文章内容如有错误或排版问题,请提交反馈,非常感谢!
当一些转化率指标发生波动时,往往需要分析原因,以转化率为例,影响转化率变化的可能因素有:
- 流量结构发生了变化,部分高转化的渠道或低转化的渠道的流量发生了较大的变化
- 部分渠道的转化发生了变化
- 新老客的结构发生了变化,如新客突然变多。
- 页面流程变更导致的问题
- 产品品类流量发生了变化
- 产品品类转化发生了变化
- …

由于涉及到维度非常的多,人工统计非常的繁琐,特整理了如下Python代码来实现自动化。
方案一:按占比分解转化率
将波动影响可以分为2种类型:
- 细分粒度下的流量结构变化
- 细分粒度下的流量转化变化
我们用以下模拟数据进行讲解:

相关计算说明:
- 支付率=支付单量/创建单量
- 创单单量占比=细分维度下的创单单量/整体创建单量
- 支付率分解=创建单量占比*支付率=细分维度下的支付单量/整体创建单量
- 整体影响=当期支付率分解–上期支付率分解
- 结构影响=当期支付率*(当期创建单量占比-历史创建单量占比)
- 转化影响=历史创建单量占比*(当期支付率–历史支付率)
Python代码实现:
def conversion_attribution_v2(df, prev_ds, curr_ds, col_dims, col_ds, col_cnt, col_trgt, dim_count=1):
df_prev = df[df[col_ds] == prev_ds].copy()
df_curr = df[df[col_ds] == curr_ds].copy()
total_cnt_x = df_prev[col_cnt].sum()
total_trgt_x = df_prev[col_trgt].sum()
total_cr_x = total_trgt_x / total_cnt_x if total_cnt_x > 0 else 0
total_cnt_y = df_curr[col_cnt].sum()
total_trgt_y = df_curr[col_trgt].sum()
total_cr_y = total_trgt_y / total_cnt_y if total_cnt_y > 0 else 0
result_list = []
max_dim = dim_count if (0 < dim_count <= len(col_dims)) else len(col_dims)
for i in range(1, max_dim + 1):
for dim_comb in combinations(col_dims, i):
dim_comb = list(dim_comb)
df_x = df_prev.groupby(dim_comb).agg(cnt_x=(col_cnt, 'sum'), trgt_x=(col_trgt, 'sum')).reset_index()
df_y = df_curr.groupby(dim_comb).agg(cnt_y=(col_cnt, 'sum'), trgt_y=(col_trgt, 'sum')).reset_index()
df_comb = pd.merge(df_x, df_y, on=dim_comb, how='outer').fillna(0)
df_comb['dims'] = df_comb[dim_comb].apply(
lambda row: '|'.join([f"{col}={val}" for col, val in zip(dim_comb, row)]), axis=1)
df_comb['p_x'] = df_comb['cnt_x'] / total_cnt_x if total_cnt_x > 0 else 0
df_comb['p_y'] = df_comb['cnt_y'] / total_cnt_y if total_cnt_y > 0 else 0
df_comb['r_x'] = np.where(df_comb['cnt_x'] > 0, df_comb['trgt_x'] / df_comb['cnt_x'], 0)
df_comb['r_y'] = np.where(df_comb['cnt_y'] > 0, df_comb['trgt_y'] / df_comb['cnt_y'], 0)
df_comb['cnt_contrib'] = (df_comb['p_y'] - df_comb['p_x']) * df_comb['r_x']
df_comb['cr_contrib'] = (df_comb['r_y'] - df_comb['r_x']) * df_comb['p_x']
df_comb['total_contrib'] = df_comb['cnt_contrib'] + df_comb['cr_contrib']
result_cols = [
'dims', 'cnt_x', 'trgt_x', 'cnt_y', 'trgt_y',
'r_x', 'r_y', 'p_x', 'p_y',
'cnt_contrib', 'cr_contrib', 'total_contrib'
]
result_list.append(df_comb[result_cols])
final_result = pd.concat(result_list, ignore_index=True)
final_result['abs_contrib'] = final_result['total_contrib'].abs()
final_result = final_result.sort_values(by='abs_contrib', ascending=False).reset_index(drop=True)
if total_cr_y > total_cr_x:
delta_type = '上升'
delta = total_cr_y - total_cr_x
symbol = '↑'
elif total_cr_y < total_cr_x:
delta_type = '下降'
delta = total_cr_x - total_cr_y
symbol = '↓'
else:
delta_type = '无变化'
delta = 0
symbol = '='
summary_str = f"# 转化率变化归因分析\n"
summary_str += f"## {curr_ds}:{total_cr_y:.2%} {symbol} {prev_ds}:{total_cr_x:.2%}({delta_type} {delta:.2%})\n"
summary_str += "\nTop 维度组合贡献排序:\n"
for idx, row in final_result.head(10).iterrows():
summary_str += f"【{idx + 1}】 {row['dims']}\t影响: {round(row['total_contrib'] * 100, 2)} pp"
summary_str += f"\t结构变化: {round(row['cnt_contrib'] * 100, 2)} pp ({round(row['p_x'] * 100, 2)}% → {round(row['p_y'] * 100, 2)}%)"
summary_str += f"\t转化变化: {round(row['cr_contrib'] * 100, 2)} pp ({round(row['r_x'] * 100, 2)}% → {round(row['r_y'] * 100, 2)}%)\n"
return summary_str
以上方案存在的问题是如果某一个转化率较低的渠道流量上升,计算出来对整体的转化率是增加的,与常规的认知不太一致。
方案二:固定历史其他维度,计算转化率差
还是以上面的的数据为例:
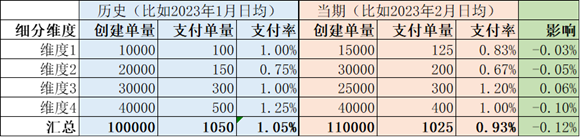
主要逻辑:固定历史其他维度的创建单量和支付单量,将历史中细分维度下的创单单量和支付单量更新为当期数据后计算整体创完率前后差
- 影响=(历史整体支付单量–历史细分维度下支付单量+当期细分维度下支付单量)/(历史整体创单单量-历史细分维度下创建单量+当期细分维度下创单单量)-历史支付率
这个方案存在一些疑问,应该固定当期的其他维度还是固定历史的其他维度。中间计算出来的值有些不一样。
- 固定历史其他维度:不考虑其他维度的近期变化
- 固定当期其他维度:计算该维度在当前场景下的影响
Python代码实现:(固定历史其他维度)
```import pandas as pd
def compare_metrics(base_df, history_df, col_dim=None, col_cnt='', col_trgt=''):
if col_dim is None:
col_dim = []
# 计算基期和对照期的汇总数据
df_x = history_df.groupby(col_dim)[[col_cnt, col_trgt]].sum().rename(
columns={col_cnt: 'cnt_x', col_trgt: 'trgt_x'}).reset_index()
df_y = base_df.groupby(col_dim)[[col_cnt, col_trgt]].sum().rename(
columns={col_cnt: 'cnt_y', col_trgt: 'trgt_y'}).reset_index()
# 创建维度标识
df_x['dims'] = df_x[col_dim].astype(str).agg('_'.join, axis=1)
df_y['dims'] = df_y[col_dim].astype(str).agg('_'.join, axis=1)
# 合并数据
df_combine = pd.merge(df_x, df_y, on='dims', how='left')
# 计算整体计数和目标列值
total_cnt_x = df_combine['cnt_x'].sum()
total_trgt_x = df_combine['trgt_x'].sum()
# 计算对照期的整体计数和目标列值
total_cnt_y = df_combine['cnt_y'].sum()
total_trgt_y = df_combine['trgt_y'].sum()
# 计算整体转化率
overall_rate_x = total_trgt_x / total_cnt_x if total_cnt_x != 0 else 0
overall_rate_y = total_trgt_y / total_cnt_y if total_cnt_y != 0 else 0
# 计算影响度
df_combine['impact'] = (total_trgt_y - df_combine['trgt_x'] + df_combine['trgt_y']) / (
total_cnt_y - df_combine['cnt_x'] + df_combine['cnt_y']) - overall_rate_x
return df_combine[['dims', 'cnt_x', 'trgt_x', 'cnt_y', 'trgt_y', 'impact']]
在此基础上更加贡献度分解:
import pandas as pd
def compare_metrics(base_df, history_df, col_dim=None, col_cnt='', col_trgt=''):
if col_dim is None:
col_dim = []
df_x, df_y = history_df, base_df
# 计算基期和对照期的汇总数据
df_g_x = df_x.groupby(col_dim)[[col_cnt, col_trgt]].sum().rename(
columns={col_cnt: 'cnt_x', col_trgt: 'trgt_x'}).reset_index()
df_g_y = df_y.groupby(col_dim)[[col_cnt, col_trgt]].sum().rename(
columns={col_cnt: 'cnt_y', col_trgt: 'trgt_y'}).reset_index()
# 构建维度字符串
df_g_x['dims'] = df_g_x.apply(lambda row: '_'.join([str(row[c]) for c in col_dim]), axis=1)
df_g_y['dims'] = df_g_y.apply(lambda row: '_'.join([str(row[c]) for c in col_dim]), axis=1)
# 合并数据
df_g_combine = pd.merge(df_g_x, df_g_y, on='dims', how='left')
# 计算整体指标
cnt_x = df_g_combine['cnt_x'].sum()
trgt_x = df_g_combine['trgt_x'].sum()
cnt_y = df_g_combine['cnt_y'].sum()
trgt_y = df_g_combine['trgt_y'].sum()
overall_rate_x = trgt_x / cnt_x
overall_rate_y = trgt_y / cnt_y
# 计算每个维度的贡献度
df_g_combine['impact'] = (trgt_y - df_g_combine['trgt_x'] + df_g_combine['trgt_y']) / (
cnt_y - df_g_combine['cnt_x'] + df_g_combine['cnt_y']) - overall_rate_x
# 计算贡献度分解
df_g_combine['cnt_factor'] = df_g_combine['cnt_y'] / cnt_y - df_g_combine['cnt_x'] / cnt_x
df_g_combine['cr_factor'] = df_g_combine['trgt_y'] / df_g_combine['cnt_y'] - df_g_combine['trgt_x'] / df_g_combine['cnt_x']
df_g_combine['cnt_contrib'] = df_g_combine['cnt_factor'] * overall_rate_x
df_g_combine['cr_contrib'] = df_g_combine['cr_factor'] * (overall_rate_y - overall_rate_x)
df_g_combine['total_contrib'] = df_g_combine['cnt_contrib'] + df_g_combine['cr_contrib']
return df_g_combine[['dims', 'cnt_x', 'trgt_x', 'cnt_y', 'trgt_y', 'impact', 'cnt_factor', 'cr_factor', 'cnt_contrib', 'cr_contrib', 'total_contrib']]
参考链接:


