Apache NiFi 简介 Apache NiFi 是一个强大的数据流管理和自动化工具,旨在简化数据的采集、传输、处理和分发。它特别适合于构建和管理复杂的数据流管道,支持从各种数据源到不同目标系统的数据传输。 Apache NiFi…
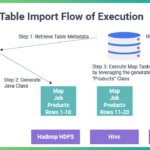
Sqoop简介 Sqoop(SQL-to-Hadoop)是一个开源工具,主要用于在Apache Hadoop和传统关系型数据库(如MySQL、PostgreSQL、Oracle、SQL Server等)之间高效传输大规模数据。它简化了数据从关系数据库到Hadoop分布式文…
DataX简介 DataX是阿里巴巴开源的一款轻量级的数据同步工具,旨在解决异构数据源之间的数据传输问题。它支持多种数据源,包括关系型数据库、NoSQL数据库、Hadoop、FTP、消息队列等。DataX的设计目标是提供一个简单…
Tile38简介 Tile38是一个开源的内存型地理空间数据库,专门用于处理地理空间数据和位置服务。它是由AxiomDataScience开发的,旨在支持实时地理空间应用。Tile38提供了丰富的功能,使其成为处理地理位置数据的强大工…
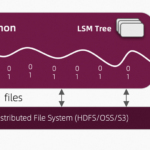
Paimon简介 Apache Paimon是一个面向大数据生态系统的高性能数据湖存储系统。它最初是由Flink社区开发的,旨在为大数据处理提供高效的存储解决方案。 Apache Paimon(以前称为Flink Table Store)是一个专为流处…
io模块简介 io模块是Python标准库中的一个核心模块,提供了Python对I/O操作的基本支持。它支持各种文件和流的读写操作,并且为不同类型的I/O操作提供了统一的接口。io模块是Python3引入的,用于替代Python2中的fil…

玩过《艾迪芬奇的记忆》已经有好长时间了,如果说《去月球》是互动故事(2D),那么《艾迪芬奇的记忆》称为是交互式电影(3D)。整体的游玩体验感觉非常的好。以下内容主要来自ChatGPT。 《艾迪芬奇的记忆》的游戏…

在Python中,解析命令行参数的方法有多种,以下是一些常用的方法: sys.argv 使用 sys.argv 是解析命令行参数的最基本方法之一。sys.argv 是一个列表,其中包含了从命令行传递给 Python 脚本的参数。列表的第一个…

企业微信的群组支持给群组添加群机器人,添加完群机器人后就可以使用群机器人在群内同步消息。群机器人创建者可以在机器人详情页看到该机器人特有的 webhook url。开发者可以向这个地址发起 HTTP POST 请求,即可实…

StarRocks简介 StarRocks是一个高性能的分布式关系型数据库,专为在线分析处理(OLAP)场景而设计。它起源于Apache Doris项目,并在此基础上进行了大量优化和改进。 StarRocks的存储引擎 StarRocks主要设计为一款…
