文章内容如有错误或排版问题,请提交反馈,非常感谢!
在线旅游平台通过整合多个供应商的酒店资源,为用户提供一站式比价服务。酒店聚合能力直接影响用户体验:一方面需要确保信息准确,避免”到店无单”的风险;另一方面要保证信息的实时性,帮助用户快速决策。
业务挑战分析
- 准确性挑战。不同供应商对同一酒店的描述存在差异,容易出现聚合错误。例如用户选择A酒店,系统却错误聚合到B酒店,导致用户体验受损。
- 实时性挑战。随着接入的供应商数量增加,人工聚合方式处理速度慢、成本高,难以满足业务增长需求。
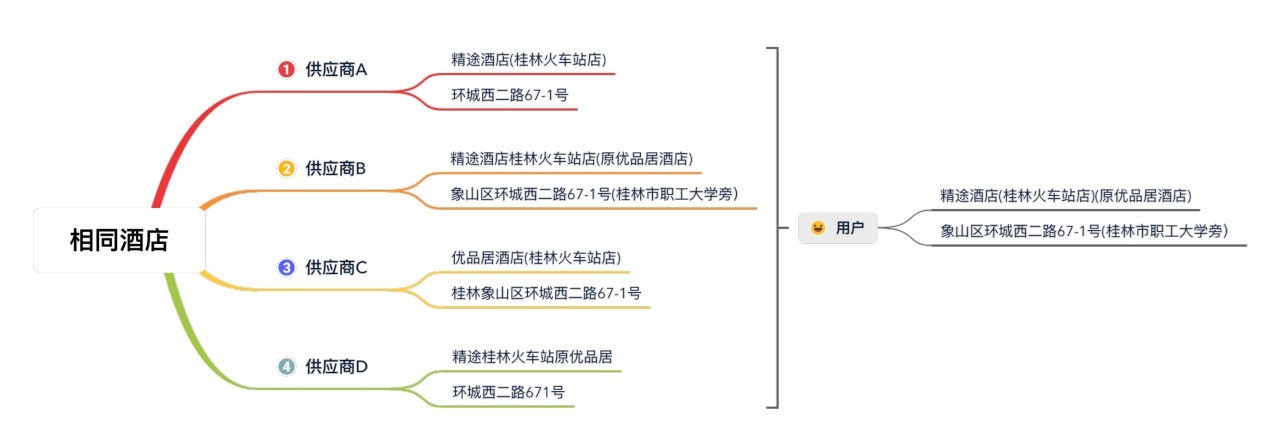
技术方案演进路径
初期方案:基于规则的相似度匹配
实现方式:
- 在5公里范围内搜索相似酒店
- 计算酒店名称、地址的整体余弦相似度
- 设定固定阈值进行匹配判断
局限性:
- 整体相似度计算粒度较粗
- 准确率仅95%,70%任务需人工处理
- 阈值设置依赖经验,灵活性差
机器学习驱动的新方案
数据预处理:精细化分词
分词词典构建:
- 采用统计方法分析海量酒店名称数据
- 自动识别高频出现的品牌词、类型词
- 结合人工筛查构建高质量分词词典
名称分词策略:
- 品牌词:如”希尔顿”、”如家”
- 核心词:如”酒店”、”度假村”
- 分店标识:如”北京店”、”机场店”
- 特色描述:如”温泉”、”海景”

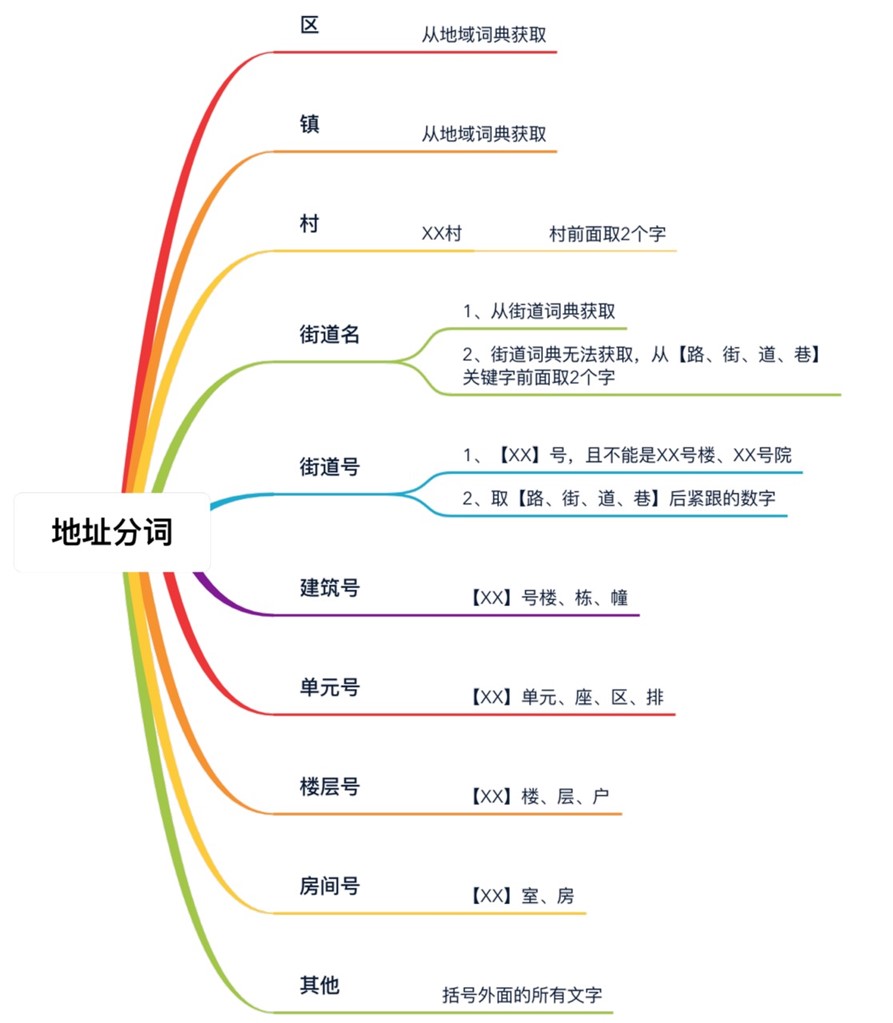
地址分词方案:
- 省市区行政区域划分
- 道路、门牌号详细信息
- 地标建筑参照物
- 区域特征描述
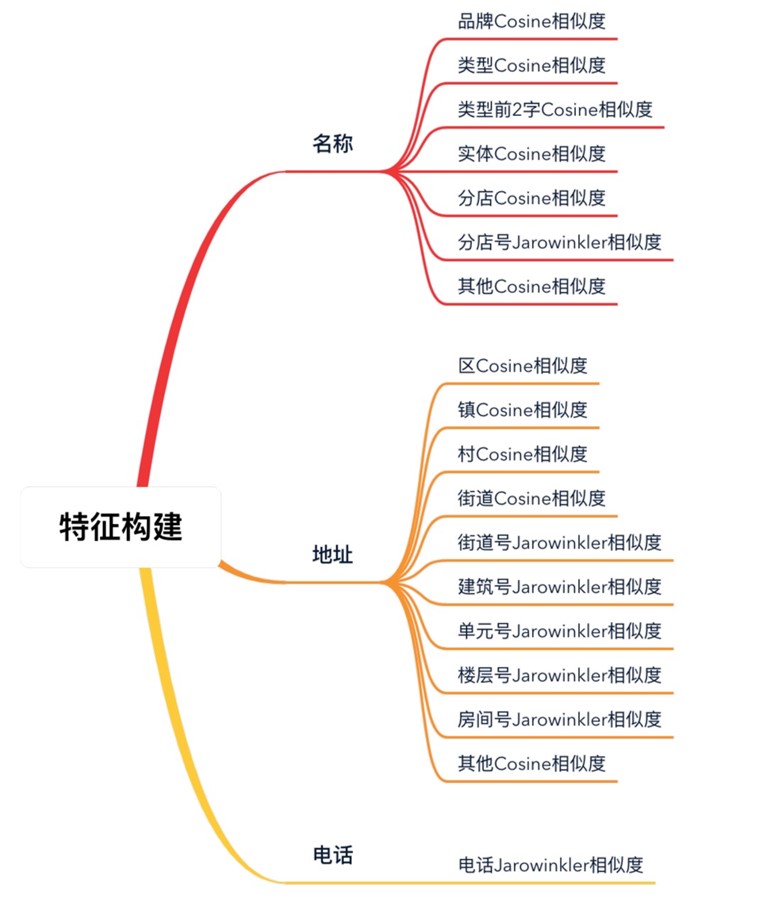
特征工程设计
基于分词结果构建20多个特征维度:
- 名称各字段相似度评分
- 地址组成部分匹配度
- 地理位置距离计算
- 联系方式一致性验证
模型选型与优化
算法选择:
- 使用LightGBM实现Gradient Boosting
- 相比XGBoost训练速度提升数倍
- 内存占用显著降低
实施方案与效果评估
模型训练策略
- 采用多轮迭代训练方式
- 持续进行特征优化
- 建立自动化的模型评估流程
效果验证指标
- 准确率:核心指标,严格控制错误聚合
- 召回率:在保证准确率前提下尽可能覆盖
多重保障机制
- 模型预测层:机器学习模型初步判断
- 规则校验层:基于业务规则二次验证
- 人工复核层:对高风险订单人工审核
技术方案整体架构
数据输入 → 特征提取 → 模型预测 → 结果校验 → 聚合输出
↓ ↓ ↓ ↓ ↓
酒店信息 分词处理 LightGBM 规则引擎 最终结果
经验总结与最佳实践
关键技术洞察
- 分词质量决定上限:精细化的分词策略是特征工程的基础
- 业务优先原则:在准确率与召回率间,优先保障准确率
- 迭代优化思路:通过持续的数据反馈优化模型效果
可复用的方法论
- 从规则系统到机器学习系统的平滑过渡方案
- 基于业务场景的特征工程设计方法
- 多层级的结果校验保障机制
未来优化方向
- 数据质量提升:统一坐标系统,提高位置特征准确性
- 系统协同优化:打通风控系统,建立数据闭环
- 技术扩展应用:适配国际酒店聚合场景
案例启示
本案例展示了传统业务场景通过机器学习技术实现智能化升级的完整路径。关键成功因素包括:深入的业务理解、合理的技术选型、严谨的效果评估以及稳健的落地策略。这种以解决实际业务问题为导向的技术实践,为类似场景提供了可借鉴的实施框架。
参考链接:


