PySpark简介 PySpark是Apache Spark的Python API,它使得Python开发者能够使用Spark的分布式计算能力进行大规模数据处理和分析。PySpark提供了与Scala和Java API类似的功能,并且与Python生态系统(如Pandas、NumPy…

Spark简介 ApacheSpark是一个开源的分布式计算框架,专为大规模数据处理而设计。它提供了丰富的工具和库,支持多种数据处理任务,包括批处理、流处理、机器学习和图计算。Spark以其速度、易用性和通用性而闻名,广…

Apache Storm简介 Apache Storm是一个开源的、分布式的实时计算系统,旨在处理和分析大规模的数据流。它可以持续地接收数据,并在收到数据后立即进行处理,适用于需要低延迟的数据处理场景,如实时数据分析、在线机…
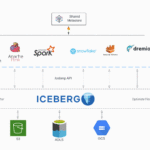
Apache Iceberg 简介 Apache Iceberg 是一种用于庞大分析数据集的开放表格式。它的设计目标是解决传统数据湖存储格式(如 Hive)在管理大规模数据时遇到的关键问题,提供可靠的数据存储和管理功能。 基本定…
requests-html简介 requests-html是一个用于网页抓取和解析的Python库,由Kenneth Reitz创建,旨在为开发者提供一个强大且易用的工具来处理HTML内容。与传统的网页抓取库不同,requests-html集成了对现代网页技术(…

timeit:计时小段代码的执行时间 timeit是Python标准库中的一个模块,用于测量小段代码的执行时间。它提供了一种精确、可靠的方式来对代码的性能进行基准测试,避免了诸如系统时间变化和其他外部因素的影响。timeit…
在先前整理的自然语言处理之自动摘要这篇文章中介绍了TextTeaser和TextRank两种自动摘要的方法。今天要介绍的sumy工具不但包含了上述两种方法,还包含了其他文本摘要方法。 Sumy简介 sumy是一个用于文本摘要…

Sentry简介 Sentry是一个流行的开源实时错误监控工具,主要用于应用程序的日志监控和错误跟踪。它能够帮助开发者快速识别、诊断和修复在生产环境中出现的问题。 以下是Sentry的一些主要特点和功能: 错误捕获…
Logging是Python标准库中自带的日志记录工具,事实上还有很多比它更好第三方日志工具。 logbook Logbook是一个用于替代Python标准库logging模块的日志记录库。它旨在提供更简洁和强大的日志记录接口,改善日志记…
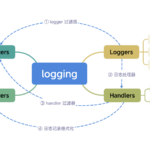
logging模块简介 Python的logging模块是一个非常强大的工具,用于在应用程序中记录和管理日志信息。它提供了灵活的功能,可以在不同的输出目标(如控制台、文件、网络等)中记录日志,并支持不同的日志级别。先前基…