A priori 简介
集体智慧(Collective Intelligence)
单一个体所做出的决策往往会比起多数决的决策来的不精准,集体智慧是一种共享的或者群体的智能,以及集结众人的意见进而转化为决策的一种过程。它是从许多个体的合作与竞争中涌现出来的。通常含义为:为了创造新的想法而将一群人的行为、偏好或思想组合在一起,从独立的数据提供者(用户)中总结规律、经验从而得到新的结论。随着通信技术的发展,互联网重构了知识体系,让每一个用户在享受知识的同时,也在默默贡献着知识。信息的价值不由任何一个个体所决定,而是由群体的行为来确定的。
关联规则( Association rule )
关联规则分析也称为购物篮分析,最早是为了发现超市销售数据库中不同的商品之间的关联关系。关联规则是反映一个事物与其他事物之间的关联性,若多个事物之间存在着某种关联关系,那么其中的一个事物就能通过其他事物预测到。例如,从销售数据中发现的规则{洋葱,土豆}→{汉堡}会表明如果顾客一起买洋葱和土豆,他们也有可能买汉堡的肉。此类信息可以作为做出促销定价或产品植入等营销活动决定的根据。除了上面购物篮分析中的例子以外,关联规则如今还被用在许多应用领域中,包括网络用法挖掘、入侵检测、连续生产及生物信息学中。与序列挖掘相比,关联规则学习通常不考虑在事务中、或事务间的项目的顺序。
频繁项集 ( Frequent Itemset )
经常一起出现的item集合称为频繁项集。常用的频繁项集的评估标准有支持度、置信度和提升度:
支持度
支持度就是几个关联的数据在数据集中出现的次数占总数据集的比重。或者说几个数据关联出现的概率。如果我们有两个想分析关联性的数据X和Y,则对应的支持度为:
$$Support(X,Y)=P(XY)=\frac{number(XY)}{number(AllSamples)}$$
以此类推,如果我们有三个想分析关联性的数据X,Y和Z,则对应的支持度为:
$$Support(X,Y,Z)=P(XYZ)=\frac{number(XYZ)}{number(AllSamples)}$$
一般来说,支持度高的数据不一定构成频繁项集,但是支持度太低的数据肯定不构成频繁项集。
置信度
置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。如果我们有两个想分析关联性的数据X和Y,X对Y的置信度为:
$$Confidence(X\Leftarrow Y)=P(X|Y)=\frac{P(XY)}{P(Y)}$$
也可以以此类推到多个数据的关联置信度,比如对于三个数据X,Y,Z,则X对于Y和Z的置信度为:
$$Confidence(X\Leftarrow YZ)=P(X|YZ)=\frac{P(XYZ)}{P(YZ)}$$
提升度
提升度表示含有Y的条件下,同时含有X的概率,与X总体发生的概率之比,即:
$$Lift(X\Leftarrow Y)=\frac{P(X|Y)}{P(X)}=\frac{Confidence(X\Leftarrow Y)}{P(X)}$$
提升度体先了X和Y之间的关联关系,提升度大于1则$X\Leftarrow Y$是有效的强关联规则,提升度小于等于1则$X\Leftarrow Y$是无效的强关联规则。一个特殊的情况,如果X和Y独立,则有$Lift(X\Leftarrow Y)=1$,因为此时$P(X|Y)=P(X)$。
支持度和可信度是用来量化关联分析是否成功的方法。关联分析的目的包括两个:发现频繁项集和发现关联规则。首先我们要找到频繁项集,然后根据频繁项集找出关联规则。一般来说,要选择一个数据集合中的频繁数据集,则需要自定义评估标准。最常用的评估标准是用自定义的支持度,或者是自定义支持度和置信度的一个组合。
Apriori算法简介
支持度和可信度是用来量化关联分析是否成功的一个方法。假设想找到支持度大于0.8的所有项集,应该如何去做呢?一个办法是生成一个物品所有可能组合的清单,然后对每一种组合统计它出现的频繁程度。确实可以通过遍历所有组合就能找出所有频繁项集,但问题是遍历所有组合花的时间太多,效率太低,假设有N个物品,那么一共需要计算$2^N-1$次。每增加一个物品,数量级是成指数增长。而Apriori就是一种找出频繁项集的高效算法。了解Apriori算法推导之前,我们先介绍一些基本概念:
- K项集(K-itemset):同时购买的K项集合。
- 频繁K项集(frequent itemset):满足最小支持度阈值的K项集合。
- 候选K项集(candidate itemset):通过连接形成的K项集合。
Apriori的核心就是下面这句话:某个项集是频繁的,那么它的所有子集也是频繁的。这句话看起来是没什么用,但是反过来就很有用了。如果一个项集是非频繁项集,那么它的所有超集也是非频繁项集。
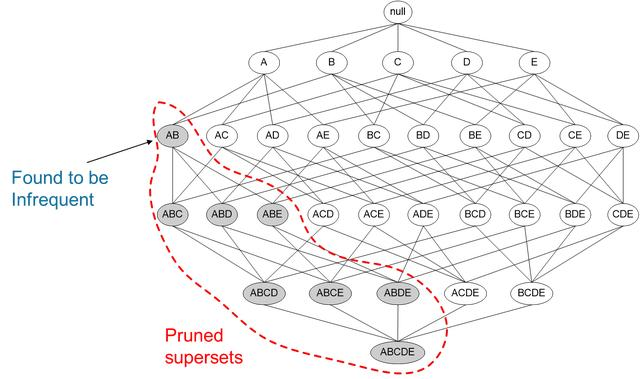
如图所示,我们发现{A,B}这个项集是非频繁的,那么{A,B}这个项集的超集,{A,B,C},{A,B,D}等等也都是非频繁的,这些就都可以忽略不去计算。运用Apriori算法的思想,我们就能去掉很多非频繁的项集,大大简化计算量。
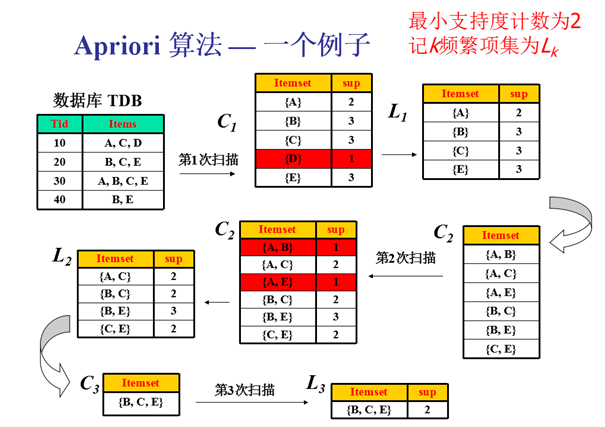
Apriori算法是经典的挖掘频繁项集和关联规则的数据挖掘算法。Apriori在拉丁语中指”来自以前”。当定义问题时,通常会使用先验知识或者假设,这被称作”一个先验”(apriori)。Apriori算法的名字正是基于这样的事实:算法使用频繁项集性质的先验性质,即频繁项集的所有非空子集也一定是频繁的。Apriori算法使用一种称为逐层搜索的迭代方法,其中k项集用于探索(k+1)项集。首先,通过扫描数据库,累计每个项的计数,并收集满足最小支持度的项,找出频繁1项集的集合。该集合记为L1。然后,使用L1找出频繁2项集的集合L2,使用L2找出L3,如此下去,直到不能再找到频繁k项集。每找出一个Lk需要一次数据库的完整扫描。Apriori算法使用频繁项集的先验性质来压缩搜索空间,其核心思想是通过连接产生候选项及其支持度,然后通过剪枝生成频繁项集。。与朴素贝叶斯分类器一样都是用到先验知识,但是贝叶斯是多个概率推断True/False,关联规则是解决A→Who的问题。
Apriori 的优点:
- 适合稀疏数据集。
- 算法原理简单,易实现。
- 适合事务数据库的关联规则挖掘。
- 易编码实现
Apriori的 缺点 :
- 可能产生庞大的候选集。
- 算法需多次遍历数据集,算法效率低,耗时。
- 在大数据集上可能较慢
Apriori算法能够有效发现频繁项集并获取关联规则,但是每次计算频繁项集的支持度(主要是指:项集所构成的超集的支持度)都要遍历整个数据库,因此造成过多的时间开销,无法高效处理大规模数据集。为了克服Apriori算法这一缺点,包括FP-Growth等算法应运而生,FP-Growth算法则需扫描原始数据两遍,通过FP-tree数据结构对原始数据进行压缩,效率较高。现在一般很少直接用Aprior算法来挖掘数据了,但是理解Aprior算法是理解其它Aprior类算法的前提,同时算法本身也不复杂,因此值得好好研究一番。
Apriori代码实现
#-*- coding: utf8 -*-
def load_data_set():
"""加载数据集"""
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
def create_C1(data_set):
"""创建集合C1。即对data_set进行去重,排序,放入list中,然后转换所有的元素为frozenset"""
C1 = []
for transaction in data_set:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return map(frozenset, C1) # frozenset表示冻结的set集合,元素无改变;可以把它当字典的key来使用
def scan_D(D, Ck, min_support):
"""计算候选数据集Ck在数据集D中的支持度,并返回支持度大于最小支持度(min_support)的数据
Args:
D 数据集
Ck 候选项集列表
min_support 最小支持度
Returns:
ret_list 支持度大于min_support的集合
support_data 候选项集支持度数据
"""
ss_cnt = {} # ssCnt临时存放选数据集Ck的频率.例如:a->10,b->5,c->8
for tid in D:
for can in Ck:
if can.issubset(tid):
if can not in ss_cnt:
ss_cnt[can] = 1
else:
ss_cnt[can] += 1
num_items = float(len(D)) # 数据集D的数量
ret_list = []
support_data = {}
for key in ss_cnt:
support = ss_cnt[key] / num_items # 支持度=候选项(key)出现的次数/所有数据集的数量
if support >= min_support:
ret_list.insert(0, key) # 在retList的首位插入元素,只存储支持度满足频繁项集的值
support_data[key] = support # 存储所有的候选项(key)和对应的支持度(support)
return ret_list, support_data
def apriori_gen(Lk, k):
"""aprioriGen(输入频繁项集列表Lk与返回的元素个数k,然后输出候选项集Ck。
例如:以{0},{1},{2}为输入且k=2则输出{0,1},{0,2},{1,2}.以{0,1},{0,2},{1,2}为输入且k=3则输出{0,1,2}
Args:
Lk 频繁项集列表
k 返回的项集元素个数(若元素的前k-2相同,就进行合并)
Returns:
ret_list 元素两两合并的数据集
"""
ret_list = []
len_Lk = len(Lk)
for i in range(len_Lk):
for j in range(i + 1, len_Lk):
L1 = list(Lk[i])[:k - 2]
L2 = list(Lk[j])[:k - 2]
L1.sort()
L2.sort()
if L1 == L2: # 第一次L1,L2为空,元素直接进行合并,返回元素两两合并的数据集
ret_list.append(Lk[i] | Lk[j])
return ret_list
def apriori(data_set, min_support=0.5):
"""找出数据集data_set中支持度>=最小支持度的候选项集以及它们的支持度。即我们的频繁项集。
Args:
data_set 原始数据集
min_support 支持度的阈值
Returns:
L 频繁项集的全集
support_data 所有元素和支持度的全集
"""
C1 = create_C1(data_set) # C1即对data_set进行去重,排序,放入list中,然后转换所有的元素为frozenset
D = list(map(set, data_set)) # 对每一行进行set转换,然后存放到集合中
L1, support_data = scan_D(D, C1, min_support) # 计算候选数据集C1在数据集D中的支持度,并返回支持度大于min_support的数据
L = [L1] # L加了一层list,L一共2层list
k = 2
while (len(L[k - 2]) > 0): # 判断L的第k-2项的数据长度是否>0。
Ck = apriori_gen(L[k - 2], k)
Lk, supK = scan_D(D, Ck, min_support) # 计算候选数据集CK在数据集D中的支持度,并返回支持度大于min_support的数据
support_data.update(supK) # 保存所有候选项集的支持度,如果字典没有,就追加元素,如果有,就更新元素
if len(Lk) == 0:
break
L.append(Lk) # Lk表示满足频繁子项的集合,L元素在增加,
k += 1
return L, support_data
def calc_conf(freq_set, H, support_data, brl, min_conf=0.7):
"""计算可信度(confidence)
Args:
freq_set 频繁项集中的元素,例如: frozenset([1, 3])
H 频繁项集中的元素的集合,例如: [frozenset([1]), frozenset([3])]
support_data 所有元素的支持度的字典
brl 关联规则列表的空数组
min_conf 最小可信度
Returns:
pruned_H 记录可信度大于阈值的集合
"""
pruned_H = [] # 记录可信度大于最小可信度(minConf)的集合
for conseq in H:
conf = support_data[freq_set] / support_data[freq_set - conseq]
if conf >= min_conf:
brl.append((freq_set - conseq, conseq, conf))
pruned_H.append(conseq)
return pruned_H
def rules_from_conseq(freq_set, H, support_data, brl, min_conf=0.7):
"""递归计算频繁项集的规则
Args:
freq_set 频繁项集中的元素,例如: frozenset([2, 3, 5])
H 频繁项集中的元素的集合,例如: [frozenset([2]), frozenset([3]), frozenset([5])]
support_data 所有元素的支持度的字典
brl 关联规则列表的数组
min_conf 最小可信度
"""
m = len(H[0]) # H[0]是freq_set的元素组合的第一个元素,并且H中所有元素的长度都一样,长度由apriori_gen(H, m+1)这里的m+1来控制
if len(freq_set) > (m + 1):
Hmp1 = apriori_gen(H, m + 1) # 生成m+1个长度的所有可能的H中的组合
Hmp1 = calc_conf(freq_set, Hmp1, support_data, brl, min_conf) # 返回可信度大于最小可信度的集合
print('Hmp1=', Hmp1)
print('len(Hmp1)=', len(Hmp1), 'len(freqSet)=', len(freq_set))
if len(Hmp1) > 1: # 计算可信度后,还有数据大于最小可信度的话,那么继续递归调用,否则跳出递归
rules_from_conseq(freq_set, Hmp1, support_data, brl, min_conf)
def generate_rules(L, support_data, min_conf=0.7):
"""生成关联规则
Args:
L 频繁项集列表
support_data 频繁项集支持度的字典
min_conf 最小置信度
Returns:
big_rule_list 可信度规则列表(关于(A->B+置信度)3个字段的组合)
"""
big_rule_list = []
for i in range(1, len(L)):
for freq_set in L[i]:
H1 = [frozenset([item]) for item in freq_set]
if (i > 1): # 2个的组合,走else, 2个以上的组合,走if
rules_from_conseq(freq_set, H1, support_data, big_rule_list, min_conf)
else:
calc_conf(freq_set, H1, support_data, big_rule_list, min_conf)
return big_rule_list
def test_apriori():
data_set = load_data_set()
L1, support_data1 = apriori(data_set, min_support=0.7)
print('L(0.7):', L1)print('support_data(0.7):', support_data1)
L2, support_data2 = apriori(data_set, min_support=0.5)
print('L(0.5):', L2)
print('support_data(0.5):', support_data2)
def test_gnerate_rules():
# 加载测试数据集
data_set = load_data_set()
L1, support_data1 = apriori(data_set, min_support=0.5)
print('L(0.7):', L1)
print('support_data(0.7):', support_data1)
# 生成关联规则
rules = generate_rules(L1, support_data1, min_conf=0.5)
print('rules:', rules)
if __name__ == "__main__":
# 测试Apriori算法
test_apriori()
# 生成关联规则
test_gnerate_rules()
其他实现方式:MLxtend包的使用。
参考链接:


