Sentry简介
Sentry是一个流行的开源实时错误监控工具,主要用于应用程序的日志监控和错误跟踪。它能够帮助开发者快速识别、诊断和修复在生产环境中出现的问题。
以下是Sentry的一些主要特点和功能:
- 错误捕获和跟踪:
- Sentry可以自动捕获应用程序中的异常和错误,并提供详细的上下文信息,如堆栈跟踪、错误信息、用户信息和环境数据。
- 支持多种编程语言和框架,包括JavaScript、Python、Java、Ruby、PHP、js、Go等。
- 实时通知:
- 支持通过电子邮件、Slack、PagerDuty等多种渠道发送实时通知,确保开发团队能够在问题发生时立即得到警报。
- 问题聚合和去重:
- Sentry会自动对类似的错误进行聚合,避免重复报告相同的问题,帮助开发者更好地管理和优先处理问题。
- 丰富的上下文信息:
- 提供详细的错误上下文,包括请求数据、用户信息、设备信息等,帮助开发者更快地找到问题的根本原因。
- 版本控制集成:
- 可以与GitHub、GitLab、Bitbucket等版本控制系统集成,直接链接到相关的代码行,方便开发者快速定位和修复问题。
- 性能监控:
- 除了错误跟踪,Sentry还提供性能监控功能,帮助开发者识别应用程序中的性能瓶颈。
- 自定义过滤和规则:
- 支持自定义过滤规则和警报条件,开发者可以根据应用的需求调整监控策略。
- 易于集成:
- Sentry提供了丰富的SDK和插件,可以轻松集成到各种应用程序中。
- 开源和商业版本:
- Sentry提供开源版本,用户可以自行部署;同时也提供托管的商业版本,提供额外的功能和支持服务。
Sentry的商业托管服务
Sentry的收费模式通常基于其提供的功能和使用量,具体的定价可能会随着时间的推移而有所变化。一般来说,Sentry提供多种定价计划,以适应不同规模和需求的团队。以下是一些常见的收费模式和定价计划:
- 免费计划:Sentry通常提供一个免费计划,适合个人开发者或小型项目使用。免费计划通常包括基本的错误跟踪和性能监控功能,但可能对事件数量和数据保留时间有所限制。
- 团队计划:适用于小型到中型团队。团队计划通常包括更高的事件配额、更长的数据保留时间以及一些高级功能,比如团队协作工具、基本的性能监控等。
- 商业计划:面向大型企业和高需求团队,商业计划通常提供无限制的事件数量、更长的数据保留时间和更高级的功能,如高级性能监控、专用支持、SAML SSO(单点登录)等。
- 自定义计划:对于有特定需求的企业,Sentry可能提供定制化的计划。客户可以根据自身需求与Sentry团队协商,制定符合其业务需求的定价和功能组合。
计费方式
- 事件数量:许多定价计划基于每月的事件数量。超过计划内的事件数量可能需要额外付费。
- 数据保留时间:不同的计划提供不同的数据保留时间,数据保留时间越长,价格可能越高。
- 用户数量:某些计划可能根据使用Sentry的用户数量进行计费。
其他费用
- 高级功能:某些高级功能可能需要额外付费,如更高级的性能监控、专用支持服务等。
- 支持和服务:企业级计划通常提供高级支持选项,可能需要额外的费用。
Sentry的私有化部署
Sentry提供了私有化部署的选项,使得企业可以在自己的基础设施上运行Sentry,以满足特定的安全、合规和性能需求。这种部署方式特别适合需要更高数据控制和隐私保护的组织。以下是关于Sentry私有化部署的一些详细信息:
私有化部署的优势
- 数据控制:企业可以完全控制数据的存储和处理方式,确保敏感信息不离开内部网络。
- 安全性:通过在受控环境中运行Sentry,可以实施更严格的安全措施,如网络隔离、访问控制和自定义安全策略。
- 合规性:满足特定行业或地区的合规要求,例如GDPR、HIPAA等,通过自托管来确保符合相关法规。
- 性能优化:根据自身的基础设施和需求,优化Sentry的性能,包括调整资源分配、缩短数据传输延迟等。
- 自定义功能:可以根据业务需求自定义Sentry的功能和配置,以更好地集成到现有的IT生态系统中。
Sentry架构概述

- Load balancer(负载均衡器)负责路由转发(这一服务由用户搭建),错误上报转发到api+store,其他项目、成员、错误管理功能由Sentry Web负责。这一层的承担数据入口、展示的作用
- Relay负责消息中继转发,并把数据先汇集到Kafka;Snuba负责接收Sentry Web的请求,进行数据的聚合、搜索;Sentry Worker则是一个队列服务,主要负责数据的存储。
- Kafka作为消息队列,ClickHouse负责接近实时的数据分析,Redis(主要)和Memcached负责项目配置、错误基础信息的存储和统计。Postgres承担基础数据持久化(主要是项目、用户权限管理等)Symbolicator主要用于错误信息格式化。
- 最底下的Zookeeper是Kafka用于节点信息同步的,如果我们设置了多个ClickHouse节点,也可以用它来保存主从同步信息或者做分布式表。
Relay——错误信息处理的中转站
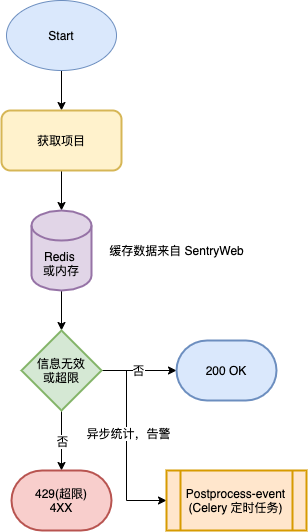
Relay收到原始数据后,主要做这几件事。
- 对其格式进行有效性校验
- 查询内存或者从Redis拉取缓存得到项目配置信息,校验请求是否合法(项目是否存在或者有没有触发限流,没触发限流则会对API额度进行累计,写入Redis)
- 发起一个异步请求给定时任务(Sentry Worker,postprocess-event)做下一步处理
Kafka和Celery——应用解耦和异步保存数据
Relay数据转发到Kafka的ingest-events Topic(Ingest即摄取),消费者消费后把消息放入postprocess-event这个Celery定时任务服务排队处理。队列做的事情如下
- Symbolicate-event,在iOS上有个叫symbolicate-crash的工具,是将机器的崩溃日志转化为可读的崩溃代码定位日志,这里的Symbolicator同样承担类似的职能,由它经手的消息,我们就可以在页面上看到代码在哪里出错了。
- process-event,字面含义就是处理消息,在Sentry上启用的插件(Plugins or Integration)会在这个步骤中应用到消息体上,例如,整合了一个Slackbot(机器人),就会在这个步骤发送告警。
- save-event,消息经过简化,保存到数据库,同时再次发到Kafka,但这次换到eventTopic,Snuba这个搜索组件内部会有一个消费者,对这部分数据批量写入到ClickHouse。你可能好奇为什么不直接存进去算了还要搞多这一步,这是因为ClickHouse虽然大数据量处理能力很强,但频繁写入能力是真的菜(假设做了主从,那就更灾难了,把从库和Zookeeper都一起拉下水),所以需要Snuba来限制写入频率。
SentryWeb
SentryWeb这边主要跟配置等持久化数据打交道,创建项目、权限控制、限流分配等都是它负责。查询搜索错误消息、Dashboard聚合等功能则是Snuba承担,由它来当翻译官,把用户查询条件转化为SQL语句发给ClickHouse。
Sentry的私有化部署
Sentry私有化部署通常通过Docker和Kubernetes等现代容器化技术来实现,这使得部署过程更加简便和灵活。以下是一些关键步骤:
- 环境准备:
- 确保服务器或集群满足Sentry的系统要求,包括CPU、内存、存储和网络配置。
- 安装并配置Docker和Docker Compose,或Kubernetes环境。
- 获取Sentry镜像:
- 从Sentry官方Docker镜像库中拉取最新的Sentry镜像。
- 配置Sentry:
- 使用Docker Compose文件或Kubernetes配置文件设置Sentry的服务,包括Web服务器、数据库(PostgreSQL)、缓存(Redis)等。
- 配置环境变量和密钥,确保Sentry正确连接到所需的服务。
- 启动服务:
- 使用Docker Compose或Kubernetes命令启动Sentry服务,并确保所有组件正常运行。
- 监控和维护:
- 部署后,定期监控Sentry的性能和资源使用情况。
- 及时更新和维护Sentry及其依赖服务,应用安全补丁和版本更新。
资源需求
- 数据库:Sentry需要PostgreSQL作为其主数据库。
- 缓存:Redis用于缓存和任务队列。
- 对象存储:可选的对象存储(如AWS S3)用于存储大型文件和附件。
Sentry的接入使用(Python)
是Sentry的Python SDK,允许Python应用程序将错误和性能数据发送到Sentry服务。

安装
可以通过pip安装sentry-sdk:pip install sentry-sdk初始化
在应用程序启动时初始化Sentry,使用从Sentry项目中获取的DSN(Data Source Name):
import sentry_sdk
sentry_sdk.init(
dsn="https://your-dsn@sentry.io/project-id",
traces_sample_rate=1.0 # 设置性能监控的采样率
)
集成框架
对于Django项目,可以通过中间件集成:
import sentry_sdk
from sentry_sdk.integrations.django import DjangoIntegration
sentry_sdk.init(
dsn="https://your-dsn@sentry.io/project-id",
integrations=[DjangoIntegration()],
traces_sample_rate=1.0
)
对于Flask项目,可以通过扩展集成:
import sentry_sdk
from sentry_sdk.integrations.flask import FlaskIntegration
sentry_sdk.init(
dsn="https://your-dsn@sentry.io/project-id",
integrations=[FlaskIntegration()],
traces_sample_rate=1.0
)
对于Celery,可以通过Celery集成:
import sentry_sdk
from sentry_sdk.integrations.celery import CeleryIntegration
sentry_sdk.init(
dsn="https://your-dsn@sentry.io/project-id",
integrations=[CeleryIntegration()],
traces_sample_rate=1.0
)
错误捕获
自动捕获
Sentry会自动捕获未处理的异常并将其发送到Sentry仪表板。
可以使用capture_exception或capture_message手动记录错误和消息:
from sentry_sdk import capture_exception, capture_message
try:
1/0
except ZeroDivisionError as e:
capture_exception(e)
capture_message("Something went wrong!")
性能监控
通过设置traces_sample_rate,可以启用性能监控,帮助识别应用程序中的性能瓶颈。
上下文信息
可以通过set_user和set_context设置用户信息和其他上下文信息:
from sentry_sdk import set_user, set_context
set_user({"id": "123", "email": "user@example.com"})
set_context("character", {"name": "Mighty Fighter", "age": 19})
实践中的一些建议
- 设置适当的采样率:在生产环境中,设置合理的 traces_sample_rate 以控制数据量。
- 使用版本管理:在部署新版本时更新 Sentry 的版本信息,以便更好地跟踪错误。
- 自定义标签和上下文:使用标签和上下文功能来丰富错误信息,有助于快速诊断问题。
- 监控性能:使用性能监控功能识别和优化应用程序的性能瓶颈。
Sentry-Python 是一个功能强大且易于使用的工具,能够帮助开发者更好地监控和维护 Python 应用程序的健康状态。通过集成 Sentry,开发者可以快速识别和解决生产环境中的问题,提高应用的可靠性和用户满意度。
参考链接:


