在使用Python处理数据的时候,经常会需要处理Excel中的数据。现在基本上都使用Pandas读取Excel中的数据,但是除了Pandas以外,还有一些Python包可以满足对Excel数据的读取。

在开始之前,先学习下Excel中涉及到的概念:
- workbook: 在各种库中,workbook其实就是一个excel文件,可以把它看作数据库。
- sheet: 在一个excel文件中,可能会有多个sheet,一个sheet可以看作数据库中的一张表
- row: row其实就是一张表中的一行,正常是用数字1、2、3、4表示
- column: column就是一张表中的一列,正常用字母A、B、C、D表示
- cell: cell就是一张表中的一格,可以用row+column的组合来表示,例如:A3
Excel中常用的文件格式区别:
- XLS:Excel2003版本之前使用的文件格式,二进制的文件保存方式。xls文件支持的最大行数是65536行。xlsx支持的最大行数是1048576行。xls支持的的最大列数是256列,xlsx是16384列,这个是行数和列数的限制不是来自Excel的版本而是文件类型的版本。
- XLSX:XLSX其实一个ZIP文件,也就是如果你把文件名的XLSX改成zip,然后是可以用解压缩软件直接打开这个zip文件的,你打开它看到话,会可以看到里面有很多的xml文件。
Python Excel读写包之xlrd、xlwt
xlrd、xlwt、xlutils是Simplistix公司开发,原网站内容基本都清空了,项目迁移到http://www.python-excel.org,并在GitHub开源,见https://github.com/python-excel。在网站上目前也非常的不建议使用的以上工具,官方目前也不推荐继续使用,主要原因:
- xlrd模块:可读取.xls、.xlsx表格
- xlwt模块:可写入.xls表格(不可写入.xlsx文件!!!)
- xlutils不是必需,但额外提供了一些简化操作的工具函数。
xlrd
读文件功能由xlrd包提供。xlrd包实现了xlrd.book.Book(以下简称Book)、xlrd.sheet.Sheet(以下简称Sheet)和xlrd.sheet.Cell(以下简称Cell)类型,与Excel中的工作簿、表单、单元格概念相对应,单元格是最小操作粒度。
xlrd加载表格文件就1个函数open_workbook,常用参数就2个:
- filename,指定要打开的Excel文件路径
- on_demand,如果是True则按需加载工作簿中的表单,如果是False则直接加载所有表单,默认为False,为节省资源一般设为True,这在大文件时表现更明显。
读入Excel文件拿到Workbook后,下一步就是定位到Sheet。Book类对象有几个重要的属性和方法,用于索引Sheet。
- nsheets属性,指示包含的Sheet对象个数
- sheet_names方法,返回所有表单名称
- sheet_by_index、sheet_by_name方法,分别使用序号、名称索引表单
- sheets方法,返回一个包含所有Sheet对象的列表
wb = xlrd.open_workbook('读取表.xls')
print(type(wb))
print(wb.nsheets)
print(wb.sheet_names())
print(wb.sheet_by_index(0))
print(wb.sheet_by_name('第一个sheet'))
for sh in wb.sheets():
print(sh.name, sh)
拿到Sheet对象后,下一步就是要索引行/列/单元格,获取到行/列/单元格的数据。Sheet类对象有几个重要的属性和方法,用于支持后续操作。
- name属性,即表单名称;
- nrows、ncols属性,指示读入表单的最大行数、列数,由于单元格仅支持行列序号索引,因此这两个属性是检查越界的必备内容;
- cell方法,接受2个参数,即行、列序号,返回Cell对象,注意xlrd仅支持通过行列序号索引单元格,行列序号从0起始;
- cell_value方法,与cell方法类似,只不过返回的是单元格中的值,不是Cell对象;
- cell_type方法,返回单元格的类型
- row、col方法,返回某1整行(列)的Cell对象组成的列表;
- row_types、col_types,返回指定行(列)内若干列(行)的单元格的类型;
- row_values、col_values,返回指定行(列)内若干列(行)的单元格的值;
- row_slice、col_slice,返回指定行(列)内若干列(行)的单元格,是types和values的综合。
wb = xlrd.open_workbook('读取表.xls')
sh = wb.sheet_by_index(0)
print(sh.nrows, sh.ncols)
print(sh.cell(1, 2))
print(sh.cell_value(1, 2))
print(sh.row_values(1))
print(sh.col_values(1))
print(sh.cell_type(1, 2))
print(sh.col_types(2, 1)) # 第2列,第1行起始
print(sh.row_slice(1, 0, 2)) # 第1行,第0列起始)
注意xlrd读取excel工作簿的行、列索引都是从0开始。
- row = ws.row_values(i, ca, cb) # 读取第i行中[ca, cb)列内容,返回list。注意不含第cb列
- col = ws.col_values(i, ra, rb) # 读取第i列中[ra, rb)行内容,返回list。注意不含第rb行
- cell = ws.cell_value(r, c) # 读取第i行第j列单元格内容
对于数据类型的预定义常量
| 预定义常量 | 数值 | 字符串 |
| XL_CELL_EMPTY | 0 | empty |
| XL_CELL_TEXT | 1 | text |
| XL_CELL_NUMBER | 2 | number | XL_CELL_DATE | 3 | xldate |
| XL_CELL_BOOLEAN | 4 | boolean |
| XL_CELL_ERROR | 5 | error |
| XL_CELL_BLANK | 6 | blank |
其中date数据类型读取时为浮点数,需要手动转换为时间格式,如一个单元格日期为2020-2-5,xlrd模块读取到值为:43866.0,把浮点数转换为正确的时间格式有两个方法:
- xldate_as_tuple(xdate, datemode):返回一个(year, month, day, hours, minutes, seconds)组成的元祖,datemode参数有2个值,0表示以1900年为基础时间戳(常见),1表示以1904年为基础时间戳。1900-3-1之前的日期无法转为tuple。
- xldate_as_datetime(xdate, datemode)(需要先引入datetime模块),直接返回一个datetime对象,xlrd.xldate_as_datetime(xdate, datemode).strftime(‘%Y-%m-%d %H:%M:%S’)
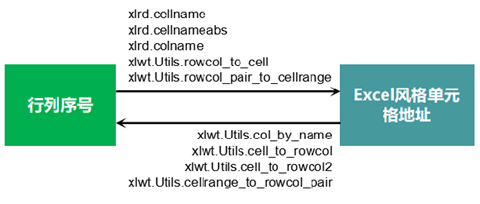
为便于索引,xlrd包的cellname、cellnameabs、colname函数,将行列序号转换为Excel风格的单元格地址;xlwt.Utils模块的rowcol_to_cell、rowcol_pair_to_cellrange函数,也可以将行列序号转换为Excel风格的单元格地址;而col_by_name、cell_to_rowcol、cell_to_rowcol2、cellrange_to_rowcol_pair函数,则将Excel风格的单元格地址转换为行列序号。
print(xlrd.cellname(2, 10))
print(xlrd.cellnameabs(2, 10))#结果为绝对引用地址
print(xlwt.Utils.col_by_name('K'))#注意列名称必须大写
print(xlwt.Utils.cell_to_rowcol('K3'))#行列均无绝对引用
print(xlwt.Utils.cell_to_rowcol('K$3'))#行绝对引用
print(xlwt.Utils.cell_to_rowcol2('K$3'))#与上一个函数的区别是忽略绝对引用符号
行列序号与单元格地址转换总结如下图:
要遍历1个sheet内所有单元格,通常按行、列顺序逐个得到单元格,再读出单元格值存起来,以便后续处理。也可以直接得到一整行(列),整行(列)地处理数据。
wb = xlrd.open_workbook('读取表.xls')
sh = wb.sheet_by_index(0)
#1、逐单元格处理
for rx in range(sh.nrows):
for cx in range(sh.ncols):
c = sh.cell(rx, cx)
#对单元格的进一步处理
print(c.ctype, c.value)
#2、整行处理
for rx in range(sh.nrows):
row = sh.row(rx)
#对行的进一步处理
print(len(row))
#3、整列处理
for cx in range(sh.ncols):
col = sh.col(cx)
#对列的进一步处理
print(len(col))
xlwt
xlrd包只能将表单内的数据读出来,对改写数据无能为力,改写数据和保存至文件,由xlwt包完成。xlwt实现了一套xlwt.Workbook.Workbook(以下简称Workbook)、xlwt.Worksheet.Worksheet(以下简称Worksheet)类型,但很不幸与xlrd包的不存在继承关系,这导致用xlrd包读出来的Book、Sheet对象并不能直接用于创建Workbook和Worksheet对象,只能把数据暂存着以备后续再写回去,使得过程十分繁琐。
xlwt包对外暴露的类型、方法、函数及参数也十分简洁,紧密契合改写数据、保存至文件的流程:
- 调用Workbook模块的Workbook函数,创建Workbook对象,第1个参数是encoding
- 调用Workbook对象的add_sheet方法,往Workbook中添加Worksheet对象,第1个参数sheetname指定表单名称,第2个参数cell_overwrite_ok确定是否允许单元格覆写,建议设置为True,避免对程序可能对单元格多次写数据而抛出错误;
- 调用Worksheet对象的write方法,往Worksheet的行/列/单元格内写入数据,此处用到的数据多数情况来自xlrd包从Excel文件读出来的结果,前2个参数为行列序号,第3个参数是要写入的值,第4个参数是单元格风格,如无特殊需求默认即可;
- 调用Workbook对象的save方法,将Workbook对象保存至文件,参数为文件名称或文件流对象。
其他的属性、方法、函数一般用的较少。
xlwt主要涉及到3个类:Workbook对应工作簿文件,Worksheet对应工作表,XFStyle对象用于控制单元格格式(XFrecord)。
#创建Workbook对象 workbook = xlwt.Workbook.Workbook(encoding='ascii', style_compression=0) #style_compression表示是否对格式进行压缩默认为0不压缩=1表示压缩字体信息=2表示压缩字体和XFrecord #对于名为workbook的Workbook对象可以有以下操作 #添加工作表并返回添加的工作表 workbook.add_sheet(sheet_name, cell_overwrite_ok=False) #获取指定名称的工作表 workbook.get_sheet(Sheet_name) #保存xls文件 workbook.save(file_name) #对于名为worksheet的Worksheet对象有以下操作 #写入内容指定单元格的内容与格式 worksheet.write(rowx, colx, cell_value, style) worksheet.row(rowx).write(colx, cell_value, style) worksheet.col(colx).write(rows, cell_value, style) #将完成编辑的行flush,flush之后的行不可再编辑 worksheet.flush_row_data()
实例:
rwb = xlrd.open_workbook('读取表.xls')
rsh = rwb.sheet_by_index(0)
wbk = xlwt.Workbook()
wsh = wbk.add_sheet("Sheet1", cell_overwrite_ok=True)
for rx in range(rsh.nrows):
for cx in range(rsh.ncols):
wsh.write(rx, cx, rsh.cell_value(rx, cx))
wsh.write(0, 0, '新数据A1')
wsh.write(0, 1, 3.14159)
wsh.write(0, 6, False)
wsh.write(4 + 1, 0 + 1, False)
wsh.write(3 + 1, xlwt.Utils.col_by_name('D'), '列D')
wbk.save('data2.xls')
wbk.save('data-second.xlsx') #可以多次保存,本质还是xls格式,与后缀无关。需要改成xls后才能使用Excel正常打开
对于保存,有两点需要提醒:
- Python所有涉及Excel操作的库都不支持”原地编辑与保存”,xlwt也不例外,”保存”实际上是”另存为”,只是指定保存到原文件的话,原文件被覆盖。
- xlwt支持写入到xls格式文件,不支持xlsx格式,即使指定扩展名.xlsx,文件格式本身仍是xls格式。
注意从data.xls中读出来的日期,本质是数值,复制后写入还是数值,需要在Excel中将单元格设定为日期格式,才能显示为日期形式。
xlwt还支持写入公式,但较为有限:
wsh.write(2, 4, xlwt.Formula('sum(A3:D3)'))
另外,xlwr还支持跨行或者跨列的合并单元格内容的写入(rowx和colx从0开始):
write_merge(start_rowx, end_rowx, start_colx, end_colx, content='', sytle)
设置excel单元格风格
设定单元格数据格式:
mf = xlwt.XFStyle() #返回用于设定单元格格式的实例 mf.num_format_str = 'yyyy/mm/dd' #将数字转换为日期格式 mf.font = '宋体' #设置字体
需在ws.write()时指定style实例才能生效。
示例:
##初始化样式 style = xlwt.XFStyle() #样式类实例 ##创建字体 font = xlwt.Font() #字体类实例 font.name = 'Times New Roman' #字体名称 font.bold = True #加粗 font.italic = True #倾斜 font.height = 300 #字号200为10points font.colour_index = 3 #颜色编码 ##创建边框 borders = xlwt.Borders() #边框类实例 borders.left = 6 borders.right = 6 borders.top = 6 borders.bottom = 6 ##创建对齐 alignment = xlwt.Alignment() #对齐类实例 #alignment.horz = xlwt.Alignment.HORZ_LEFT #水平左对齐 #alignment.horz = xlwt.Alignment.HORZ_RIGHT #水平右对齐 alignment.horz = xlwt.Alignment.HORZ_CENTER #水平居中 #alignment.vert = xlwt.Alignment.VERT_TOP #垂直靠上 #alignment.vert = xlwt.Alignment.VERT_BOTTOM #垂直靠下 alignment.vert = xlwt.Alignment.VERT_CENTER #垂直居中 alignment.wrap = 1 #自动换行 ##创建模式 pattern = xlwt.Pattern() #模式类实例 pattern.pattern = xlwt.Pattern.SOLID_PATTERN #固定的样式 pattern.pattern_fore_colour = xlwt.Style.colour_map['yellow'] #背景颜色 ##应用样式 style.font = font style.borders = borders style.num_format_str = '#,##0.0000' #内容格式 style.alignment = alignment style.pattern = pattern ##合并单元格(A,B,C,D)表示合并左上角[A,C]和右下角[B,D]单元格坐标(均在合并单元格内部) wsh.write_merge(3, 5, 3, 5, 'Merge', style) #'Merge'为写入内容,应用style样式 wsh.write(0, 0, 1234567.890123, style) #向[0,0]坐标单元格写入数据,应用style样式 style.num_format_str = '#,##0.000%' #内容格式 wsh.write(6, 0, 67.8123456, style) #整数部分用逗号分隔,小数部分保留3位小数并以百分数表示 style.num_format_str = '###%' #内容格式 wsh.write(6, 5, 0.128, style) style.num_format_str = '###.##%' #内容格式 wsh.write(6, 4, 0.128, style) style.num_format_str = '000.00%' #内容格式 wsh.write(6, 3, 0.128, style)
或是:
def set_style(font_name, font_color, font_height, font_bold=False):
style = xlwt.XFStyle()
font = xlwt.Font()
font.name = font_name
font.colour_index = font_color
font.bold = font_bold
font.height = 20 * font_height
style.font = font
return style
ws.write(r, c, label=sheet.cell_value(r, c), style=set_style('黑体', 3, 30, True))
XFStyle用于指定单元格内容格式,使用easyxf函数来得到一个XFStyle对象。
xlwt.Style.easyxf(strg_to_parse='', num_format_str=None, field_sep=',', line_sep=';', intro_sep=':', esc_char='\\', debug=False)
strg_to_parse是定义了格式的字符串,可以控制的格式属性包括字体(font)、对齐方式(align)、边框形式(border)、颜色样式(pattern)和单元格保护(protection)等,具体的格式属性在文章末尾详细列出。
字符串strg_to_parse语法格式如下:
(<element>:(<attribute><value>,)+;)+
例如:
'font:bold on;align:wrap on,vert centre,horiz center' #字体加粗对齐方式允许换行垂直居中水平居中
参数字符串num_format_str用于指定数字的格式,例如:
"#,##0.00" "dd/mm/yyyy"
以下是xlwt.Style.easyxf的一些用例:
style1 = easyxf('font:name Times New Roman')
style2 = easyxf('font:underline single')
style3 = easyxf('border:left thick,top thick')
style4 = easyxf('pattern:pattern solid,fore_colour red;')
style5 = xlwt.easyxf(num_format_str='yyyy-mm-dd hh:mm:ss')
style6 = xlwt.easyxf('font:name Times New Roman,color-index red,bold on',num_format_str='#,##0.00')
xlutils
xlutils依赖xlrd和 xlwt,主要包含以下模块:
- copy:可将xlrd.Book对象复制到xlwt.Workbook对象
- display:更好友好更安全地显示xlrd相关对象的信息
- filter:用于分割和过滤现有Excel文件到新Excel文件的小型框架
- margins:获取Excel文件中包含有多少有用信息
- save:将xlrd.Book对象序列化为Excel文件的工具
- styles:用于处于Excel文件中格式信息的工具
- view:使用workbook中工作表的视图信息
这里主要介绍两个函数的使用,第一个xlutils.copy.copy(wb)。从上述步骤看,如果仅是生成全新的Excel文件,使用xlwt包即可。如果是“编辑”Excel文件中的某些数据,则必须使用xlrd加载原文件并将原表格复制一份,再使用xlwt去处理需要编辑的单元格,流程繁琐。xlutils包的copy正是为简化此流程而生,可以将xlrd的Book对象复制转换为xlwt的Workbook对象。
import xlutils.copy #导入模块
rbk = xlrd.open_workbook('读取表.xls')
wbk = xlutils.copy.copy(rbk)
sh = wbk.get_sheet(0) #索引到Sheet1
sh.write(0,6,'COPIED')
wbk.add_sheet('表单2') #新增表单
wbk.save('data-copy.xls')
另一个是xlutils.filter中的函数xlutils.filter.process(reader,*chain):
模块xlutils.filter中包含有一些内置的模块reader、writer和filter,以及用于将它们串联起来的函数process() ,主要功能是过滤和分割Excel文件。
- reader用于从数据源中获取数据,并将其转化为一系列Book对象,然后会调用第一个filter相关的方法。模块内提供有一些基础的reader类。
- filter用户获取特定任务需要的结果,在filter中必须要定义一些特定的方法,这些方法的实现中可以根据需要填写任意功能,但通常会以调用下一个filter的对应方法作为结束。
- writer会处理参数链中最后一个filter中特定的方法。writer通常用于从数据源复制信息并将其写入输出文件。由于在writer中涉及到很多工作而通常只有向目标位置写入二进制数据会略有不同,模块内也提供了一些基础的writer类。
- process(reader,*chain)可以将内置或自定义的reader、writer和filter串联起来执行。
XFStyle格式
格式属性
- font
- bold:布尔值,默认为False
- charset:可选值见下节,默认值是sys_default
- colour(或color_index、colour_index、color):可选值见下节,默认值是automatic
- escapement:可选值为none、superscript或subscript,默认值none
- family:包含字体的fontfamily的字符串,默认值None
- height:使用20乘以pointsize得到的高度值,默认是200,对应10pt
- italic:布尔值,默认为False
- name:包含字体名称的字符串,默认为Arial
- outline:布尔值,默认为False
- shadow:布尔值,默认为False
- struck_out:布尔值,默认为False
- underline:布尔值或者none、single、single_acc、double、double_acc其中之一。默认值是none
- alignment(或align)
- direction(或dire):general、lr、rl之一,默认值general
- horizontal(或horiz、horz):One of the following:general、left、center|centre、right、filled、justified、center|centre_across_selection、distributed其中之一,默认值是general
- indent(或inde):缩进值0到15,默认值0
- rotation(或rota):-90到+90之间的整数值或stacked、none之一,默认值是none
- shrink_to_fit(或shri、shrink):布尔值,默认为False
- vertical(或vert):top、center|centre、bottom、justified、distributed其中之一,默认为bottom
- wrap:布尔值,默认为False
- borders(或border)
- left:边框样式,详见下节
- right:边框样式,详见下节
- top:边框样式,详见下节
- bottom:边框样式,详见下节
- diag:边框样式,详见下节
- left_colour(或left_color):颜色值,详见下节,默认为automatic
- right_colour(或right_color):颜色值,详见下节,默认为automatic
- top_colour(或top_color):颜色值,详见下节,默认为automatic
- bottom_colour(或bottom_color):颜色值,详见下节,默认为automatic
- diag_colour(或diag_color):颜色值,详见下节,默认为automatic
- need_diag_1:布尔值,默认为False
- need_diag_2:布尔值,默认为False
- pattern
- back_colour(或back_color、pattern_back_colour、pattern_back_color):颜色值,详见下节,默认为automatic
- fore_colour(或fore_color、pattern_fore_colour、pattern_fore_color):颜色值,详见下节,默认为automatic
- pattern:no_fill、none、solid、solid_fill、solid_pattern、fine_dots、alt_bars、sparse_dots、thick_horz_bands、thick_vert_bands、thick_backward_diag、thick_forward_diag、big_spots、bricks、thin_horz_bands、thin_vert_bands、thin_backward_diag、thin_forward_diag、squares、diamonds其中之一,默认为none
- protection
- cell_locked:布尔值,默认为 True
- formula_hidden:布尔值,默认为 False
取值说明
布尔型
- True 可以表示为 1、yes、 true 或 on;
- False 可以表示为 0、no、 false 或 off。
charset
字符集的可选值如下:
ansi_latin, sys_default, symbol, apple_roman, ansi_jap_shift_jis, ansi_kor_hangul, ansi_kor_johab, ansi_chinese_gbk, ansi_chinese_big5, ansi_greek, ansi_turkish, ansi_vietnamese, ansi_hebrew, ansi_arabic, ansi_baltic, ansi_cyrillic, ansi_thai, ansi_latin_ii, oem_latin_i
color
颜色可选值如下:
| aqua | dark_red_ega | light_blue | plum |
| black | dark_teal | light_green | purple_ega |
| blue | dark_yellow | light_orange | red |
| blue_gray | gold | light_turquoise | rose |
| bright_green | gray_ega | light_yellow | sea_green |
| brown | gray25 | lime | silver_ega |
| coral | gray40 | magenta_ega | sky_blue |
| cyan_ega | gray50 | ocean_blue | tan |
| dark_blue | gray80 | olive_ega | teal |
| dark_blue_ega | green | olive_green | teal_ega |
| dark_green | ice_blue | orange | turquoise |
| dark_green_ega | indigo | pale_blue | violet |
| dark_purple | ivory | periwinkle | white |
| dark_red | lavender | pink | yellow |
borderline
可以是 0 到 13 的整数值,或者以下值其中之一:
no_line, thin, medium, dashed, dotted, thick, double, hair, medium_dashed, thin_dash_dotted, medium_dash_dotted, thin_dash_dot_dotted, medium_dash_dot_dotted, slanted_medium_dash_dotted
参考链接:
- https://github.com/python-excel
- http://xlrd.readthedocs.io/en/latest/
- http://xlwt.readthedocs.io/en/latest/api.html
- http://xlutils.readthedocs.io/en/latest/
Python Excel 写入工具之 xlsxwriter
XlsxWriter 是一个 Python 模块,用于以 Excel 2007+ XLSX 文件格式编写文件。
xlsxwriter 可用于将文本、数字、公式和超链接写入多个工作表,支持格式化等功能,包括:
- 100% 兼容的 Excel XLSX 文件。
- 完全格式化。
- 合并单元格。
- 定义的名称。
- 图表。
- 自动筛选。
- 数据验证和下拉列表。
- 条件格式。
- 工作表 png/jpeg/bmp/wmf/emf 图像。
- 丰富的多格式字符串。
- 单元格注释。
- 与 Pandas 融合。
- 文本框。
- 支持添加宏。
- 用于写入大文件的内存优化模式。
优点:
- 功能比较强:相对而言,这是除 Excel 自身之外功能最强的工具了。字体设置、前景色背景色、border 设置、视图缩放(zoom)、单元格合并、autofilter、freezepanes、公式、data validation、单元格注释、行高和列宽设置等等。
- 支持大文件写入:如果数据量非常大,可以启用 constant memory 模式,这是一种顺序写入模式,得到一行数据就立刻写入一行,而不会把所有的数据都保持在内存中。
缺点:
- 不支持读取和修改:作者并没有打算做一个 XlsxReader 来提供读取操作。不能读取,也就无从修改了。它只能用来创建新的文件。当你在某个单元格写入数据后,除非你自己保存了相关的内容,否则还是没有办法读出已经写入的信息。
- 不支持 XLS 文件:XLS 是 Office 2013 或更早版本所使用的格式,是一种二进制格式的文件。XLSX 则是用一系列 XML 文件组成的(最后的 X 代表了 XML)一个压缩包。如果非要创建低版本的 XLS 文件,请移步 xlwt。
- 暂时不支持透视表(PivotTable)
xlsxwriter简单使用
# -*- coding: utf-8 -*-
import xlsxwriter
data = [
['年度', '数量', '剩余数量'],
['2016', '100', '30'],
['2017', '150', '50'],
['2018', '170', '40'],
['2019', '190', '15'],
['2020', '200', '100'],
]
wb = xlsxwriter.Workbook('test.xlsx') # 创建一个新的 excel 表格
sheet = wb.add_worksheet('sheet1') # 创建一个新的 sheet
# 将 data 数组的数据插入到 excel 表格中
for row, item in enumerate(data):
for column, value in enumerate(item):
sheet.write(row, column, value)
wb.close()
我们还可以给 excel 表格设置样式,给表格设置样式使用到了 add_format 方法:
# -*- coding: utf-8 -*-
import xlsxwriter
data = [
['年度', '数量', '剩余数量'],
['2016', '100', '30'],
['2017', '150', '50'],
['2018', '170', '40'],
['2019', '190', '15'],
['2020', '200', '100'],
]
wb = xlsxwriter.Workbook('test.xlsx') # 创建一个新的 excel 表格
sheet = wb.add_worksheet('sheet1') # 创建一个新的 sheet
# 将 data 数组的数据插入到 excel 表格中
# 增加样式配置
style = wb.add_format({
'bold': True, # 字体加粗
'border': 1, # 单元格边框宽度
'align': 'left', # 水平对齐方式
'valign': 'vcenter', # 垂直对齐方式
'fg_color': 'yellow', # 单元格背景颜色
'text_wrap': True, # 是否自动换行
'font_color': 'red', # 文字颜色
})
for row, item in enumerate(data):
for column, value in enumerate(item):
sheet.write(row, column, value, style)
wb.close()
xlsxwriter 包中我们可以按照行、列进行插入数据,具体使用的方法为:
# -*- coding: utf-8 -*-
import xlsxwriter
data1 = ['年份', '数量', '剩余数量']
data2 = ['2013', '100', '50']
wb = xlsxwriter.Workbook('test.xlsx')
sheet = wb.add_worksheet('sheet1')
sheet.write_row('A1', data1)
sheet.write_row('A2', data2)
sheet = wb.add_worksheet('sheet2')
sheet.write_column('A1', data1)
sheet.write_column('B1', data2)
wb.close()
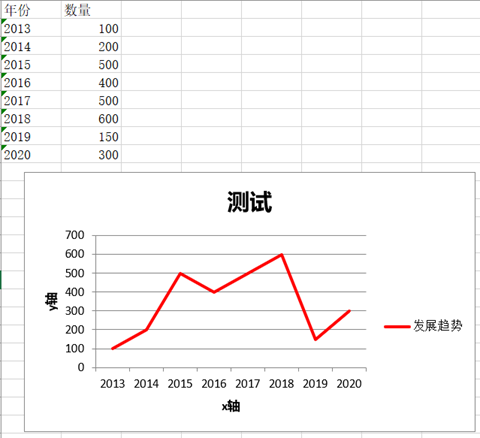
xlsxwriter 包中我们可以给 excel 插入图表,简单梳理如下:
# -*- coding: utf-8 -*-
import xlsxwriter
wb = xlsxwriter.Workbook('test.xlsx') # 创建新的 excel
sheet = wb.add_worksheet('sheet1') # 创建新的 sheet
# 向 excel 文件中插入数据
data1 = ['年份', '2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020']
sheet.write_column('A1', data1)
data2 = ['数量', 100, 200, 500, 400, 500, 600, 150, 300]
sheet.write_column('B1', data2)
# 设置图表类型, type 常见参数有: area:面积图, bar:条形图, column:直方图, doughnut:环状图, line:折线图, pie:饼状图, scatter:散点图, radar:雷达图, stock: 箱线图
chart = wb.add_chart({'type': 'line'})
# 给图表设置信息
chart.add_series(
{
'name': '发展趋势', # 设置折线名称
'categories': '=sheet1!$A$2:$A$9', # 设置 x 轴信息
'values': '=sheet1!$B$2:$B$9', # 设置 y 轴信息
'line': {'color': 'red'} # 给折线设置样式
}
)
chart.set_title({'name': '测试'}) # 设置表头标题
chart.set_x_axis({'name': "x 轴"}) # 设置 x 轴名称
chart.set_y_axis({'name': 'y 轴'}) # 设置 y 轴名称
chart.set_style(1)
sheet.insert_chart('A10', chart, {'x_offset': 25, 'y_offset': 10}) # 放置图表位置
wb.close()
xlsxwriter模块常用功能
设置单元格格式
通过字典的方式直接设置格式:
workfomat = workbook.add_format({
'bold': True, # 字体加粗
'border': 1, # 单元格边框宽度
'align': 'center', # 对齐方式
'valign': 'vcenter', # 字体对齐方式
'fg_color': '#F4B084', # 单元格背景颜色
'text_wrap': True, # 是否自动换行
})
通过 format 对象的方式设置单元格格式:
workfomat = workbook.add_format()
workfomat.set_bold(1) # 设置边框宽度
workfomat.set_num_format('0.00') # 格式化数据格式为小数点后两位
workfomat.set_align('center') # 设置对齐方式
workfomat.set_fg_color('blue') # 设置单元格背景颜色
workfomat.set_bg_color('red') # 设置单元格背景颜色(经测试和上边的功能一样)
一些单元表的操作,像这样的操作还有好多,可以根据自己的需要去进行研究。
worksheet.merge_range('D1:D7', '合并单元格') # 合并单元格
worksheet.set_tab_color('red') # 设置sheet标签颜色
worksheet.set_column('A:D', 25) # 设置A到D列的列宽为25
worksheet.write_formula('E2', '=B2/C2') # 设置表格中的计算,‘E2’是计算结果,'=B2/C2'是计算公式
# 写入单个单元格数据
# row:行,col:列,data:要写入的数据, bold:单元格的样式
worksheet1.write(row, col, data, bold)
# 写入一整行,A1:从A1单元格开始插入数据,按行插入,data:要写入的数据(格式为一个列表), bold:单元格的样式
worksheet1.write_row("A1", data, bold)
# 写入一整列,A1:从A1单元格开始插入数据,按列插入,data:要写入的数据(格式为一个列表), bold:单元格的样式
worksheet1.write_column("A1", data, bold)
# 插入图片,第一个参数是插入的起始单元格,第二个参数是图片你文件的绝对路径
worksheet1.insert_image('A1', 'f:\\1.jpg')
# 写入超链接
worksheet1.write_url(row, col, "internal:%s!A1" % ("要关联的工作表表名"), string="超链接显示的名字")
# 插入图表
"""参数中的type指的是图表类型,图表类型示例如下:[area:面积图, bar:条形图, column:直方图,
doughnut:环状图, line:折线图, pie:饼状图, scatter:散点图, radar:雷达图, stock:箱线图]"""
workbook.add_chartsheet(type="")
# 获得当前excel文件的所有工作表
"""
workbook.worksheets()用于获得当前工作簿中的所有工作表,
这个函数的存在便利了对于工作表的循环操作,
如果你想在当前工作簿的所有工作表的A1单元格中输入一个字符创‘Helloxlsxwriter’,
那么这个命令就派上用场了。
"""
workbook.worksheets()
# 关闭excel文件
"""
这个命令是使用xlsxwriter操作Excel的最后一条命令,一定要记得关闭文件。
"""
workbook.close()
常用图表类型:
- area:创建一个Area(实线)样式表。
- bar:创建条形样式(转置直方图)图表。
- column:创建列样式(直方图)图表。
- line:创建线型图表。
- pie:创建一个饼图样式图表。
- doughnut:创建一个甜甜圈样式表。
- scatter:创建散点图样式图。
- stock:创建一个股票样式图。
- radar:创建雷达样式表。
示例代码解析
import xlsxwriter
workbook = xlsxwriter.Workbook('chart_data_table.xlsx') # 可以生成.xls文件但是会报错
worksheet = workbook.add_worksheet('Sheet1') # 工作页
# 准备测试数据
bold = workbook.add_format({'bold': 1})
headings = ['Number', 'Batch 1', 'Batch 2']
data = [
[2, 3, 4, 5, 6, 7],
[10, 40, 50, 20, 10, 50],
[30, 60, 70, 50, 40, 30],
]
# 插入数据
worksheet.write_row('A1', headings, bold) # 行插入操作注意这里的'A1'
worksheet.write_column('A2', data[0]) # 列插入操作注意这里的'A2'
worksheet.write_column('B2', data[1])
worksheet.write_column('C2', data[2])
# 插入直方图1
chart1 = workbook.add_chart({'type': 'column'}) # 选择直方图'column'
chart1.add_series({
'name': '=Sheet1!$B$1',
'categories': '=Sheet1!$A$2:$A$7', # X轴值(实在不知道怎么叫,就用XY轴表示)
'values': '=Sheet1!$B$2:$B$7', # Y轴值
'data_labels': {'value': True} # 显示数字,就是直方图上面的数字,默认不显示
})
# 注意上面写法'=Sheet1!$B$2:$B$7'Sheet1是指定工作页,$A$2:$A$7是从A2到A7数据,熟悉excel朋友应该一眼就能认得出来
# 插入直方图2
chart1.add_series({
'name': ['Sheet1', 0, 2],
'categories': ['Sheet1', 1, 0, 6, 0],
'values': ['Sheet1', 1, 2, 6, 2],
'data_labels': {'value': True}
})
chart1.set_title({'name': 'Chart with Data Table'}) # 直方图标题
chart1.set_x_axis({'name': 'Test number'}) # X轴描述
chart1.set_y_axis({'name': 'Sample length (mm)'}) # Y轴描述
chart1.set_table()
chart1.set_style(3) # 直方图类型
worksheet.insert_chart('D2', chart1, {'x_offset': 25, 'y_offset': 10}) # 直方图插入到D2位置
workbook.close()
XlsxWriter支持的类型
Excel对待不同类型的输入数据,例如字符串和数字,处理通常不同,虽然通常对于用户是透明的。XlsxWriter视图用worksheet.write()方法模拟这一点,通过将Python数据类型映射到Excel支持的类型上。
write()方法作为几个更具体方法的通用别名:
- write_string()
- write_number()
- write_blank()
- write_formula()
- write_datetime()
- write_boolean()
- write_url()
在这里的代码中,我们使用了这些方法中的一些来处理不同类型的数据:
worksheet.write_string(row, col, item) worksheet.write_datetime(row, col+1, date, date_format) worksheet.write_number(row, col+2, cost, money_format)
这主要是为了展示如果你需要更多的控制你写入工作表中的数据,你可以使用恰当的方法。在这个简单的例子里,write()方法事实上解决得很好。
对于程序来说日期处理也是新的。
Excel中的日期和时间是应用了数字格式的浮点数,方便以正确的格式显示它们。如果日期和时间是Python datetime对象,那么XlsxWriter会自动进行所需的数字转换。但是,我们还需要添加数字格式来确保Excel将其显示为日期:
from datetime import datetime
date_format = workbook.add_format({'num_format': 'mmmm d yyyy'})
...
for item, date_str, cost in (expenses):
# Convert the date string into a datetime object.
date = datetime.strptime(date_str, "%Y-%m-%d")
...
worksheet.write_datetime(row, col+1, date, date_format)
...
最后需要 set_column() 来调整 B 列的宽度以便于日期可以清晰地展示:
# Adjust the column width.
worksheet.set_column('B:B', 15)
参考链接:
Python Excel 读写之 OpenPyXL
openpyxl 是一个开源项目,openpyxl 模块是一个读写 Excel 2010 文档的 Python 库,如果要处理更早格式的 Excel 文档,需要用到其它库(如:xlrd、xlwt 等)。openpyxl 是一款比较综合的工具,不仅能够同时读取和修改 Excel 文档,而且可以对 Excel 文件内单元格进行详细设置,包括单元格样式等内容,甚至还支持图表插入、打印设置等内容,使用 openpyxl 可以读写 xltm, xltx, xlsm, xlsx 等类型的文件。
使用 openpyxl 的一般流程为:创建/读取 excel 文件–>选择 sheet 对象–>对表单/cell 进行操作–>保存 excel
创建/读取excel文件
from openpyxl import Workbook
from openpyxl import load_workbook
wb = Workbook() # 新建空白工作簿
wb = load_workbook('1.xlsx') # 读取 excel
wb.save('filename.xlsx') # 保存 excel
sheet表单操作
from openpyxl import load_workbook
wb = load_workbook('读取表.xlsx') # 读取 excel
print(wb.sheetnames) # 以 list 方式返回 excel 文件所有 sheet 名称(->list[str,str..])
# 选定需要操作的 sheet
ws = wb['第一个 sheet'] # 根据 sheet 名称选取
ws = wb.active # 选择当前活动的 sheet,默认为第一个
# 创建新的 sheet
ws = wb.create_sheet("newsheet_end") # 默认插入到最后
ws = wb.create_sheet("newsheet_first", 0) # 插入到最开始的位置(从 0 开始计算)
# 复制一个 sheet 对象
source = wb.active
target = wb.copy_worksheet(source)
# 移动工作表
wb.move_sheet(ws, offset=0)
# sheet 常见属性
ws = wb['第一个 sheet'] # 根据 sheet 名称选取
print(ws.title) # sheet 名称
print(ws.max_row) # 最大行
print(ws.max_column) # 最大列
rows = ws.rows # 行生成器,里面是每一行的 cell 对象,由一个 tuple 包裹。
columns = ws.columns # 列生成器,里面是每一列的 cell 对象,由一个 tuple 包裹。
# 可以使用 list(sheet.rows)[0].value 类似方法来获取数据,或
for row in ws.rows:
for cell in row:
print(cell.value)
# 删除 sheet
del wb['第三个 sheet']
wb.save('output.xlsx')
单元格对象
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter, column_index_from_string
wb = load_workbook('读取表.xlsx') # 读取excel
ws = wb.active # 选择当前活动的sheet,默认为第一个
# 根据名称访问
print(ws['A1']) # A列1行的单元对象A1
print(ws['a2']) # 也可以小写A1
# cell方法访问
print(ws.cell(row=2, column=2)) # B2
print(ws.cell(3, 2)) # B3
# 从cell列表中返回
print(list(ws.rows)[2][1]) # B3
print(list(ws.columns)[1][2]) # B3
# 选择多个单元格
a2_b3 = ws['a2':'b3'] # 切片访问,以行组成tuple返回tuple
print(a2_b3)
# 单独字母与数字返回列与行的所有数据
b = ws['b'] # 返回b列的所有cell对象
print(b)
row1 = ws['1'] # 返回第1行的所有cell
row1 = ws[1] # 加引号和不加引号效果一样
print(row1)
# 当然也能范围选择
a_e = ws['a:e'] # a-e列的cell对象
print(a_e)
# 单元格属性
cell = ws['A1']
print(cell.column)
print(cell.row)
print(cell.value) # 注意:如果单元格是使用的公式,则值是公式而不是计算后的值
print(cell.number_format) # 返回单元格格式属性,#默认为General格式
print(cell.font) # 单元格样式
# 更改单元格值
# 直接赋值
ws['a2'] = 222
ws['a2'] = 'aaa'
ws['b2'] = '=SUM(A1:A17)' # 使用公式
# value属性赋值
cell.value = 222
# 或
ws.cell(1, 2, value=222)
# 移动单元格
ws.move_range("D4:F10", rows=-1, cols=2) # 表示单元格D4:F10向上移动一行,右移两列。单元格将覆盖任何现有单元格。
ws.move_range("G4:H10", rows=1, cols=1, translate=True) # 移动中包含公式的自动转换
# 合并与拆分单元格
ws.merge_cells('A2:D2') # 合并单元格,以最左上角写入数据或读取数据
ws.unmerge_cells('A2:D2') # 拆分单元格
# 列字母和坐标数字相互转换
print(get_column_letter(3)) # C#根据列的数字返回字母
print(column_index_from_string('D')) # 4#根据字母返回列的数字
# 遍历单元格
# 注意
# openpyxl读取Excel的索引是从1开始的
# 因为range函数是左闭右开,再加上索引是从1开始的,所以最大值都要+1
for i in range(1, ws.max_row + 1):
for j in range(1, ws.max_column + 1):
print(ws.cell(i, j).value)
for row in ws.rows:
for cell in row:
print(cell.value)
for col in ws.cols:
for cell in col:
print(cell.value)
for row in ws.iter_rows(min_row=1, max_col=3, max_row=2):
for cell in row:
print(cell)
for col in ws.iter_cols(min_row=1, max_col=3, max_row=2):
for cell in col:
print(cell)
cell_range = ws['A1':'C2']
for row in cell_range:
for cell in row:
print(cell.value)
for x in tuple(ws.rows):
for y in x:
print(y.value)
for x in tuple(ws.cols):
for y in x:
print(y.value)
# 多个单元格的操作
# 同一行中,多个单元格同时输入
datas = ["A5追加", "B5追加", "C5追加"]
ws.append(datas)
# 复数行中,多个单元格同时输入
datas = [
["A6追加", "B6追加", "C6追加"],
["A7追加", "B7追加", "C7追加"],
]
for row_data in datas:
ws.append(row_data)
格式样式设置
from openpyxl import load_workbook
from openpyxl.styles import Font, colors, Alignment, PatternFill, Border, Side, NamedStyle
wb = load_workbook('读取表.xlsx') # 读取excel
ws = wb.active # 选择当前活动的sheet,默认为第一个
# 字体
font = Font(name='Calibri',
size=11,
bold=False,
italic=False,
vertAlign=None,
underline='none',
strike=False,
color='FF000000')
# 示例:设定字体为等线24号,加粗斜体,字体颜色红色。将字体赋值给A1
ws['A1'].font = Font(name='等线', size=24, italic=True, color=colors.RED, bold=True)
# 对齐方式
alignment = Alignment(horizontal='general',
vertical='bottom',
text_rotation=0,
wrap_text=False,
shrink_to_fit=False,
indent=0)
# 示例:设置B1中的数据垂直居中和水平居中
ws['B1'].alignment = Alignment(horizontal='center', vertical='center')
# horizontal的可用样式为:{'left':'左对齐','center':'居中对齐','right':'右对齐','distributed':'分散对齐','centerContinuous':'跨列居中','justify':'两端对齐','fill':'填充','general':'常规'}
# vertical的可用样式为:{'top':'顶端对齐','center':'居中对齐','bottom':'底端对齐','distributed':'分散对齐','justify':'两端对齐'}
# wrap_text为自动换行。
# 填充单元格颜色
fill = PatternFill(fill_type=None,
start_color='FFFFFFFF',
end_color='FF000000')
ws['A1'].fill = fill
# 可选择的填充样式为:['none','solid','darkDown','darkGray','darkGrid','darkHorizontal','darkTrellis','darkUp','darkVertical','gray0625','gray125','lightDown','lightGray','lightGrid','lightHorizontal','lightTrellis','lightUp','lightVertical','mediumGray']
# 设置行高和列宽
ws.row_dimensions[2].height = 40
ws.column_dimensions['C'].width = 30
# 设置边框
border = Border(left=Side(border_style=None, color='FF000000'),
right=Side(border_style=None, color='FF000000'),
top=Side(border_style=None, color='FF000000'),
bottom=Side(border_style=None, color='FF000000'),
diagonal=Side(border_style=None, color='FF000000'),
diagonal_direction=0,
outline=Side(border_style=None, color='FF000000'),
vertical=Side(border_style=None, color='FF000000'),
horizontal=Side(border_style=None, color='FF000000')
)
# 可选择的边框样式为:['dashDot','dashDotDot','dashed','dotted','double','hair','medium','mediumDashDot','mediumDashDotDot','mediumDashed','slantDashDot','thick','thin']
# 设置工作表标签底色
ws.sheet_properties.tabColor = "1072BA"
# 创建一个样式预设
highlight = NamedStyle(name='highlight')
highlight.font = Font(bold=True, size=20)
bd = Side(style='thick', color='000000')
highlight.border = Border(left=bd, top=bd, right=bd, bottom=bd)
# Once a named style has been created, it can be registered with the workbook:
wb.add_named_style(highlight)
# Named styles will also be registered automatically the first time they are assigned to a cell:
ws['A1'].style = highlight
# Once registered, assign the style using just the name:
ws['D5'].style = 'highlight'
其他
from openpyxl import load_workbook
from openpyxl.drawing.image import Image
from openpyxl.comments import Comment
wb = load_workbook('读取表.xlsx') # 读取excel
ws = wb.active # 选择当前活动的sheet,默认为第一个
# 插入图片
img = Image('logo.png')
img.width, img.height = (180, 80) # 指定图片尺寸,可省略
ws.add_image(img, 'A1')
# 插入批注
comment = Comment('This is the comment text', 'Comment Author')
ws["A1"].comment = comment
Python Excel操作之xlwings
xlwings是一个基于 BSD-licensed的Python库。它让Python和Excel之间的相互调用变得更加容易:
- Scripting(脚本):使用类似VBA的语法,在Python中自动处理Excel数据或者与Excel交互。
- Macros(宏):用强大而干净的Python代码替代VBA宏。
- UDFs(用户定义函数):用Python编写用户定义函数(UDFs),仅适用于windows系统。
- REST API:通过REST API向外部开放Excel工作簿。
- 支持Windows和MacOS
xlwings开源免费,能够非常方便的读写Excel文件中的数据,并且能够进行单元格格式的修改。xlwings还可以和matplotlib、Numpy以及Pandas无缝连接,支持读写Numpy、Pandas的数据类型,将matplotlib可视化图表导入到excel中。最重要的是xlwings可以调用Excel文件中VBA写好的程序,也可以让VBA调用用Python写的程序。支持.xls文件的读,支持.xlsx文件的读写。
xlwings的主要结构:
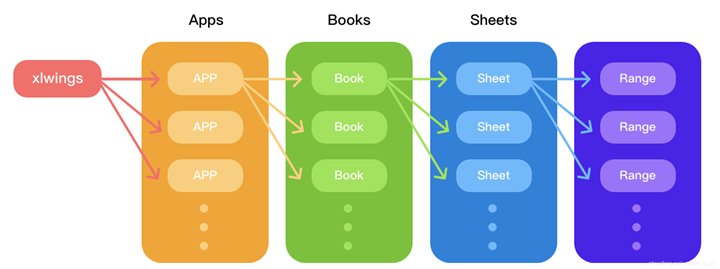
可以看到,和xlwings直接对接的是apps,也就是Excel应用程序,然后才是工作簿books和工作表sheets,最后是单元格区域range,这点和openpyxl有较大区别,也正是因为此,xlwings需要依然安装有Excel应用程序的环境。
App常用语法
import xlwings as xw
# 创建应用 app:
# 参数:visible:应用是否可见(True|False), add_book: 是否创建新工作簿(True|False)
app = xw.App(visible=True, add_book=True)
wb = app.books.active # get 新创建的工作簿(刚创建的工作簿为活动工作簿,使用 active 获取)
# 警告提示(True|False)
app.display_alerts = False
# 屏幕刷新(True|False)
app.screen_updating = False
# 工作表自动计算{'manual':'手动计算','automatic':'自动计算','semiautomatic':'半自动'}
app.calculation = 'manual'
# 应用计算, calculate 方法同样适用于工作簿,工作表
app.calculate()
# 退出应用
app.quit()
Book常用语法
import xlwings as xw app = xw.App(visible=True, add_book=False) # 新建工作簿 wb = app.books.add() # 方法1 wb = xw.Book() # 方法2 wb = xw.books.add() # 打开工作簿 file_path = '读取表.xlsx' wb = app.books.open(file_path) wb = xw.Book(file_path) # 工作簿保存 wb.save() wb.save(path=None) # 或者指定 path 参数保存到其他路径,如果没保存为脚本所在路径 # 其他:获取名称、激活、关闭 wb = xw.books['工作簿名称'] # get 指定名称的工作簿 wb.activate() # 激活为当前工作簿 print(wb.fullname) # 返回工作簿的绝对路径 print(wb.name) # 工作簿名称 wb.close() # 关闭工作簿
Sheet常用语法
import xlwings as xw # 工作表引用 wb = xw.books['工作簿名字'] sheet = wb.sheets['工作表名字'] sheet = wb.sheets[0] # 也可以使用数字索引,从0开始,类似于vba的worksheets(1) sheet = xw.sheets.active # 当前活动工作表,sheets是工作表集合 sheet = wb.sheets.active # 新建工作表表 # 参数:name:新建工作表名称;before创建的工作表位置在哪个工作表前面;after:创建位置在哪个工作表后面; # before和after参数可以传入数字,也可以传入已有的工作表名称,传入数字n表示从左往右第n个sheet位置 # before和after参数不传,创建sheet默认在当前活动工作表左侧 sheet = xw.sheets.add(name=None, before=None, after=None) wb.sheets.add(name='新工作表4', before='新工作表') sheet.activate() # 激活为活动工作簿 sheet.clear() # 清除工作表的内容和格式 sheet.clear_contents() # 清除工作表内容,不清除样式 sheet_name = sheet.name # 工作表名称 sheet.delete() # 删除工作表 sheet.calculate() # 工作表计算 sheet.used_range # 工作表的使用范围,等价与vba的usedrange # 自动匹配工作表列、行宽度 # 若要自动调整行,请使用以下内容之一:rows或r # 若要自动装配列,请使用以下内容之一:columns或c # 若要自动调整行和列,请不提供参数。 sheet.autofit()
Range常用语法
import xlwings as xw
import datetime
# 单元格引用
rng = xw.books['工作簿名称'].sheets['工作表名称'].range('a1')
# 第一个应用第一个工作簿第一张sheet的第一个单元格
xw.apps[0].books[0].sheets[0].range('a1')
# 引用活动sheet的单元格,直接接xw,Range首字母大写
rng = xw.Range('a1') # a1
rng = xw.Range(1, 1) # a1,行列用tuple进行引用,圆括号从1开始
rng = xw.Range((1, 1), (3, 3)) # a1:a3
# 也可以工作表对象接方括号引用单元格
sheet = xw.books['工作簿'].sheets['工作表名称']
rng = sheet['a1'] # a1单元格
rng = sheet['a1:b5'] # a1:b5单元格
rng = sheet[0, 1] # b1单元格,也可以根据行列索引,从0开始为
rng = sheet[:10, :10] # a1:j10
# 单元格邻近范围
rng = sheet[0, 0].current_region # a1单元格邻近区域=vba:currentregion
# 返回excel:ctrl键+方向键跳转单元格对象:上:up,下:down,左:left,右:right
# 等同于vba:end语法:xlup,xldown,xltoleft,xltoright
rng = sheet[0, 0].end('down')
# 数据的读取
# 获取单元格的值,单元格的value属性
val = sheet.range('a1').value
ls = sheet.range("a1:a2").value # 一维列表
ls = sheet.range("a1:b2").value # 二维列表
# 单元格值默认读取格式
# 默认情况下,带有数字的单元格被读取为float,带有日期单元格被读取为datetime.datetime,空单元格转化为None;数据读取可以通过option操作指定格式读取
sheet[1, 1].value = 1
sheet[1, 1].value # 输出是1.0
sheet[1, 1].options(numbers=int).value # 输出是1
sheet[2, 1].options(dates=datetime.date).value # 指定日期格式为datetime.date
sheet[2, 1].options(empty='NA').value # 指定空单元格为'NA'
# 单元格数据写入
sheet.range('a1').value = 1 # 单个值
sheet.range("a1:c1").value = [1, 2, 3] # 写入一维列表
sheet.range("a1:a3").options(transpose=True).value = [1, 2, 3] # option:设置transpose参数转置下
sheet.range("a1:a3").value = [1, 2, 3] # 写入二维列表
sheet.range('A1').options(expand='table').value = [[1, 2], [3, 4]]
sheet.range('A1').value = [[1, 2], [3, 4]] # 也可以直接这样写
# '''
# 尽量减少与excel交互次数有助于提升写入速度
# sheet.range('A1').value = [[1, 2], [3, 4]]
# 比sheet.range('A1').value = [1, 2]和sheet.range('A2').value = [3, 4]会更快
# '''
# expand:动态选择Range维度
# 可以通过单元格的expand或者options的expand属性动态获取excel中单元格维度;两者再使用区别是,使用expand方法,只有在访问范围的值才会计算;
# options方法会随着单元格值范围扩增而相应的范围增大,区别示例如下:
# expand参数值除了’table’,还可以使用‘right’:向右延伸,‘down’:向下延伸;
sheet = xw.sheets.add(name='工作表名称')
sheet.range('a1').value = [[1, 2], [3, 4]]
rng1 = sheet.range('a1').options(expand='table') # 使用options方法
rng2 = sheet.range('a1').expand('table') # 使用expand方法,默认是table,‘table’参数也可以不填
sheet.range('a3').value = [5, 6] # 现在新增一行数据
print(rng1.value) # [[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]]
print(rng2.value) # [[1.0, 2.0], [3.0, 4.0]]使用的expand方法,范围没有扩散
print(sheet.range('a1').options(expand='table').value) # [[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]],再次expand方法访问,值范围扩散
转化器
import xlwings as xw
import numpy as np
import pandas as pd
sheet = xw.books['工作簿'].sheets['工作表名称']
# 字典转化
sheet.range('a1').value = [['a', 1], ['b', 2]] # 字典转化可以将excel两列数据读取为字典,如果是两行数据,使用transpose转置下;
sheet.range('a1:b2').options(dict).value # {'a': 1.0, 'b': 2.0}
sheet.range('a4').value = [['a', 'b'], [1, 2]]
sheet.range('a4:b5').options(dict, transpose=True).value # {'a': 1.0, 'b': 2.0}
# numpy转化
# 相关参数:ndim=None(维度,:1维也可以设置为2转化成二维array), dtype=None(可指定数据类型)
sheet = xw.Book().sheets[0]
sheet.range('A1').options(transpose=True).value = np.array([1, 2, 3])
sheet.range('A1:A3').options(np.array, ndim=2).value # 返回二维数组
# 其他方法
rng = xw.Range('A1') # 引用当前活动工作表的单元格
rng.add_hyperlink(r'https://www.baidu.com', '百度', '提示:点击即链接到百度') # 加入超链接
rng.address # 取得当前range的地址
rng.get_address() # 取得当前range的地址
rng.clear_contents() # 清除range的内容
rng.clear() # 清除格式和内容
rng.color # 取得range的背景色,以元组形式返回RGB值
rng.color = (255, 255, 255) # 设置range的颜色
rng.color = None # 清除range的背景色
rng.column # 获得range的第一列列标
rng.row # range的第一行行标
rng.count # 返回range中单元格的数据
rng.formula = '=SUM(B1:B5)' # 获取公式或者输入公式
rng.formula_array # 数组公式
rng.get_address(row_absolute=True, column_absolute=True, include_sheetname=False, external=False) # 获得单元格的绝对地址
rng.column_width # 获得列宽
rng.width # 返回range的总宽度
rng.hyperlink # 获得range的超链接
rng.last_cel # 获得range中右下角最后一个单元格
rng.offset(row_offset=0, column_offset=0) # range平移
rng.resize(row_size=None, column_size=None) # range进行resize改变range的大小
rng.row_height # 行的高度,所有行一样高返回行高,不一样返回None
rng.height # 返回range的总高度
rng.shape # 返回range的行数和列数
rng.sheet # 返回range所在的sheet
rng.rows # 返回range的所有行
rng.rows[0] # range的第一行
rng.rows.count # range的总行数
rng.columns # 返回range的所有列
rng.columns[0] # 返回range的第一列
rng.columns.count # 返回range的列数
rng.autofit() # 所有range的大小自适应
rng.columns.autofit() # 所有列宽度自适应
rng.rows.autofit() # 所有行宽度自适应
# Pandas
# Series与DataFrame转化器
# 相关参数:ndim=None, index=1(多列,是否使用第一列为索引), header=True(表头), dtype=None;
# DataFrame的表头可以设置为1,2,1等价于True,2表示二维表头;index:0等价与False,1等价于True,第一列设置为索引
# 写入两列数据
sheet.range('a1').values = [['name', 'age'], ['张三', 18], ['李四', 20], ['王五', 35]]
# index=0,第一列不为索引,读取结果为DataFrom
df = sheet.range('a1').options(pd.Series, expand='table', index=0).value
# index=1,第一列设置为索引,输出为Series
s = sheet.range('a1').options(pd.Series, expand='table', index=1).value
# 写入,不需要索引,index设置为False,保留表头,header=True
sheet.range('d1').options(pd.DataFrame, index=False, header=True).value = df
# 读取为DataFrame
df = sheet.range('a1').options(pd.DataFrame, expand='table', index=0).value
参考链接:
Python Excel快速写入工具PyExcelerate
PyExcelerate号称是性能最好的Excel xlsx文件的Python写入包。使用起来也相对比较简单。
from datetime import datetime
from pyexcelerate import Workbook, Color, Style, Font, Fill, Format
# Writing bulk data
# Fastest
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # data is a 2D array
wb = Workbook()
wb.new_sheet("sheet name", data=data)
wb.save("output.xlsx")
# Writing bulk data to a range
# Fastest
wb = Workbook()
ws = wb.new_sheet("test", data=[[1, 2], [3, 4]])
wb.save("output.xlsx")
# Fast
wb = Workbook()
ws = wb.new_sheet("test")
ws.range("B2", "C3").value = [[1, 2], [3, 4]]
wb.save("output.xlsx")
# Writing cell data
# Faster
wb = Workbook()
ws = wb.new_sheet("sheet name")
ws.set_cell_value(1, 1, 15) # a number
ws.set_cell_value(1, 2, 20)
ws.set_cell_value(1, 3, "=SUM(A1,B1)") # a formula
ws.set_cell_value(1, 4, datetime.now()) # a date
wb.save("output.xlsx")
# Selecting cells by name
wb = Workbook()
ws = wb.new_sheet("sheet name")
ws.cell("A1").value = 12
wb.save("output.xlsx")
# Merging cells
wb = Workbook()
ws = wb.new_sheet("sheet name")
ws[1][1].value = 15
ws.range("A1", "B1").merge()
wb.save("output.xlsx")
# Styling cells
wb = Workbook()
ws = wb.new_sheet("sheet name")
ws.set_cell_value(1, 1, 1)
ws.set_cell_style(1, 1, Style(font=Font(bold=True)))
ws.set_cell_style(1, 1, Style(font=Font(italic=True)))
ws.set_cell_style(1, 1, Style(font=Font(underline=True)))
ws.set_cell_style(1, 1, Style(font=Font(strikethrough=True)))
ws.set_cell_style(1, 1, Style(fill=Fill(background=Color(255, 0, 0, 0))))
ws.set_cell_value(1, 2, datetime.now())
ws.set_cell_style(1, 1, Style(format=Format('mm/dd/yy')))
wb.save("output.xlsx")
# Styling ranges
wb = Workbook()
ws = wb.new_sheet("test")
ws.range("A1", "C3").value = 1
ws.range("A1", "C1").style.font.bold = True
ws.range("A2", "C3").style.font.italic = True
ws.range("A3", "C3").style.fill.background = Color(255, 0, 0, 0)
ws.range("C1", "C3").style.font.strikethrough = True
# Styling rows
wb = Workbook()
ws = wb.new_sheet("sheet name")
ws.set_row_style(1, Style(fill=Fill(background=Color(255, 0, 0, 0))))
wb.save("output.xlsx")
# Styling columns
wb = Workbook()
ws = wb.new_sheet("sheet name")
ws.set_col_style(1, Style(fill=Fill(background=Color(255, 0, 0, 0))))
wb.save("output.xlsx")
# Available style attributes
ws[1][1].style.font.bold = True
ws[1][1].style.font.italic = True
ws[1][1].style.font.underline = True
ws[1][1].style.font.strikethrough = True
ws[1][1].style.font.color = Color(255, 0, 255)
ws[1][1].style.fill.background = Color(0, 255, 0)
ws[1][1].style.alignment.vertical = 'top'
ws[1][1].style.alignment.horizontal = 'right'
ws[1][1].style.alignment.rotation = 90
ws[1][1].style.alignment.wrap_text = True
ws[1][1].style.borders.top.color = Color(255, 0, 0)
ws[1][1].style.borders.right.style = '-.'
# Setting row heights and column widths
wb = Workbook()
ws = wb.new_sheet("sheet name")
ws.set_col_style(2, Style(size=0))
wb.save("output.xlsx")
# Linked styles
wb = Workbook()
ws = wb.new_sheet("sheet name")
ws[1][1].value = 1
font = Font(bold=True, italic=True, underline=True, strikethrough=True)
ws[1][1].style.font = font
wb.save("output.xlsx")
# Pandas DataFrames
ws = wb.new_sheet("sheet name", data=df.values.tolist())
Python读写Excel工具pyexcel
PyExcel是开源的Excel操作库。它包装了一套API用于读和写文件数据,这一套API接受的参数包括2个关键字集合,一个指定数据来源,另一个指定目的文件,每个集合里都有很多关键字参数控制读写细节。pyexcel包还实现了工作簿、表单类型,用于访问、操作和保存数据,读写操作十分花式。
读文件
pyexcel包含了一些读文件的get函数:get_array、get_dict、get_record、get_book、get_book_dict、get_sheet,这些方法将文件内容转换为array、dict、sheet/book等多种类型,屏蔽了文件介质是csv/tsv文本、xls/xlsx表格文件、dict/list类型、sql数据库表等的细节。同时还有一套同等的iget系列函数,唯一的不同是返回生成器,以提高效率。
- get_sheet函数接收sheet_name参数,对于有多个sheet的Excel表格,用于指定要读取的sheet,如果缺省,则读取第1个sheet。get_sheet函数还接收name_columns_by_row/name_rows_by_column参数,用于将指定的行/列作为列/行名称,默认值为0,代表第1行,sheet.Sheet类有同名的方法进行同样的操作。其他几个函数与get_sheet较相似,接受的参数也相同。
- get_array函数将文件数据转换为数组,即嵌套的列表,列表每个元素对应表格一行。
- get_dict函数将文件数据转换为有序字典,用第1行的字段作为key,后续行值组成列表作为value。
- get_record函数将文件数据转换为有序字典形成的列表,每行数据对应一个有序字典,字典将文件首行字段作为key、数据行作为value。
- get_book函数将文件转换为 book.Book 对象,如果从 csv 文件读取,则只包含 1 个 sheet,名称就是文件名;如果从 xls 文件读取,则包含 xls 文件中所有 sheet。
- get_book_dict 函数将文件数据转换为多 sheet 的有序字典,sheet 名称作为 key,sheet 数据以嵌套列表形式作为 value,这在含有多 sheet 的 Excel 表格中较有用;对于 csv 文件,由于只有 1 个 sheet,返回的有序字典仅有 1 项。
数据访问
Book 和 Sheet
pyexcel 中实现了 pyexcel.book.Book 和 pyexcel.book.Sheet 类型,和 Excel 表格文件的 book、sheet 概念相对应,可以通过上述 get 系列函数得到 book/sheet 对象,也可以通过 pyexcel.Book()/pyexcel.Sheet() 函数创建。
拿到 book 对象后,下一步就是访问 book 中的 sheet。pyexcel.book.Book 类对象可以按序号索引对应的 sheet,也可以调用 sheet_by_index 和 sheet_by_name 方法获得指定的 sheet 内容,调用 sheet_names 方法返回 book 对象包含的所有 sheet 名称。
pyexcel.sheet.Sheet 类对象有个 texttable 属性,即表示文本,除了 sheet 名称,还有绘制表格边框的虚线符,直接打印变量 sh 和打印 sh.texttable 效果相同。
此外,pyexcel.sheet.Sheet 类还有几个十分有用的属性。
- content 属性,与直接显示 sheet 相比,就少了第一行的 sheet 名称。
- csv 属性,sheet 数据的 csv 形式,没有表格框线。
- array 属性,sheet 数据的 array 形式(嵌套列表),与 get_array 函数返回结果一样。
- row/column 属性,非常类似嵌套 list,支持通过下标访问指定行/列,序号从 0 起始。
行和列
拿到 pyexcel.sheet.Sheet 对象后,除了用 row/column 属性获得所有行/列对象集合,进一步迭代遍历,也可以通过序号索引任意行/列,序号从 0 起始。当序号超出表格行/列范围时便抛出 IndexError 错误,可以用 sheet 对象的 row_range/column_range 方法查看行/列范围。pyexcel.sheet.Sheet 对象的 row_at/column_at 方法,与直接通过 row/column 属性序号索引等效。
单元格
pyexcel.sheet.Sheet 对象支持二元序号索引任意单元格,或者用行/列名称替代序号(请注意下述代码注释)。也可以整体用 Excel 表单元格地址形式索引,无需任何转换。
改写文件
改写文件包括改写变量值、将变量对象写入文件两个步骤,推荐通过 pyexcel.book.Sheet 或 pyexcel.book.Book 类对象进行。
对于 pyexcel.book.Sheet 类对象,row、column 属性支持像 list 那样增删改操作,而且均有 save_as 方法用于将对象写入文件。此外,pyexcel 提供了 save 系列封装函数:save_as、save_book_as 写入文件,指定目的文件时,使用的参数名称与 get 系列相比较多了 “dest_” 前缀。如,get 系列用 file_name 指定数据文件来源,save 系列用 dest_file_name 指定目的文件路径;get 系列用 delimiter 参数指定 csv 分隔符,save 系列用 dest_delimiter 指定写入到 csv 文件时使用的分隔符。pyexcel.book.Sheet 类对象可以整行/列地增、删、改,也可以定位到具体单元格赋值,使用列表整行/列赋值时要注意元素个数与列/行数一致。对于 pyexcel.book.Book 类对象,既可以把整个 book 像操作列表那样整体扩展,也可以只索引出某些 sheet 再进行整体拼接、赋值。pyexcel.book.Sheet 还实现了表单转置(transpose)、截取(region)、剪切(cut)、粘贴(paste)、map 应用(map)、行列筛选(filter)、格式化(format)等花式操作方法。
写入文件,即可用 pyexcel.book.Sheet 或 pyexcel.book.Book 类对象的 save_as 方法,操作简单直接,操作 Excel 推荐首选。也可以用 pyexcel 包级别的 save 系列封装函数,更适合进行文件类型转换,同时还有一套同等的 isave 系列函数,主要的不同是只在写时读入变量,以提高效率。以上这些 save 方法/函数会根据目的文件扩展名自动判别格式类型。pyexcel.book.Sheet 或 pyexcel.book.Book 类还实现 save_to 系列函数,将对象写入数据库、ORM、内存等。
总结
- pyexcel 包封装了 get 系列函数用于从文件中读取、转换数据,均能灵活支持多种读文件方式,对于操作 Excel 文件,推荐首选 get_sheet 函数。
- pyexcel 包对不同格式文件的支持依赖不同的插件包。
- pyexcel 包内部实现了 book.Sheet 或 pyexcel.book.Book 类型,与 Excel 文件的工作簿、表单概念对应,提供了多种灵活的数据访问、删改的方法,以及可视化的方法。
- book.Sheet 或 pyexcel.book.Book 类型有 save 系列方法将对象变量写入文件、数据库、内存等,推荐首选;同时 pyexcel 包级别的 save_as 系列封装函数,对于转换文件类型十分方便;这些写入文件的方法/函数,根据目的文件扩展名自动判别格式类型。
- cookbook 包封装了一些实用工具函数,如多类型文件合并、表格分拆;
- book.Sheet 和 pyexcel.book.Book 等类的方法并未实现全,调用时有的会抛出错误,要注意这个大坑,本文在 ipython 环境写示例时错误的未给出,这也是提示符编号不连续的原因。
参考链接:
其他工具:
- Excel 公式工具:https://github.com/vinci1it2000/formulas



文章还是挺好的,简洁丰富无废话