在过去,不同的人为各种各样的数据库实现了各种各样的数据库接口程序。这些接口由不同的人在不同的时间实现,功能接口各不兼容,这意味着使用这些接口的程序必须自定义他们选择的接口模块。当这个接口模块变化时,应用程序的代码也必须随之更新。
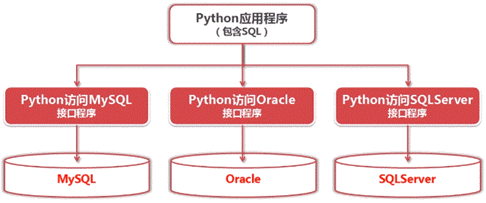
一个处理Python数据库事务的特殊事物小组(special interest group, SIG)因此诞生,最后DB-API 1.0问世。DB-API为不同的数据库提供了一致的访问接口,在不同的数据库之间移植代码成为一件轻松的事情。
PEP249中文翻译(Python Database API Specification v2.0)
介绍
定义本API的目的在于鼓励促进所有用于访问数据库的Python模块相互之间的一致性。为了做到这点,我们希望实现一个一致性的指引,以便实现更易于理解的模块,更加通用的易于在不同数据库间移植的代码,和Python中更广泛的数据库访问手段。PEP249的目标是让”数据库访问模块”提供相似的接口,实现一致性,从而让代码便于移植。
对于本规范的意见和为题可以去讨论列表the SIG for Database Interfacing with Python (db-sig@python.org)。
如果需要了解与数据库接口相关的各种库,请看Database Topic Guide。
PEP249是Python数据库API规范的2.0版本,PEP248是1.0版本。PEP249不仅包含Python数据库API规范,还描述了一组具备通用性的可选扩展。早先的1.0版本(PEP248)依然具备参考价值,但鼓励模块编写者在开发新接口时以PEP249为参考。
模块接口(Module Interface)
构造器
本规范约定,需通过Connection对象来访问数据库,因此”数据库访问模块”必须提供用来创建Connection对象的构造器。
connect(parameters…)
数据库连接对象的构造函数,返回值为Connection对象实例。由于目的数据库不同,函数接收数量不等的一些参数。
模块级全局变量
数据库访问模块必须定义本节中给出的各种全局变量apilevel
一个字符串常量,表示模块支持的DBAPI版本。目前只允许使用字符串”1.0″(对应PEP248)和”2.0″(对应PEP249)。如果未给出该常量,则假设模块使用DB-API 1.0。
threadsafety
用于说明此模块接口所支持的线程安全级别,以整型表示。以下是可选值:
| threadsafety | 含义 |
| 0 | 线程间不可“共享”模块 |
| 1 | 线程间可以“共享”模块,但不可“共享”连接 |
| 2 | 模块以及数据库连接均可以在线程间“共享” |
| 3 | 模块、数据库连接以及游标(cursors)均可以在线程间“共享” |
上文中“共享”的意思是两个线程在没有使用互斥信号(mutex semaphore)锁的情况下,同时使用一个资源。要注意的是,你并不总能使用互斥信号来确保一个外部资源线程安全,这是因为外部资源很有可能依赖于一个全局变量或是其他的外部资源,然而这些是你不能控制的。
paramstyle
一个字符串常量,用于说明模块接口期望的参数标记(parameter marker)的格式化风格,可选值如下:
| paramstyle | 含义 |
| qmark | 问号风格,例如 ….WHERE name=? |
| numeric | 数字配合位置参数风格,例如 …WHERE name=:1 |
| named | 命名参数风格,例如 …WHERE name=:name |
| format | ANSIC printf代码格式化风格,例如 …WHERE name=%s |
| pyformat | Python的扩展格式化风格,例如 …WHERE name=%(name)s |
模块实现者可能更倾向于使用numeric,named或者pyformat,因为它们更为清晰而且灵活。
异常
模块应该要通过以下的execption以及其相关子类来提供全部的报错信息:
Warning
对于重要警告抛出的异常类型,例如插入数据的时候发生data truncation等。它必须是Python的StandardError的子类(这个类在exceptions模块中定义)。
Error
此异常是所以其他error异常的基类。通过它,你可以只写一条异常捕获语句就可以捕获全部的error异常。Warning不会被视为error,因此不使用它作为基类。它必须是Python的StandardError的子类(这个类在exceptions模块中定义)。
InterfaceError
针对数据库接口而非数据库本身的错误所要抛出的异常类。它必须是Error的子类。
DatabaseError
针对数据库本身错误所要抛出的异常类。它必须是Error的子类。
DataError
由于数据处理出现问题而导致的错误所抛出的异常类,例如除以零、数值大小超出范围等。它必须是DatabaseError的子类。
OperationalError
针对数据库操作相关的错误(并且不一定实在程序员控制之下发生的)所要抛出的异常类,例如发生意外的连接断开、找不到数据源名称、事务无法处理、处理期间内存分配出错等。它必须是DatabaseError的子类。
IntegrityError
当数据库的关系完整性受到影响时所要抛出的异常类,例如外键检验失败。它必须是DatabaseError的子类。
InternalError
数据库发生内部错误时所要抛出的异常类,例如游标失效、事务不同步等。它必须是DatabaseError的子类。
ProgrammingError
针对编码过程中的错误所要抛出的异常,例如表未找到或表已存在、SQL语句存在语法错误、指定参数的数量有误等等。它必须是DatabaseError的子类。
NotSupportedError
StandardError |__Warning |__Error |__InterfaceError |__DatabaseError |__DataError |__OperationalError |__IntegrityError |__InternalError |__ProgrammingError |__NotSupportedError
注:这些例外(Exceptions)的值(错误信息)并没有明确的定义,但是它们应该能够给用户指出足够好的错误提示。
连接对象(Connection Objects)
Connection对象必须实现本节中给出的各种方法。
Connection方法
.close()
立即关闭连接(而不是每次都调用.__del__()方法)
使用此方法后连接将不再可用。如果试图对这个连接做任何操作都会抛出Error(或其子类)的异常。这同样适用于这个连接的所有游标对象。注意,如果不先commit变更的情况下关闭连接会导致执行隐式的rollback操作。
.commit()
将任何挂起的事务提交到数据库。
注意,如果数据库支持自动提交功能,那么必须要先关掉它(这个方法才会起效)。你可以选择提供一个接口方法来重新打开自动提交。
对于不支持事务的数据库,其对应的模块应该以空方法(void functionality)的方式实现这个方法。
.rollback()
此方法是可选的,因为并非所有数据库都提供事务的支持。
如果数据库确实提供了事务的支持,则此方法会回滚数据库到任何挂起的事务之前。如果不先commit变更的情况下关闭连接会导致执行隐式的rollback操作。
.cursor()
使用此连接返回一个Cursor对象。
如果数据库并未直接提供游标的概念,则实现模块必须使用其他方式来模拟规范所需的”游标”。
数据库接口可以选择通过给方法提供一个字符串类型的参数来构建具名cursor,这个并不是标准所要求的,主要是为了兼容.fetch*()方法的语义考虑。
Cursor对象
这个对象代表数据库的游标(cursor),常用于管理获取操作的上下文。同一个connection对象创建的cursor之间比并不是孤立(isolated)的,比如说,一个cursor对数据库的做的任何改动都会马上被其他的cursor所看到。而由不同的connection对象中创建的cursor之间,它们的隔离与否,取决于是否实现了事务的支持(可以查看Connection对象的.rollback()以及.commit()方法)。
Cursor属性
.description
这个只读的属性包含了以下7项内容组成的序列(一般是元组)的结果列描述。
每一个序列都包含一个结果列的信息描述。
- name
- type_code
- display
- internal_size
- precision
- scale
- null_ok
其中,前两项是必填(name以及type_coe)的;其他五项为可选项,如果没有合适的、有意义的值可以提供就会被设置为None。
在操作没有返回任何行的时候,或者cursor还没有通过.execute*()方法调用过操作之前,这个值就会为None。
type_code可以参照下面TypeObjects一节得到解释。
.rowcount
这个只读属性负责返回行数*,在这里是指最近一次.execute()操作所得到的结果行数(DQL语句如SELECT)或所影响的行数(DML语句如UPDATE或INSERT)。
如果这个cursor还没有执行过.execute*()操作,或者接口无法确定最后一次操作的rowcount,则这个属性的值为-1。
以后的DBAPI版本的标准会重新定义,而目前最新的表述是:该值会返回None而不是-1。
Cursor方法
.callproc(procname[, parameters])
(这个方法是可选实现的,因为不是所有的数据库都提供存储过程功能)
调用指定procname作为名称的存储过程,参数序列(sequence of parameter)必须包含一个条目,由存储过程所需的每个参数组成。而调用的结果,将会在输入序列的副本上作修改,然后返回。其中,IN参数(输入参数)保持不变,OUT参数(输出参数)和INOUT参数(输入输出参数)有可能被替换为新的值。
存储过程也可以提供结果集作为输出。这样的话必须通过标准的.fetch*()方法来获取。
.close()
(此方法用于)马上关闭cursor(而不是调用__del__方法)
当执行这个操作开始,cursor将无法使用。如果之后试图使用这个cursor执行任何操作,都会引发一个Error或其(子类)的异常。
.execute(operation[, parameters])
(此方法用于)准备并执行一个数据库操作(查询query或者命令command)
参数可以以序列或映射表的形式提供,它们会被绑定到操作中的变量。变量是以数据库指定的表示方法所标识的(详细请参考模块的paramstyle属性)。
注意,对于parameters参数,模块会使用__getitem__方法来匹配位置参数(根据数字形式)或者关键字参数(根据字符串形式)。这意味着它同时支持parameters以序列或者映射的形式作为输入。
cursor负责保留(retain)操作的引用。如果再次传入相同的操作对象,那么cursor可以优化这个行为。这对于那种(多次)执行相同的操作但是绑定的参数不一样的情况下最为有效。
为了使得操作重用得到最大的效率,最好是使用etinputsizes()方法来提前指定参数的类型以及大小。参数与预定义的信息不匹配也是合法的,在实现上应该考虑做补偿(compensate),尽管可能会导致效率降低。
参数也可以指定为元组列表,例如,在单个操作中插入多行时。但这种操作并不推荐,这个时候应该使用.executemany()替代。
此方法未定义返回值。
.executemany(operation, seq_of_parameters)
(此方法用于)准备一个数据库操作(query或command),然后针对seq_of_parameters中找到的全部参数序列或映射表来执行。
DB模块对于此方法,可以使用多次调用.execute()方法的思路来实现;或者使用数组操作(array operation)以使得数据库可以能在一次调用中处理整个参数序列。
如果某个数据库操作使用了这个方法来执行而产生了一个或多个结果集,将构成未定义行为;当检测到通过此操作创建了结果集时,实现方被允许(但不做要求)抛出一个异常。
和.execute()相同的注释也相应地适用于此方法。
此方法未定义返回值。
.fetchone()
(此方法用于)获取查询结果集(query result set)中的下一行。方法将返回一个序列,或者在没有更多可用数据时返回None。
如果之前调用.execute*()方法没有产生任何结果集,或者在此之前尚未调用任何方法,此方法将抛出Error(或其子类)异常。
注意,数据库接口可能通过数组或者其他的优化形式来实现行数据的获取。因此无法保证对此方法的调用会使得对应cursor仅仅往前移动一行。
.fetchmany([size=cursor.arraysize])(此方法用于)获取查询结果集的下一组行。方法将返回一个序列的序列(例如元组列表)。当结果集中没有更多行的时候,返回空序列。
每次调用所获取的行数由参数 size 决定。如果没有给出这个入参,则默认使用 cursor 的 arraysize 属性来确定要获取的行数。这个方法会尽力获取 size 所指示的行数;如果因为结果集可用的行已经不足,则在这种情况下方法可能会返回更少的行。
如果之前调用 .execute*() 方法没有产生任何结果集,或者在此之前尚未调用任何方法,此方法将抛出 Error (或其子类)异常。
请注意,size 参数的设置大小应该从性能的角度出发来考虑。为了获得最佳性能,通常是直接使用 .arraysize 属性的值。如果自定义了 size 入参,那么最好保持一致(即不要每次调用 fetchmany 都使用不同的 size 值)。
.fetchall()
(此方法用于)获取查询结果的所有(剩余的)行结果,将它们作为序列的序列返回(例如元组列表)。注意,cursor 的 arraysize 属性可能会影响此操作的性能。
如果之前调用 .execute*() 方法没有产生任何结果集,或者在此之前尚未调用任何方法,此方法将抛出 Error (或其子类)异常。
.nextset()
(此方法是可选的,因为并非所有数据库都支持多结果集)
这个方法会使得 cursor 跳到下一个可用的结果集,并丢弃当前结果集的所有剩余行。
如果没有更多的集合,这个方法会返回 None 。否则,它将返回一个真值,后续使用 .fetch*() 方法会返回下一个结果集的行内容。
如果之前调用 .execute*() 方法没有产生任何结果集,或者在此之前尚未调用任何方法,此方法将抛出 Error (或其子类)异常。
.arraysize
这个可读写属性指定了通过 .fetchmany() 方法一次可以获取的行数。它的值默认为1,意味着一次只会获取一行数据。
实现方在实现 .fetchmany() 这个方法时必须留意这个值,但还是可以选择一次一行地和数据库进行交互。它也可以用于实现 .executemany() 方法上。
.setinputsizes(sizes)
此方法可以在调用 .execute*() 之前使用,用于预定义数据库操作参数所需的内存区域。
size 参数是一个序列——其中每个 .execute*() 的输入参数对应序列的一项。该项的值应该是对应使用的输入参数的 TypeObject;或者是用于指定字符串类型参数的最大长度的整数。如果该项为 None,则不会为该列保留预定义的内存区域(这对于避免给大的输入参数保留过大的内存区域相当有用)。
这个方法应该在 .execute*() 方法之前被调用。
实现方可以自由地选择是否实现这个方法,而用户也可以有不使用这个方法的自由。
.setoutputsize(size[,column])
为获取大的数据列(例如 LONG 类型、BLOB 类型等)设置一个列缓冲区大小。column 参数用于指定(该列在)结果数据集的索引位置。如果不指定 column 则默认为 cursor 中全部的大数据列设置 size 大小的缓冲区。
这个方法应该在 .execute*() 方法之前被调用。
实现方可以自由地选择是否实现这个方法,而用户也可以有不使用这个方法的自由。
数据类型对象及构造(TypeObjects and Constructors)
许多数据库需要对绑定操作的输入参数指定特定的输入格式。例如,如果目标的输入列是一个 DATE 类型的列,那么它必须以特定的字符串格式来绑定到数据库。同样的的问题也存在于 RowID 列以及一些大的二进制对象(例如 blob 列以及 RAW 列)。这对于 Python 来说就不太友好,因为 .execute*() 的参数是无类型的。当 DB 模块看到一个 Python 的字符串对象时,它不知道应该将它简单的绑定为一个 CHAR 列,还是一个 rawBinary 项,抑或是一个 DATE 类型的值。
为了解决这个问题,模块必须提供以下定义的构造函数(constructors)来创建相应的对象以保存指定类型的值。当这个对象传递给 cursor 的方法时,模块就可以检测到输入参数的正确属性并对其进行相应的绑定。
一个 cursor 对象的 description 属性返回查询结果的每一列的信息。type_code 必须等于以下定义的 TypeObject 之一。TypeObject 可能等于多个类型代码(例如 DATETIME 可以等于 date、time 以及 timestamp 类型列的 typecode 。详情可参考下面的实现提示)。
模块将包含以下的构造函数和单例对象:
Date(year, month, day)
此函数构造一个 date 值的对象。
Time(hour, minute, second)
此函数构造一个 time 值的对象。
Timestamp(year, month, day, hour, minute, second)
此函数构造一个 timestamp 值的对象。
DateFromTicks(ticks)
此函数根据给定的 ticks 值构造一个 date 值的对象。其中 ticks 是秒数,详情可参考 Python 标准库的 time 模块的描述。
TimeFromTicks(ticks)
此函数根据给定的 ticks 值构造一个 time 值的对象。其中 ticks 是秒数,详情可参考 Python 标准库的 time 模块的描述。
TimestampFromTicks(ticks)
此函数根据给定的 ticks 值构造一个 timestamp 值的对象。其中 ticks 是秒数,详情可参考 Python 标准库的 time 模块的描述。
Binary(string)
此函数构造一个足以表示二进制(或 long)类型的字符串值的对象。
STRING type
此类型对象用于描述数据库中类字符串类型的列(例如 CHAR)
BINARY type
此类型对象用于描述数据库中的大对象列(例如 LONG、RAW、BLOBS)
NUMBER type
此类型对象用于描述数据库中的数值类型的列DATETIME type
此类型对象用于描述数据库中 date/time 类型的列ROWID type
此类型对象用于描述数据库中的 RowID 类型的列
在输入输出中,SQL 的 NULL 值在 Python 中以 None 单例对象的形式表示。
注意,使用 Unix 的 ticks 可能会导致麻烦,因为它们只支持有限的日期范围。
给模块实现者的建议
- 时间/日期对象(Date/time objects)可以用 Python 的 datetime 模块中的对象来实现(Python 2.3 版本开始提供,4 版本开始提供 C 版本 API),或者使用 mxDateTime 包中对象(可供 Python 1.5.2 版本以上使用)。它们都提供有足够的构造方法,使用方法(在 Python 中和 C 中使用都可以)。
- 下面是一个 Unix 下基于 ticks 构造为通用的 date/time 对象的代理示例:
import time
def DateFromTicks(ticks):
return Date(*time.localtime(ticks)[:3])
def TimeFromTicks(ticks):
return Time(*time.localtime(ticks)[3:6])
def TimestampFromTicks(ticks):
return Timestamp(*time.localtime(ticks)[:6])
- 二进制对象的首选对象从 Python 1.5.2 开始支持缓冲区类型。可以查看 Python 文档获取更多详情。关于 C 接口的信息可以查询 Python 源代码中的 Include/bufferobject.h 和 Objects/bufferobject.c。
- 这种 Python 类运行通过描述类型代码字段生成对 ontype 对象的多个值来实现上述类型对象:
class DBAPITypeObject:
def __init__(self, *values):
self.values = values
def __cmp__(self, other):
if other in self.values:
return 0
if other < self.values:
return 1
else:
return -1
结果类型对象比较等于传递给所有构造函数的值。
- 下面是实现上面定义的异常层次结构的Python代码片段:
import exceptions
class Error(exceptions.StandardError):
pass
class Warning(exceptions.StandardError):
pass
class InterfaceError(Error):
pass
class DatabaseError(Error):
pass
class InternalError(DatabaseError):
pass
class OperationalError(DatabaseError):
pass
class ProgrammingError(DatabaseError):
pass
class IntegrityError(DatabaseError):
pass
class DataError(DatabaseError):
pass
class NotSupportedError(DatabaseError):
pass
在C中,您可以使用PyErr_NewException(fullname, base, NULL) API来创建异常对象。
可选的DBAPI扩展(Optional DBAPI Extensions)
自DBAPI 2.0标准发布以来,模块的作者们经常会再DBAPI标准的要求之外扩展它们的实现。出于提高兼容性以及对于未来可能的标准有清晰的升级路径可言,这一节也为DBAPI 2.0标准定义了一组常见的扩展。
作为DBAPI的可选功能,数据库模块的作者可以自由地选择是否要实现这些额外的功能以及方法,或者仅在运行时抛出NotSupportedError以便检查其可用性。
我们建议,模块作者们通过给出Python的warnings来让编程人员有选择性地使用这些扩展。为了使得这些扩展功能可以被使用上,必须标准化这些警告消息以便(编程人员)可以屏蔽掉它们。这些所谓”标准的消息”是指以下的WarningMessage。
Cursor.rownumber
此只读属性应该要提供cursor中的结果集从0开始的索引;如果无法确定其索引大小,返回None。
这个索引值可以看作cursor在序列(结果集)中的索引。对应的获取(fetch next)操作会根据序列中的.rownumber作为索引来获取对应的行数据。
WarningMessage: “DB-API extension cursor.rownumber used”
Connection.Error, Connection.ProgrammingError, etc.
所有由DBAPI标准定义的异常类都必须作为Connection对象的属性对外公开(在模块作用域可用的除外)。
这个属性简化了在多连接环境中的错误处理。
WarningMessage: “DB-API extension connection.[exception] used”
Cursor.connection
这个只读属性返回创建该cursor的connection对象的引用。
这个属性简化了在多连接环境中编写多态代码的过程。
WarningMessage: “DB-API extension cursor.connection used”
Cursor.scroll(value[, mode=’relative’])
根据mode将结果集中的cursor滚动到新的位置。
如果mode是relative(默认值),则将value作为结果集中当前位置的偏移量;如果是absolute,则value代表目标的绝对位置。
如果滚动操作会导致cursor离开结果集,模块应该抛出一个IndexError异常。在这种情况下,cursor的位置应该是未定义(undefined)——最理想的情况当然是完全不移动光标。
WarningMessage: “DB-API extension cursor.scroll() used”
Cursor.messages
这是一个Python的list对象,负责将元组(异常类,异常值)附加到由游标从底层数据库接收的所有消息上。
除了.fetch*()方法之外,这个list的内容会自动被所有标准的cursor对象方法调用所清除(在方法被调用前),目的是为了避免过多的内存消耗。同样你也可以调用del cursor.messages[:]的方式手动清除。
数据库生成的所有错误和警告信息都放在此列表中,因此用户可以通过检查这个list的内容来验证调用方法的操作是否正确。
这个属性的目的是为了避免那些会导致问题的异常告警(一些告警确实只含有信息)。
WarningMessage: “DB-API extension cursor.messages used”
Connection.messages
和Cursor.messages类似,不过list中的信息是面向connection对象的。
这个list对象会在任何connection对象方法所清空(在方法被调用前),以避免过多的内存消耗。同样你可以执行del connection.messages[:]来手动清除。
WarningMessage: “DB-API extension connection.messages used”
Cursor.next()
和.fetchone()有着相同的语义,都是从当前执行的SQL语句中返回下一行数据。当结果集遍历结束时,对于Python 2.2以上的版本应该抛出StopIteration异常。之前的版本由于没有StopIteration异常,所以取而代之应该抛出IndexError异常。
WarningMessage: “DB-API extension cursor.next() used”
Cursor.__iter__()
这个方法返回cursor本身,主要是为了兼容生成器协议。
WarningMessage: “DB-API extension cursor.__iter__() used”
Cursor.lastrowid
这个只读属性提供了最近一次被修改的行的rowid(大多数数据库支持尽在执行单个INSERT操作时返回一个rowid)。如果操作未设置rowid或者数据库不支持rowid,则此属性应设置为None。
如果最近一次的执行语句修改了多行数据,.lastrowid的语义无法定义,例如,用.executemany()执行INSERT操作。
WarningMessage: “DB-API extension cursor.lastrowid used”
可选的错误处理扩展(Optional Error Handling Extensions)
核心的DBAPI标准仅仅声明了一组会抛出给使用者来报告错误的异常。在某些情况下,异常可能会对程序的流程造成极大的破坏,甚至于无法执行。
对于这种情况,为了简化对于数据库错误的处理,数据库模块的作者可能会提供这样的实现,让用户自定义的错误处理程序。本节将介绍定义这些错误处理程序的标准方法。
Connection.errorhandler, Cursor.errorhandler
该可读写属性表示错误处理程序,用于处理遇到的错误情况。
这个handler必须是Python的可调用对象(callable),它包含以下参数:errorhandler(connection, cursor, errorclass, errorvalue)
其中:
- connection表示cursor操作的connection对象;
- cursor表示cursor对象(如果这个error不是由cursor引起的则为None)
- errorclass是表示的是错误类型,它将使用errorvalue作为构造参数实例化一个error对象。
这个标准的错误处理程序会添加错误信息到 .messages 属性上(Connection.messages 或者 Cursor.messages),然后抛出由指定的 errorclass 和 errorvalue 作为参数的异常。
如果 .errorhandler 没有被设置(即该属性为 None),那么会调用外层的标准错误处理程序。
WarningMessage: “DB-API extension.errorhandler used”
可选两阶段提交扩展(Optional Two-Phase Commit Extensions)
很多数据库提供了二阶段提交 (two-phase commit) 以支持跨多个数据库链接来管理事务以及其他资源。
如果数据库后端本身提供了对 TPC 的支持而模块的作者同样希望暴露给使用者,以下的 API 就应该实现。同样,只能在运行时检查 NotSupportedError 异常判断数据库后端是否提供了 TPC 支持。
TPC Transaction IDs
大多数数据库遵循 XA 标准,transaction IDs 必须由以下三个组件组成
- formatID
- global transaction ID
- branch qualifier(分支限定符)
对于特定的全局事务,前两个组件对于所有资源来说应该都是相同的,然后为全局事务的每个资源分配不同的 branch qualifier。
各组件必须满足以下标准:
- formatID —— 32 位的非负整数
- global transaction ID & branch qualifier: 不超过 64 字符的字节字符串 (bytestring)
Transaction ID 必须由 Connection 对象的 .xid() 方法创建:
.xid(format_id, global_transaction_id, branch_qualifier)
返回一个 transaction ID 对象,该对象用于传递给 connection 的 .tpc_*() 方法。
如果数据库连接不支持 TPC,应该抛出 NotSupportedError 异常。
.xid() 方法返回的对象类型在此并没有定义,但是他必须提供类似序列的行为,并且允许访问三个组件。符合要求的数据库模块可以选择用元组而不是自定义一个对象来实现这个返回值。
TPC Connection 方法
.tpc_begin(xid)
使用指定的 transaction ID 来开始一个 TPC 事务。
这个方法应该在事务之外的地方被调用(例如,在 .commit() 或 .rollback() 方法被调用之后)。
此外,在 TPC 事务中调用 .commit() 或 .rollback() 会导致错误,抛出一个 ProgrammingError 异常。
如果数据库连接不支持 TPC,应该抛出 NotSupportedError 异常。
.tpc_prepare()
此方法用于在 .tpc_begin() 之后执行第一段的事务。如果这个方法在 TPC 事务外被调用会引发一个 ProgrammingError 异常。
调用 .tpc_prepare() 之后,直到调用 .tpc_commit() 或 .tpc_rollback() 之前不能执行任何语句。
.tpc_commit([xid])
当无参调用这个方法时,会把之前由 .tpc_prepare() 负责准备阶段的事务进行提交。
如果 .tpc_commit() 先于 .tpc_prepare() 被调用,那么它就只执行单一阶段的提交。如果只有一个资源参与到全局事务中,那么事务管理器可以选择执行此操作。
当带着 xid 参数调用此方法,数据库会提交指定的事务。如果提供的是无效的 transaction ID,会抛出一个 ProgrammingError 异常。此时应该在事务外被调用,主要用于恢复操作。
当这个方法返回时,表示 TPC 事务的结束。
.tpc_rollback([xid])
当无参调用这个方法时,会回滚一个 TPC 事务。此方法应该在 .tpc_prepare 之前或之后调用。
当带着 xid 参数调用此方法,它会回滚指定的事务。如果提供的是无效的 transaction ID,会抛出一个 ProgrammingError 异常。此时应该在事务外被调用,主要用于恢复操作。
当这个方法返回时,表示 TPC 事务的结束。
.tpc_recover()
返回一个由挂起的 transaction ID 组成的 list,它们适用于 .tpc_commit(xid) 或 .tpc_rollback(xid) 操作。
如果数据库不支持事务恢复,那么应该返回一个空列表或者直接抛出 NotSupportedError 异常。
常见问题(Frequently Asked Questions)
在数据库的 SIG 中经常会看到重复出现的对于 DBAPI 标准的问题。本节介绍了一些人们常对这份标准提出的问题。
问:我怎么从 .fetch*() 返回的元组来构成一个字典?
答:有几种现成的工具可以帮你完成这项工作。它们中的大多数是使用 cursor.description 属性中定义的列名作为字典键值的基本方法。
对于为什么不直接扩展 DBAPI 标准以支持字典返回值是有理由的。因为这样做有几个缺点:
- 某些数据库对列名的大小写不敏感,或者会自动将列名全部转为小写或大写
- 结果集中的列是由查询(例如使用 SQL 函数)产生的,它不一定匹配数据库表的列名,而数据库通常会用一种数据库特有的方式去生成这些列名。
因此,通过字典的键值来访问列名以及编写可移植的代码是不可能的。
1.0 到 2.0 的主要改变(Major Changes from Version 1.0 to Version 2.0)
Python DBAPI 2.0 相对于 1.0 来说引入了几个很重大的改变。由于其中一些变动会导致已有的基于 DBAPI 1.0 的脚本不能运行。因此做了主版本号的改变,升级为 DB-API 2.0 规范来反映这些变化。
下面这些是从 1.0 到 2.0 最重要的改变:
- 不在需要单独的 dbi 模块,而是直接打包进数据库访问模块当中。
- 日期/时间类型添加了新的构造,RAW 类型改名为 BINARY。结果集中应该覆盖现代 SQL 数据库中的基本数据类型。
- 为了更好的数据库绑定,添加了新的常量(apilevel, threadlevel, paramstyle)和方法(.executemany(), .nextset())。
- 明确定义了需要用来访问存储过程的的方法 .callproc()。
- 方法 .execute() 的返回值定义有所改变。前期版本中,返回值定义是基于所执行的 SQL 语句类型的(这经常比较难以实现)– 下载它没有了明确的定义;代替它的是用户应该访问更适合的 .rowcount 属性。模块作者可以仍然返回旧式的定义值,但是规范中不再会有明确定义,而且应该认为是取决于不同的数据访问模块的。
- 例外的类在新的规范中有统一明确的定义。模块作者可以任意的以继承类的形式来扩展新规范中所定义例外的层次。
DBAPI 2.0 规范的追加扩展规范:
- 定义了附加的可选的对核心 DB-API 功能的扩展功能集。
遗留问题(Open Issues)
尽管 2.0 版本阐明了许多 1.0 版本遗留的问题,但是仍有一些遗留问题留待以后的版本来实现解决:
- .nextset() 的返回值应能表现出新结果集的可用情况
- 集成decimal module Decimal 对象,以用作无损货币和十进制交换格式。
Python DB-API 的使用实例
Python可以支持非常多的数据库管理系统,比如MySQL、Oracle、SQLServer和PostgreSQL等。为了实现对这些DBMS的统一访问,Python需要遵守一个规范,这就是DBAPI规范。我在下图中列出了DBAPI规范的作用,这个规范给我们提供了数据库对象连接、对象交互和异常处理的方式,为各种DBMS提供了统一的访问接口。这样做的好处就是如果项目需要切换数据库,Python层的代码移植会比较简单。
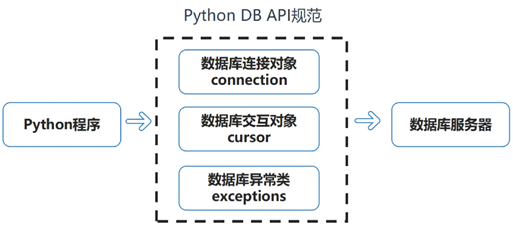
Python DBAPI各模块的作用:
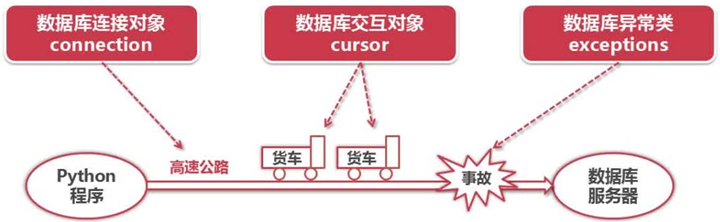
Python DBAPI访问数据库流程:
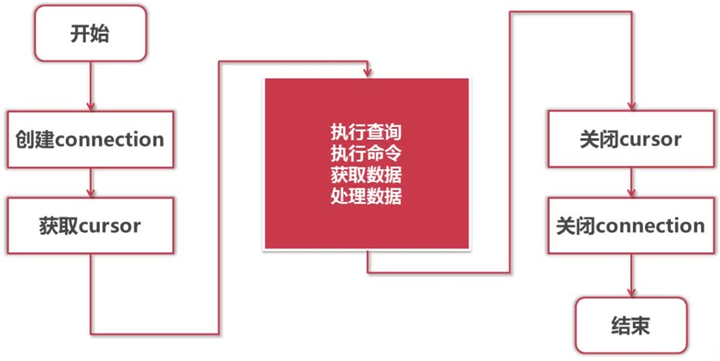
使用Python连接SQLite
创建数据库及表
首先,创建数据库,以及数据库中的表。在使用connect()连接数据库后,就可以通过定位指针cursor,来执行SQL命令:
import sqlite3
# test.db is a file in the working directory.
conn = sqlite3.connect("test.db")
cur = conn.cursor()
# create tables
cur.execute('''CREATE TABLE category
(id int primary key, sort int, name text)''')
cur.execute('''CREATE TABLE book
(id int primary key,
sort int,
name text,
price real,
category int,
FOREIGN KEY(category) REFERENCES category(id))''')
# save the changes
conn.commit()
# close the connection with the database
conn.close()
插入数据
import sqlite3
conn = sqlite3.connect("test.db")
cur = conn.cursor()
books = [(1, 1, 'Cook Recipe', 3.12, 1),
(2, 3, 'Python Intro', 17.5, 2),
(3, 2, 'OS Intro', 13.6, 2),
]
# execute "INSERT"
cur.execute("INSERT INTO category VALUES (1, 1, 'kitchen')")
# using the placeholder
cur.execute("INSERT INTO category VALUES (?, ?, ?)", [(2, 2, 'computer')])
# execute multiple commands
cur.executemany('INSERT INTO book VALUES (?, ?, ?, ?, ?)', books)
conn.commit()
conn.close()
SQL语句中的参数,使用”?”作为替代符号,并在后面的参数中给出具体值。这里不建议用Python的格式化字符串,如”%s”,因为这一用法容易受到SQL注入攻击。
也可以用executemany()的方法来执行多次插入,增加多个记录。每个记录是表中的一个元素,如上面的books表中的元素。
查询
import sqlite3
conn = sqlite3.connect('test.db')
cur = conn.cursor()
# retrieve one record
cur.execute('SELECT name FROM category ORDER BY sort')
print(cur.fetchone())
print(cur.fetchone())
# retrieve all records as a list
cur.execute('SELECT * FROM book WHERE book.category=1')
print(cur.fetchall())
# iterate through the records
for row in cur.execute('SELECT name, price FROM book ORDER BY sort'):
print(row)
更新与删除
可以更新某个记录,或者删除记录:
conn = sqlite3.connect("test.db")
cur = conn.cursor()
cur.execute('UPDATE book SET price=? WHERE id=?', (1000, 1))
cur.execute('DELETE FROM book WHERE id=2')
conn.commit()
conn.close()
也可以直接删除整张表:
cur.execute('DROP TABLE book')
如果删除test.db,那么整个数据库会被删除。
使用Python连接PostgreSQL
Python中可以用来连接PostgreSQL的模块很多,这里比较推荐psycopg2。psycopg2安装起来非常的简单(pip install psycopg2),这里主要重点介绍下如何使用。
连接数据库
import psycopg2 conn = psycopg2.connect(host="10.100.157.168", user="postgres", password="postgres", database="testdb")
连接时可用参数:
- dbname–数据库名称(dsn连接模式)
- database–数据库名称
- user–用户名
- password–密码
- host–服务器地址(如果不提供默认连接UnixSocket)
- port–连接端口(默认5432)
执行SQL
import psycopg2 conn = psycopg2.connect(host="10.100.157.168", port=5432, user="postgres", password="postgres", database="testdb") cur = conn.cursor() sql = "" cur.execute(sql) conn.commit() #查询时无需,此方法提交当前事务。如果不调用这个方法,无论做了什么修改,自从上次调用#commit()是不可见的 conn.close()
另外,执行SQL时支持参数化:
- 语法:cursor.execute(sql[, optional parameters])
- 案例:cursor.execute(“insert into people values (%s, %s)”, (who, age))
使用Python连接MySQL
本来以为使用Python安装MySQL是件容易的事,但是发现,安装MySQLdb容易出现问题,最为简单的方法是修改使用pymysql包,PyMySQL是一个用纯Python开发的MySQL driver,相比MySQL-python性能上会慢一些,但是他不需要从MySQL库文件等适用C进行编译。使用pip install pymysql安装即可。
使用Python连接SQLServer
如果直接使用pip install pymssql安装的话,会直接有问题:
C:\Program Files (x86)\PowerCmd>pip install pymssql Downloading/unpacking pymssql Downloading pymssql-2.0.0b1-dev-20111019.tar.gz (5.0Mb): 5.0Mb downloaded Running setup.py egg_info for package pymssql Traceback (most recent call last): File "<string>", line 14, in <module> File "C:\Program Files (x86)\PowerCmd\build\pymssql\setup.py", line 41, in <module> from Cython.Distutils import build_ext as _build_ext ImportError: No module named Cython.Distutils Complete output from command python setup.py egg_info: ---------------------------------------- Command python setup.py egg_info failed with error code 1 Storing complete log in C:\Users\ThinkPad\AppData\Roaming\pip\pip.log
从上面的报错中发现,原来是少了Cython这个扩展。Cython其实就是一个python的C编译器。安装起来也非常的简单。只要pip install Cython即可。中间安装的时间会比较长。安装完Cython后再次安装pymssql发现还是不成功。具体的报错内容为:
cl: 命令行 error D8021: 无效的数值参数“/Wl,-allow-multiple-definition” error: command '"C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\BIN\cl.exe"' failed with exit status 2
网上找了下,发现解决这个问题方法有很多种,但是都很烦,就是因为很烦,直接做了个非常牛X的安装包。
安装包下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#pymssql
示例代码1:
import pymssql
url_list = ['www.baidu.com', 'www.google.com']
date = ['2011-01-01', '2012-01-02']
conn = pymssql.connect(host='localhost:1433', user='test', password='test', database='MyTestDB')
cur = conn.cursor()
for url in url_list:
cur.execute("SELECT COUNT(DISTINCT CookieID) FROM [MyTestDB].[dbo].[VisitLog] WITH(NOLOCK) WHERE ComeDate>%s AND ComeDate<%s AND ReferrerDomain=%s", (date[0], date[1], url))
for row in cur:
print "%s, %d" % (url, row[0])
conn.close()
示例代码2:
import pymssql
conn = pymssql.connect(host='localhost:1433', user='sa', password='www.biaodianfu.com', database='TestDB')
cur = conn.cursor()
country = u'中国'
province = u'江苏'
city = u'苏州'
place = u'苏州乐园'
sql = "INSERT INTO [TestDB].[dbo].[testTable] (country, province, city, place) VALUES ('%s', '%s', '%s', '%s');" % (country, province, city, place)
sql = sql.encode('utf-8')
cur.execute(sql)
conn.commit()
conn.close()
参考链接:


