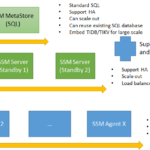
SSM(Smart Storage Manager)简介 SSM(Smart Storage Manager)是一个由 Intel 开源的 HDFS 存储管理系统,致力于提供 HDFS 数据的智能管理方案。 SSM 的核心功能 SSM 的核心功能主要围绕数据的智能管理展开,…
Snakemake简介 Snakemake是一个用于创建可重现和可扩展的数据分析管道的工作流管理系统。它广泛应用于生物信息学、数据科学和科学研究领域,帮助用户自动化和管理复杂的数据处理任务。Snakemake的设计灵感来自GNU M…
sling-cli 是一个由 SlingDataIO 开发的命令行界面工具,旨在提供便捷的数据操作和管理功能。 sling-cli 简介 项目背景与目的 SlingDataIO 专注于数据集成和数据处理解决方案,sling-cli 是其推出的一款用于简…
Trino简介 Trino(原名PrestoSQL)是一个开源的分布式SQL查询引擎,设计用于对各种数据源进行高速查询。Trino的设计初衷是为了解决大规模数据分析的需求,能够在数据湖、数据仓库和其他数据存储系统上进行交互式分…

Traceback 是在 Python 中与经常遇到,特别是当你代码中有错误时,执行时会返回 Traceback 信息。在学习 Traceback 时,可以一起学习下 trace, tracemalloc。 trace, tracemalloc, 和 traceback 都是 Python 标…

MDX/MDD 文件格式简介 MDX 和 MDD 是字典程序 MDict 使用的文件格式,其中 MDX 文件用于存放定义,而 MDD 用于存放其他资源文件,比如图片,发音,虽然存放的内容是不一样的,但是两种文件的结构是一致的。 MDX 和…

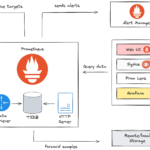
Prometheus简介 Prometheus是一个开源的系统监控和报警工具包,最初由SoundCloud开发,并在2012年作为开源项目发布。它现已成为云原生计算基金会(CNCF)的一部分,并且在监控领域获得了广泛的使用。Prometheus以其…
Prefect简介 Prefect是一个现代的工作流编排和管理工具,专为数据工程和数据科学任务设计。它提供了一种简单而强大的方式来定义、执行和监控数据管道。Prefect的设计目标是提高数据管道的可靠性、可扩展性和易用性…
Pinot 简介 Apache Pinot 是一个实时分布式 OLAP 数据存储和分析系统,专为低延迟、高吞吐量的查询而设计。Pinot 最初由 LinkedIn 开发,用于支持其内部的分析应用,如 LinkedIn 的 "Who Viewed My Profile" 和其他…
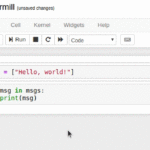
Papermill简介 Papermill是一个开源工具,主要用于在数据科学和数据工程工作流程中处理 Jupyter Notebook。它的核心功能是允许用户对 Jupyter Notebook 进行参数化执行,使得同一个 Notebook 可以在不同的参数配置…