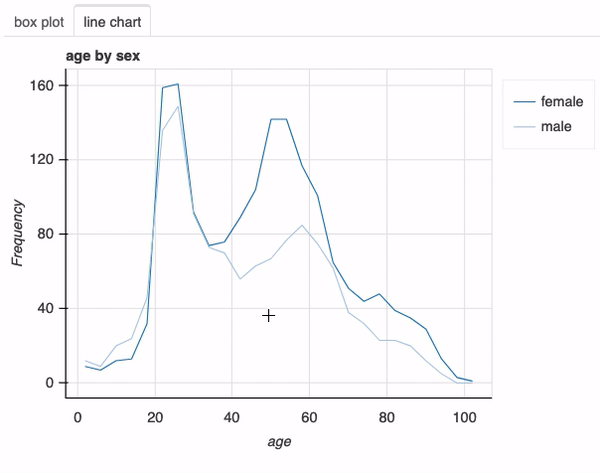
接下来,让我们调查感染新冠肺炎的男性和女性的年龄分布。为此,我们只需在前面的函数调用中添加列sex:
plot(df, "age", "sex", bins=26)
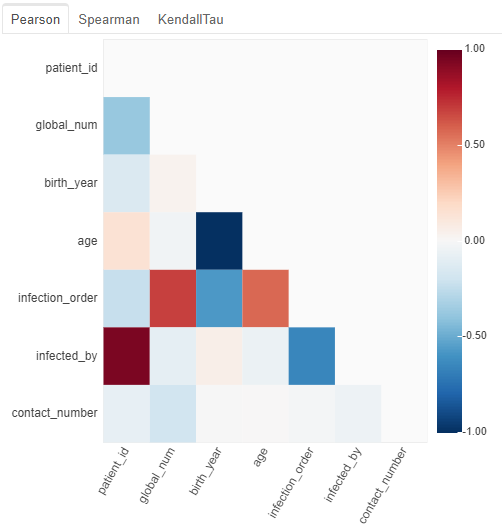
from dataprep.eda import plot_correlation, plot_missing plot_correlation(df)
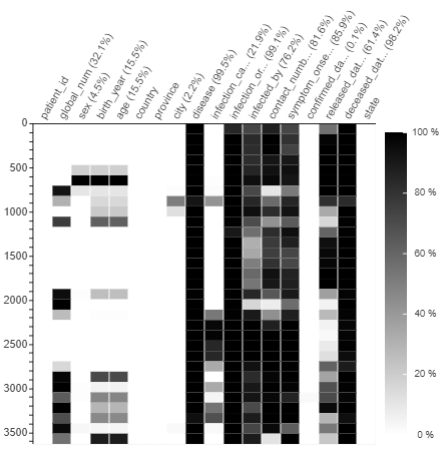
plot_missing(df)
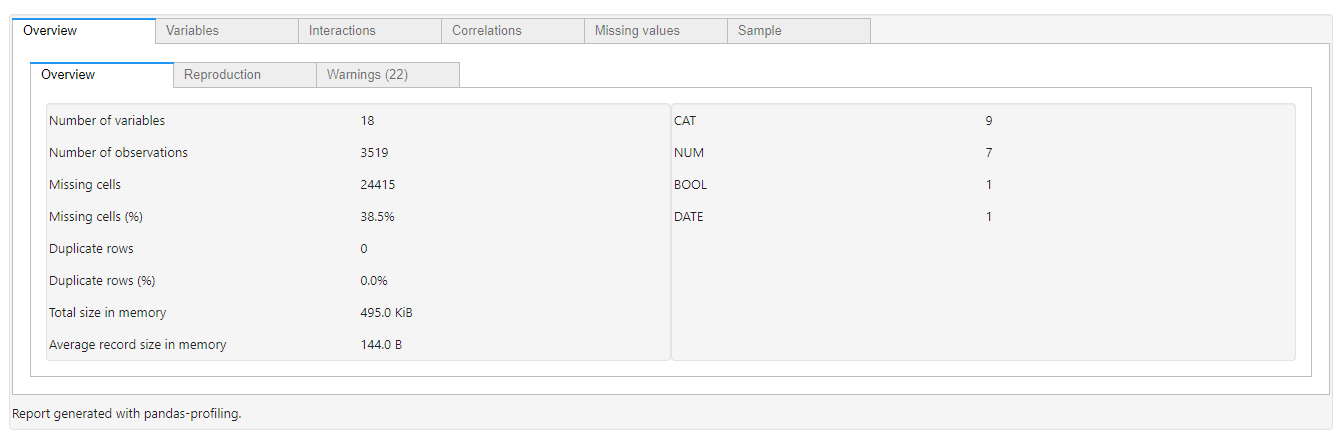
而相对的使用pandas-profiling无法达到相同的效果
from pandas_profiling import ProfileReport ProfileReport(df).to_widgets()
另外就是交互式的功能,Dataprep.eda底层使用了Bokeh,所以可以看到很多细节的提示信息,pandas-profiling并不支持。
2.Dataprep.eda比pandas-profiling快100倍
Dataprep.eda比pandas-profiling更快的主要原因:
- 使用并行计算的Dask来替代Pandas处理数据
- eda每次只创建于任务相关的可视化,减少了不必要的计算,而pandas-profiling是整个数据集的概要文件。
3.智能可视化
dataprep.eda包含的一些智能特性:
- 为每个EDA任务选择正确的图形来可视化数据
- 列类型推断(数字型、类别型和日期时间型)
- 选择合适的时间单位(用户也可以指定)
- 对数量庞大的类型数据输出清晰的可视化方案(用户也可以指定)
4.处理大数据
使用Dask的Dataprep.eda可以处理比内存数据集更大的数据集。支持核外处理和并行处理,因此可以有效地评估非常大数据集上的计算。
参考链接:


