阿里巴巴的日志采集体系方案客户端埋点,插件/封装,服务端部署。
- JS是Web端(基于浏览器)日志采集技术方案
- UserTrack是APP端(无线客户端)日志采集技术方案,是采集并上报App日志的sdk,适用于native原生页面、webview相关业务。
Web日志采集Aplus.JS
A+, APlus, 是基于Acookie和Atpanel日志整合而成的日志系统,A代表(Alibaba、Acookie、Atpanel),plus代表相加、整合之意。Aplus采集的内容:
- 当前页URL、标题和来源页的URL(如果有)
- 用户身份识别信息: cookieID,淘宝会员数字id(不一定需要登录)和nickname(若已登录)
- 客户端/浏览器信息和屏幕分辨率
- 当前页SPM,来源页点击位置SPM编码,来源页的来源页点击位置SPM编码(前提均为若已部署了SPM)
- aplus版本信息及反作弊验证码
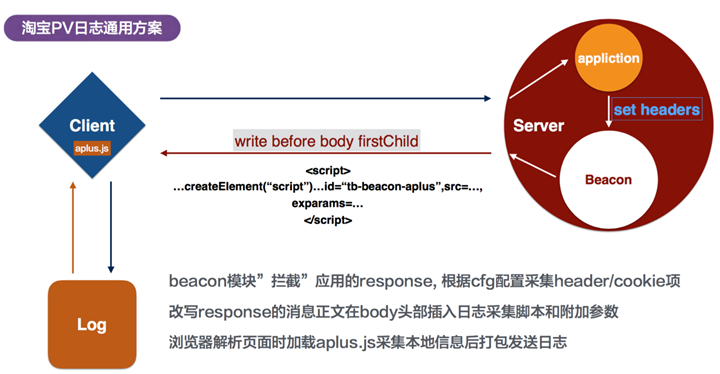
页面访问日志
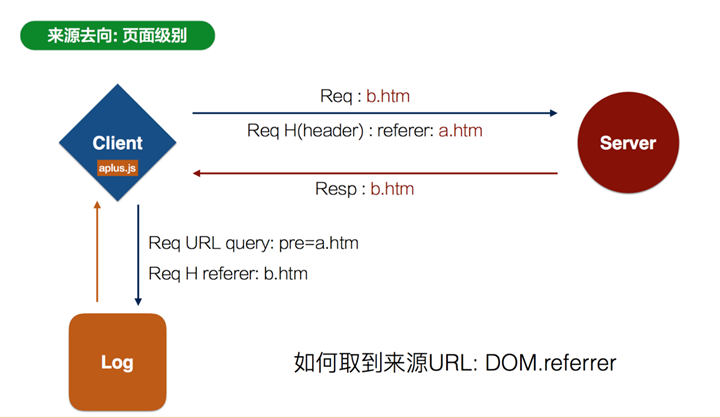
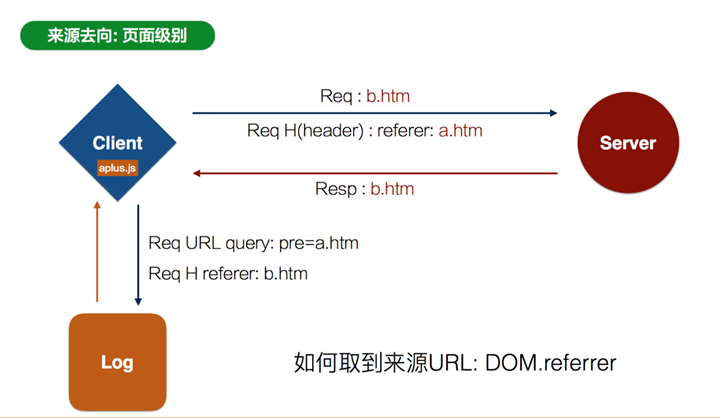
每个页面装载head部分的时候,下载一个js,这个js将发送一个请求到日志服务器,请求中包含了同步在淘宝cookie的本地cookie信息,也包含了refer/url/要获取的header参数/session的信息,由此完成pv/uv的默认计算。url中包含spm信息,可以完成页面来源去向的计算。
页面来源去向
页面交互日志
当页面加载和渲染完成之后,用户可以在页面上执行各类操作。随着互联网前端技术的不断发展,用户可在浏览器内与网页进行的互动已经丰富到只有想不到没有做不到的程度,互动设计都要求采集用户的互动行为数据,以便通过量化获知用户的兴趣点或者体验优化点。交互日志采集就是为此类业务场景而生的。
交互日志呈现高度自定义的业务特征(例如活动页面的游戏交互和购物车页面的功能交互两者截然不同)。在阿里巴巴,通过“黄金令箭”的采集方案来解决交互日志的采集问题。黄金令箭的步骤:配置元数据->业务方把交互日志采集代码植入目标页面,并将采集代码与需要监测的交互行为做绑定->当用户在页面上产生交互行为时,采集代码触发执行。
黄金令箭
goldlog.record()接口定义如下: void record(logkey, gmkey, gokey, chksum)
各参数含义及入参格式如下:
- logkey {String}:以/开头的字符串,如上例中的”/52taobao.chongzhi.myclick”
- gmkey {String}:关键业务类型.目前的约定的元值有五个
- 如果请求是点击类操作触发的,请传入”CLK”
- 如果请求是元素曝光类事件触发的,请传入”EXP”
- 如果请求是滑动滑屏类事件触发的,请传入”SLD”
- 如果是其它事件,请传入”OTHER”
- 本参数可以为空值,但不建议留空.此值为空的请求将在日志流量大时被优先降级
- gokey {String}:附加的自定义kv对
- key=value形式,不同的键值对之间使用&分隔,如click_type=chongzhi&fee=200
- 如果key或value中有特殊字符,需要先使用encodeURLComponent编码
- chksum {String}:校验码。如果此串错误或留空,将无法发送请求。校验码可以从黄金令箭申请中心拿到
无线客户端的日志采集UserTrack
UserTrack是阿里巴巴集团内部采集并上报App日志的sdk,适用于native原生页面、webview相关业务。UserTrack SDK目前提供iOS、Android、mini平台版本,并且合并了业务埋点&性能埋点。提供几类事件API给客户端开发调用,实现埋点。
无线客户端的日志采集和浏览器的日志采集方式有所不同,移动端的日志采集根据不同的用户行为分成不同的事件,“事件”为无线客户端日志行为的最小单位。基于常规的分析,UserTrack(UT)把事件分成了几类,常用的包括页面事件(同前述的页面浏览)和控件点击事件(同前述的页面交互)等。对事件进行分类的原因,除了不同事件的日志触发时机、日志内容和实现方式有差异之外,另一方面是为了更好地完成数据分析。在常见的业务分析中,往往较多地涉及某类事件,而非全部事件;故为了降低后续处理的复杂性,对事件进行分类尤为重要。要更好地进行日志数据分析,涉及很多方面的内容,如需要处理Hybrid应用,实现H5和Native日志的统一;又如识别设备,保证同一设备上各应用获取到的设备信息是唯一的。除此之外,对于采集到的数据如何上传,以及后续又如何合理处理等,每个过程都值得我们进行深入的研究和探索。
UserTrack将采集以下数据
- 采集设备信息(设备、运营商……)
- 采集APP信息(应用、版本、渠道……)
- 采集用户行为(会员、登陆、注册、页面浏览、控件点击……)
UserTrack会为每种业务事件分配一个事件ID(event_id),通过event_id来区分每条日志的业务含义,例如常见的页面事件(event_id=2001)、控件事件(event_id=2101)等。开发人员可以根据不同的业务场景调用不同的API埋点,为不同的业务事件提供不同的业务参数。
页面事件
阿里巴巴提供了对页面事件的无痕埋点,即无须开发者进行任何编码即可实现。对于手动方式埋点,UT提供了两个接口分别用于页面展现和页面退出时调用(这样可以得到停留时长),还提供了添加页面扩展信息的接口。
为了节约计算和分析的成本,UT提供了透传参数功能:把当前页面的某些信息,传递到下一个页面,甚至下下个页面的日志中。可以使用阿里SPM超级位置模型来进行来源去向的追踪。
控件点击事件
和浏览器客户端的日志采集一样,交互日志也呈现出高度自定义的业务特征。记录了:基本的设备信息、用户信息、控件所在页面名称、控件名称和控件的业务参数。
UserTrack会为每种业务事件分配一个事件ID(event_id), 通过event_id来区分每条日志的业务含义,例如常见的页面事件(event_id=2001)、控件事件(event_id=2101)等。开发人员可以根据不同的业务场景调用不同的API埋点,为不同的业务事件提供不同的业务参数。
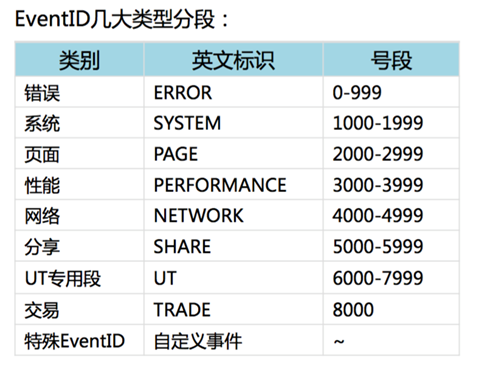
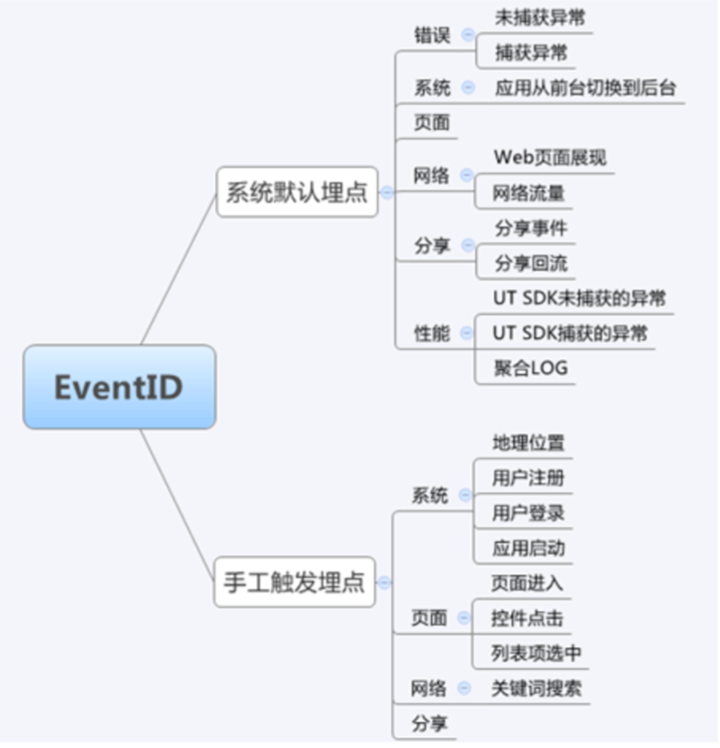
常用UT事件:
| EventID | 用途 | 是否需要埋点语句 | page | arg1 | arg2 | arg3 | args | 备注 |
| 1 | 未捕获异常 | 否 | UT | 异常的md5 | 异常名称 | – | 异常信息 | 猫客关掉了 UT 的异常捕获 |
| 1001 | 应用安装成功 | 猫客未使用 | ||||||
| 1002 | 应用第一次启动 | Page_UsertrackInit | binTime, serialNo, dep | 数据较少 | ||||
| 1003 | 应用启动 | 猫客未使用 | ||||||
| 1004 | 应用退出 | 猫客未使用 | ||||||
| 1005 | 地理位置 | 猫客未使用 | ||||||
| 1006 | 用户注册 | 是 | UT | nickname | – | – | – | – |
| 1007 | 用户登录 | 是 | UT | nickname | unknown | – | – | 猫客登录时会发送两次 |
| 1008 | 用户登出 | 猫客未使用 | ||||||
| 1009 | 应用从后台切换到前台 | 否 | Page_UsertrackInit | dep | 数据较少 | |||
| 1010 | 应用从前台切换到后台 | 否 | 当前页面 | 本次在前台运行的总时间 | – | – | _as | – |
| 2001 | 页面离开 | 是 | 当前页面 | 上一个页面 | – | 停留时长 | – | – |
| 2101 | 控件点击 | 是 | 当前页面 | 控件名 | – | – | 业务参数 | – |
| 2201 | 曝光事件 | 是 | 当前页面 | 控件名 | – | 无(或曝光时长) | 业务参数 | ViewTracker SDK 支持的曝光事件 arg3 为时长,args 中 exposureIndex 为曝光次数 |
| 2202 | 资源币曝光 | 是 | 当前页面 | 控件名 | unknown | unknown | unknown | – |
| 5002 | 分享 | 是 | Page_share | bizName | 分享途径 | 分享链接 | – | – |
| 5004 | 回流 | 是 | Page_Extend | url(tmall://) | – | – | – | – |
| 9001 | 钻展 | 是 | Page_Extend | – | – | – | 业务参数 | – |
| 9001 | 钻展 | 是 | Page_Extend | – | – | – | 业务参数 | – |
| 19999 | 自定义事件 | 是 | UT | 注册事件名 | unknown | unknown | unknown | – |
UT 日志格式介绍
| Field | Type | Comment |
| app_id | string | 以 app_key@os 的形式存在,如果 os 为安卓系统,则表示为:app_key@android,如果 os 为 ios,device_model=‘iPad’,则表示为:app_key@ipad,如果 os 为 ios,device_model<>‘iPad’,则表示为:app_key@iphoneos,如果 os 为 WindowsPhone,则表示为:app_key@wp,如果 os 为 aliyunos,则表示为:app_key@aliyunos |
| app_name | string | app_id 对应的 app 中文名称 |
| app_version | string | app 的应用版本号 |
| sdk_version | string | usertracksdk 的版本号 |
| channel | string | app 对应的渠道号,映射表为 wireless_wdm.wdm_dim_channel |
| channel_name | string | channel 对应的渠道名称 |
| imei | string | 移动设备国际身份码的缩写 |
| imsi | string | 国际移动用户识别码(IMSI:International Mobile Subscriber Identification Number)是区别移动用户的标志,储存在 SIM 卡中 |
| reserves_id | string | 预留备用 id,对应老日志表中的 device_id |
| uvmid | string | 经过不同的设备信息,计算出来设备唯一 id,下游用户可直接根据此字段作为设备 id 来进行计算,此字段对应老日志表的 imeisi 列 | string | 长登录nick |
| taobao_user_id | bigint | 长登录user_id(主要指淘宝账号体系的user_id),通过long_login_nick和用户表关联 |
| account_id | string | 长登录user_id(包含非淘宝账号体系,例如快的) |
| is_short_logon | string | 是否主动登陆(短登陆),1:是,0:否,此字段结合long_login_nick字段,可以还原出短登陆id |
| brand | string | 手机或终端的品牌 |
| device_model | string | 手机或终端的机型 |
| resolution | string | 手机或终端的屏幕分辨率 |
| os | string | 操作系统,如:Android、iPhoneOS |
| os_version | string | 操作系统的版本 |
| carrier | string | 移动运营商,如:中国移动、中国联通、中国电信 |
| access | string | 连接的网络,如:2G、3G、Wi-Fi |
| access_subtype | string | 网络类型,如:HSPA、EVDO、EDGE、GPRS等 |
| network_type | string | 根据access,acess_subtype转化后的网络类型,例如3G,4G,Wi-Fi等 |
| client_ip | string | 客户端ip |
| session_id | string | 用户的一次会话id |
| utdid | string | usertrackdevice_id,由SDK生成的设备标识 |
| reserve3 | string | 预留字段 |
| reserve4 | string | 预留字段 |
| reserve5 | string | 预留字段 |
| reserves | string | 预留字段 |
| reach_time | string | 到达日志服务器的时间,此时间可作为日志时间直接使用,格式为:yyyyMMddHHmmss |
| page | string | 页面 |
| event_id | string | 埋点的事件ID |
| arg1 | string | 事件参数,对于2001事件,值为上一页面名称,对于2101事件,值为控件名称 |
| arg2 | string | 事件参数 |
| arg3 | string | 事件参数 |
| args | string | 事件参数 |
| is_active | bigint | 是否活跃用户,1:是;0:否。可以用判断条件is_active=1来判断活跃用户。注:本字段仅为行级标志 |
| auction_id | bigint | 通过args解析出来的商品id |
| start_count | bigint | 根据event_id=1010解析而出,1:启动次数;0:非启动次数。后续计算启动次数直接sum此字段即可 |
| run_time | double | 根据event_id=1010解析而出,单位:秒。如果为非时长,记为0。后续计算使用时长直接sum此字段即可 |
| country | string | 根据client_ip解析出的国家或地区,如:中国、香港、台湾、美国 |
| province | string | 根据client_ip解析出的省、直辖市、自治区,如:浙江省、西藏自治区、上海市 |
| city | string | 根据client_ip解析出的地级市,如:武汉市、杭州市 |
| district | string | 根据client_ip解析出的区、县、县级市,如:西湖区、义乌市、桐庐县 |
| school | string | 根据client_ip如果为校园网解析出的学校,如:浙江大学、中国传媒大学 |
| active_uvmid | string | 计算活跃用户时,直接count(distinct active_uvmid)此字段即可 |
| active_user_nick | string | 计算活跃会员时,直接count(distinct active_user_nick)即可 |
| register_content | string | 计算注册用户直接取此字段,条件限制非空 |
| page_stay_time | double | 页面停留时长,单位为秒 |
| local_time | string | 终端时间(格式为yyyy-mm-dd hh24:mi:ss) |
| local_timestamp | string | 终端时间(格式为数字型的unix时间,精确到毫秒,可通过from_unixtime函数转换成日期) |
| protocol_version | string | sdk协议版本 |
| sdk_type | string | sdk类型 |
| search_keyword | string | 搜索关键字,根据args里面search_keyword=关键字解析出来 |
| seller_id | string | 卖家id,根据args里面seller_id=解析出来 |
| shop_id | bigint | 店铺id,根据args里面shop_id=解析出来 | string | 喜爱类型, 根据 args 里面 favorite_type= 解析出来 |
| order_id | bigint | 订单 id, 根据 args 里面 order_id= 解析出来 |
| longitude | double | 经度,根据 event_id=1005, args 里面 longitude= 解析出来 |
| latitude | double | 纬度,根据 event_id=1005, latitude= 解析出来 |
| idfa | string | ios 的广告标识符 |
| aid | string | 已经废弃,为空 |
| hour | string | 小时 |
| ds | string | 日期分区, 格式为 yyyymmdd |
| product | string | taobao: 手机淘宝的 app; tmall: 天猫的 app; jhs: 聚划算的 app; others: 不在上面几个分区里面的 app,都记入入此分区。 |
| event_type | string | page: 页面事件,对应 event_id in (2001, 2002); cntrl: 控件事件, 对应 event_id 2101-2200(不包含 2105); self_define: 自定义事件,对应 event_id=19999; crash: crash 事件,对应 event_id=1; others: 不在上面分区里面的事件都记入此分区。 |
UT 各事件依据 eventid 不同其 arg1、arg2、arg3、args 的含义各不相同。
完整格式(一条记录):version||imei||imsi||brand||cpu||device_id||device_model||resolution||carrier||access||access_subtype||channel||app_key||app_version||Long-LoginUsernick||usernick||phone_number||country||language||os||os_version||sdk_type||sdk_version||sessionID||UTDID||reserve3||reserve4||reserve5||reserves||recordDate||timestamp||page||eventid||arg1||arg2||arg3||args
以上,记录格式分为两个部分,会话信息和业务信息。
- 会话信息:相对稳定不变的信息。
- 基本的设备信息,如操作系统、操作系统版本、imei、imsi(或者 ios 的 idfa)、cpu、分辨率、网络制式、运营商等;
- 用户基本信息,如登陆昵称;
- 应用基本信息,如 app_key, app_version, 渠道 channel 等。
- 业务信息:业务相关的信息
UserTrack 高级功能
曝光日志预聚合
曝光日志,是电商场景下很特殊的一类日志,具体来说:比如商品图墙列表上有多少商品给用户展示过就是一种典型的曝光日志,一般用来作为推荐算法的输入信息或者广告展示计费用途。曝光日志一般是点击日志的几十到几百倍,而一页内的曝光信息又大致雷同,所以一般都会做聚合。
只是如何聚合,由客户端采集框架聚合还是由业务自身聚合(比如曝光日志设计为一条可以直接记录一批商品),这会是需要权衡考虑的。
回退识别
用户回退行为的识别,也是比较棘手的,因为跟踪用户浏览行为的目的,主要是为了分析链路转化率,用来优化业务或分析活动效果等。而页面回退行为对这些行为分析是一种干扰。在下游数据分析过程中再识别这种行为往往很难,在采集端会有更充分的信息进行识别。但具体实现也并不是总能万无一失,而且有些特殊情况下,可能还需要保留这种回退行为的数据。
UserTrack 其他功能
H5 和 native 日志统一
H5 越来越流行,Hybrid 的应用越来越普及,用户并不关心你的页面是 native 的还是 H5 的,但是日志的采集方案在 Web 端和 Native 端通常却是两套架构,后续采集传输流程等等很可能也不在一条链路上。如果不加处理,对于用户行为的链路分析会带来很大的麻烦。
具体怎么处理,不外乎是要自动识别 H5 页面的运行环境,打通 H5 跳转到 Native 和 Native 跳转到 H5 两个方向的页面数据传递,加上各种回退之类行为要处理,安卓和 IOS 的方案要兼容等等,真的实现起来,还是要费不少力气处理好各种细节的。
阿里巴巴选择将 H5 日志归到 Native 日志的方案:H5 页面浏览->触发 JS 脚本并搜集当前页面参数->JS 脚本将所采集的数据打包到一个对象中,然后调用 WebView 框架的 JSBridge 接口,调用移动客户端对应的接口方法,将埋点数据对象当作参数传入。
设备标识
对于登录用户,可以使用用 ID 进行唯一标识,但是很多日志行为并不要求用户登录,这就导致很多情况下采集上来的日志都没有用户 ID。阿里巴巴采用 UTDID 方案,但就目前的进展来说,UTDID 还未实现其使命。

日志处理链路
- 日志分流:日志分流:根据页面业务类型的不同,采用不同的 URL Log 记录地址,将分流工作从客户端开始做起。日志分流的目的,自然是为了增加日志链路水平拓展的能力,然后降低后续流程具体业务的计算代价,所以理论上来说,分流得越早,分流得越彻底,这方面的收益越高。
- 日志缓存:主要使用缓存部分日志先不发送,以及日志采样等。日志分流以后,当然可以做开关,缓存,采样等工作,这也是分流的收益之一。阿里现在日志的上传率是 98%,目前是国内上传率最高的公司。平时每天大概会有 4000 亿的日志上传,双十一期间会高达 6000 亿,这还是在减少一些通用型数据上传的情况下。在网络差的时候,阿里会把数据分包,如果还是上传会继续拆分,一直到 10k。如果还是上传不上去,就会采取其他技术手段。
采集规范与埋点流程
采集规范
- 闭环:无规范不分析,无分析不采集;采集必计算,计算必分析。
- 自下而上:在数据采集前,先定义了采集规范如 SPM(超级位置模块),SCM(超级内容模块),黄金令箭(交互采集模块),采集规则统一等。数据采集的支持平台有埋点申请,埋点配置,埋点验证,数据监控,数据管理。(这个就是埋码的流程。)
- 统一规则:各个产品线只有一套统一的数据监控规则。举一个天猫和淘宝在做产品曝光率分析的例子。比如在做智能推荐系统的时候,希望知道产品的曝光率。这时就需要对曝光制定一个规则–什么是曝光。如果淘宝把出现一点产品图片的边缘就算曝光,而天猫把出现了整个产品图片才叫曝光,那么这样的统计结果就有很大的差异。现在统一规定:一个产品图片露出 50% 的区域同时展示了 5 秒,就算一次曝光。
埋点流程
阿里的埋码流程如下:埋点申请,埋点配置,埋点验证,数据监控,采集管理
- 埋点申请:在平台上申请埋码,并记录埋点信息
- 埋点配置:埋码分为可视化自动埋码,和非可视化手动埋码
- 埋点验证:sdk 自动触发点击事件,和平台上提交的埋点信息做验证
- 数据监控:监控埋码质量
- 采集管理:采集数据管理


