在建立回归模型时需要对模型的效果进行评测,选择哪一种指标作为评估指标也会影响最终模型的效果。这里选择ScikitLearn自带的回归模型评估指标进行详细讲解。
- explained_variance_score(y_true, y_pred) Explained variance regression score function
- mean_absolute_error(y_true, y_pred) Mean absolute error regression loss
- mean_squared_error(y_true, y_pred[, …]) Mean squared error regression loss
- mean_squared_log_error(y_true, y_pred) Mean squared logarithmic error regression loss
- median_absolute_error(y_true, y_pred) Median absolute error regression loss
- r2_score(y_true, y_pred[, …]) R^2 (coefficient of determination) regression score function.
可解释方差Explained Variance Score
假设y是真实值,f是相对应的预测值,Var是方差,Explained Variance由下式公式给出:
$$Explained\ Variance=1-\frac{Var(y-f)}{Var(y)}$$
值最大为1,越接近1越好什么是可解释方差?
在理解”可解释方差”前,需要先了解下方差:离平均的平方距离的平均。方差很难理解,其中的一个原因是很难可视化。可解释方差并不意味着解释了方差,仅仅意味着我们可以使用一个或多个变量来比以前更准确地预测事物。
在许多模型中,如果X与Y相关,X可以说是”解释”了Y中的方差,即使X并不真正导致Y。在下面的例子中,Y的方差的80%是由于X,剩下的20%由其他的一些Error导致的。由于X与Error非相关的z-score值,路径系数等于与Y的相关系数。
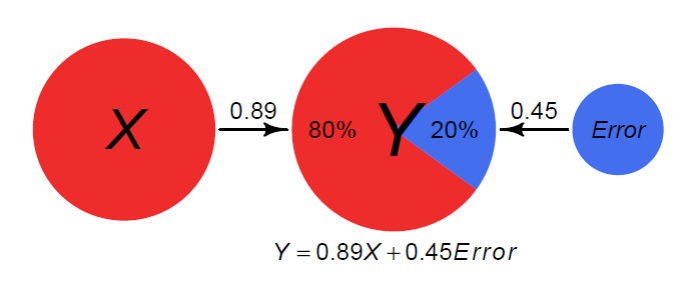
可解释方差的可视化
如果X预测Y,那么解释的方差等于相关系数的平方。不幸的是,这只是一个公式。它无助于我们理解它的含义。也许这种可视化会有所帮助:
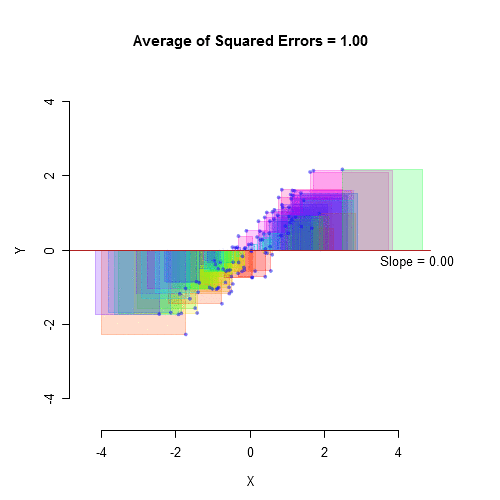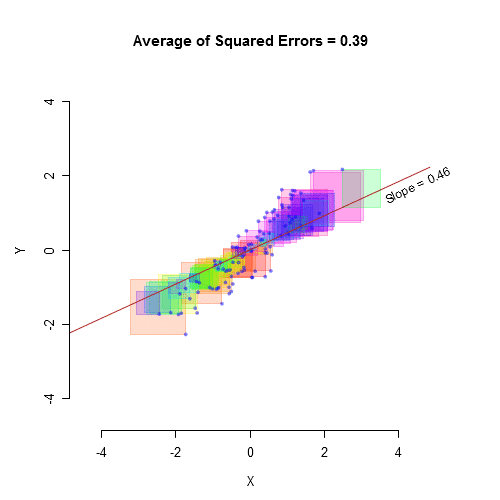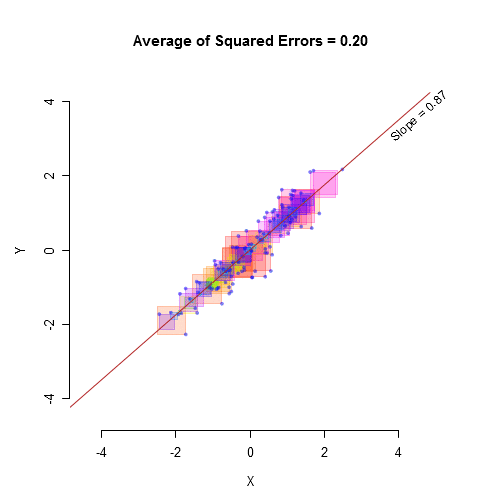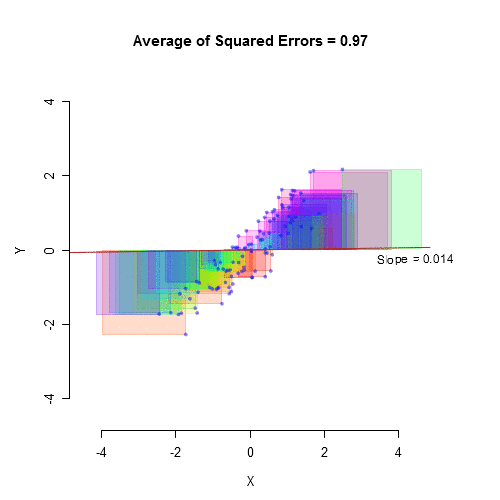
平均绝对误差Mean Absolute Error (MAE)
MAE用来描述预测值和真实值的差值。数值越小越好。假设$y_i$是真实值,$f_i$是相对应的预测值,则n个样本的MAE可由下式出给:
$$MAE=\frac{1}{n}\sum_{i=1}^{n}|f_i-y_i|$$
MAE优缺点:虽然平均绝对误差能够获得一个评价值,但是你并不知道这个值代表模型拟合是优还是劣,只有通过对比才能达到效果。
均方误差Mean Squared Error (MSE)
Mean Squared Error也称为Mean Squared Deviation (MSD),计算的是预测值和实际值的平方误差。同样,数值越小越好。
假设$y_i$是真实值,$f_i$是相对应的预测值,则n个样本的MSE由下式公式给出:
$$MSE=\frac{1}{n}\sum_{i=1}^{n}(f_i-y_i)^2$$
由于MSE与我们的目标变量的量纲不一致,为了保证量纲一致性,我们需要对MSE进行开方,即均方根误差(RMSE):
均方根误差Root Mean Squared Error(RMSE)
均方根误差RMSE(root-mean-square error),均方根误差亦称标准误差,它是观测值与真值偏差的平方与观测次数比值的平方根。均方根误差是用来衡量观测值同真值之间的偏差。标准误差对一组测量中的特大或特小误差反映非常敏感,所以,标准误差能够很好地反映出测量的精密度。可用标准误差作为评定这一测量过程精度的标准。计算公式如下:
$$RMSE=\sqrt{\frac{1}{n}\sum_{i=1}^{n}(f_i-y_i)^2}$$
这不就是MSE开个根号么。有意义么?其实实质是一样的。只不过用于数据更好的描述。例如:要做房价预测,每平方是万元,我们预测结果也是万元。那么差值的平方单位应该是千万级别的。那我们不太好描述自己做的模型效果。我们的模型误差是多少千万?于是干脆就开个根号就好了。我们误差的结果就跟我们数据是一个级别的,可在描述模型的时候就说,我们模型的误差是多少万元。
RMSE与MAE对比:RMSE相当于L2范数,MAE相当于L1范数。次数越高,计算结果就越与较大的值有关,而忽略较小的值,所以这就是为什么RMSE针对异常值更敏感的原因(即有一个预测值与真实值相差很大,那么RMSE就会很大)。
均值平方对数误差Mean Squared Log Error (MSLE)
如果$\hat{y}_i$是第i个样本的预测值,$y_i$是相应的真实值,则在$n_{samples}$上估计的均方对数误差(MSLE)被定义为:
$$\text{MSLE}(y,\hat{y})=\frac{1}{n_\text{samples}}\sum_{i=0}^{n_\text{samples}-1}(\log_e(1+y_i)-\log_e(1+\hat{y}_i))^2$$
其中$log_e(x)$表示x的自然对数。当目标具有指数增长的目标时,最适合使用这一指标,例如人口数量,商品在一段时间内的平均销售额等。
注意,该度量对低于真实值的预测更加敏感。
中位数绝对误差Median Absolute Error(Median AE)
中位数绝对误差非常有趣,因为它可以减弱异常值的影响。通过取目标和预测之间的所有绝对差值的中值来计算损失。如果$\hat{y}_i$是第i个样本的预测值,$y_i$是相应的真实值,则在$n_{samples}$上估计的中值绝对误差(MedAE)被定义为:
$$\text{MedAE}(y,\hat{y})=\text{median}(\mid y_1-\hat{y}_1 \mid,\ldots,\mid y_n-\hat{y}_n \mid)$$
R-平方$R^2$ Score
$R^2$ Score又称为the coefficient of determination。判断的是预测模型和真实数据的拟合程度,最佳值为1,同时可为负值。
假设$y_i$是真实值,$f_i$是相对应的预测值,则n个样本的$R^2$ score由下式公式给出:
$$R^2=1-\frac{\sum_{i=1}^{n}(y_i-f_i)^2}{\sum_{i=1}^{n}(y_i-\overline{y})^2}$$
其中$\overline{y}$是y的均值,即$\overline{y}=\frac{1}{n}\sum_{i=1}^{n}y_i$
如果结果是0,就说明我们的模型跟瞎猜差不多。如果结果是1。就说明我们模型无错误。如果结果是0-1之间的数,就是我们模型的好坏程度。如果结果是负数。说明我们的模型还不如瞎猜。
参考链接:


