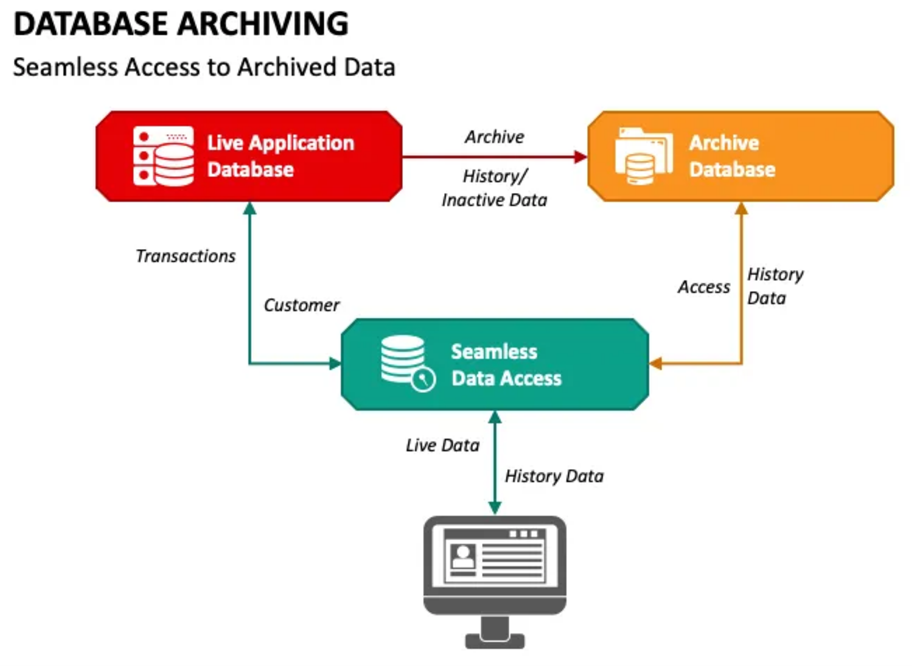
随着业务的发展,MySQL存储的数据会越来越大,不断增长的数据量让原本的业务查询越来越缓慢,除了对数据库水平扩展或垂直拓展外,最简单的方式就是对历史数据进行归档处理。在MySQL中,对历史数据进行归档可以通过多种方法实现,具体取决于你的需求和系统架构。
手动复制/导出与删除
手动复制与删除
- 创建一个专门用于存储历史数据的归档表。
- 定期将历史数据从主表中复制到归档表,并从主表中删除这些数据。
- 可以使用 INSERT INTO…SELECT 语句来实现数据的复制。
手动导出与复制
通过导出文件的方式对旧数据进行归档是一种常见的方法,尤其是在需要将数据长期存储或者在其他系统中使用时。这种方法通常涉及将数据导出到文件中(例如CSV、SQL dump等),然后根据需要存储或处理这些文件。
确定需要导出的数据
确定需要归档的旧数据。例如,假设我们有一个表 orders,我们希望导出一年前的订单数据。
SELECT * FROM orders WHERE order_date < CURDATE() - INTERVAL 1 YEAR;
使用 mysqldump 导出数据
mysqldump 是 MySQL 自带的实用工具,可以将数据导出为 SQL 文件。你可以使用它来导出满足条件的数据。
mysqldump -u username -p database_name orders --where="order_date < CURDATE() - INTERVAL 1 YEAR" > orders_archive.sql
- -u username: MySQL 用户名。
- -p: 提示输入密码。
- database_name: 数据库的名称。
- orders: 需要导出的表名。
- –where: 使用 SQL 条件导出特定数据。
- sql: 导出文件的名称。
使用 SELECT…INTO OUTFILE 导出数据
另一种方法是使用 SELECT…INTO OUTFILE 语句将数据导出为 CSV 或其他格式的文件。注意,此方法需要 MySQL 服务器有写入文件的权限。
SELECT * FROM orders WHERE order_date < CURDATE() - INTERVAL 1 YEAR INTO OUTFILE '/path/to/your/directory/orders_archive.csv' FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';
- /path/to/your/directory/orders_archive.csv: 导出文件的路径和名称。
- FIELDS TERMINATED BY ‘,’: 字段分隔符。
- ENCLOSED BY ‘”‘: 字段的引号。
- LINES TERMINATED BY ‘\n’: 行分隔符。
验证导出文件
确保导出的文件内容正确,并且可以被其他系统或工具读取。你可以使用文本编辑器或数据处理工具(如Excel、Python等)打开和验证文件内容。
删除旧数据(可选)
在确认数据已正确导出并备份后,可以从数据库中删除这些旧数据以释放空间:
DELETE FROM orders WHERE order_date < CURDATE() - INTERVAL 1 YEAR;
注意事项
- 备份:在删除数据之前,确保已经备份并验证导出文件。
- 权限:确保 MySQL 用户具有导出文件所需的权限,尤其是在使用 INTO OUTFILE 时。
- 安全性:导出文件可能包含敏感信息,确保其存储位置安全并受访问控制。
通过以上步骤,你可以使用导出文件的方式对旧数据进行归档,并根据需要进行存储和处理。
使用触发器使流程自动化
按照插入与更新进行触发
在 MySQL 中,触发器是一种自动执行的数据库对象,可以在插入、更新或删除操作发生时执行特定的 SQL 语句。要在主表上创建触发器,以便在数据插入或更新时根据条件自动将数据复制到归档表,可以按照以下步骤进行:
创建主表和归档表
首先,确保你有一个主表和一个归档表。假设主表名为 main_table,归档表名为 archive_table。
CREATE TABLE main_table ( id INT AUTO_INCREMENT PRIMARY KEY, data VARCHAR(255), created_at DATETIME DEFAULT CURRENT_TIMESTAMP ); CREATE TABLE archive_table LIKE main_table;
创建触发器
接下来,创建触发器来处理插入和更新操作。假设你想要在插入或更新数据时,将满足特定条件的数据(例如 created_at 早于一个月前的数据)复制到归档表。
插入触发器
CREATE TRIGGER before_insert_main_table BEFORE INSERT ON main_table FOR EACH ROW BEGIN IF NEW.created_at < CURDATE() - INTERVAL 1 MONTH THEN INSERT INTO archive_table(id, data, created_at) VALUES(NEW.id, NEW.data, NEW.created_at); END IF; END;
更新触发器
CREATE TRIGGER before_update_main_table BEFORE UPDATE ON main_table FOR EACH ROW BEGIN IF NEW.created_at < CURDATE() - INTERVAL 1 MONTH THEN INSERT INTO archive_table(id, data, created_at) VALUES(NEW.id, NEW.data, NEW.created_at); END IF; END;
测试触发器
你可以通过插入或更新数据来测试触发器是否正常工作。
-- 插入数据
INSERT INTO main_table(data, created_at) VALUES('Test data', NOW() - INTERVAL 2 MONTH);
-- 更新数据
UPDATE main_table SET data='Updated data' WHERE id=1;
检查归档表
验证触发器是否将符合条件的数据复制到归档表中:
SELECT * FROM archive_table;
注意事项
- 性能影响:触发器在高负载下可能会影响性能,尤其是在大量数据插入或更新的情况下。
- 事务管理:触发器在事务中执行时,确保考虑到事务的提交和回滚对数据的一致性影响。
- 调试和日志:可以在触发器中添加日志记录,以便于调试和监控。
通过这种方式,你可以在数据插入或更新时,根据条件自动将数据复制到归档表,实现数据的自动归档。
按照时间使用事件调度器
使用 MySQL 事件调度器来对历史数据进行归档是一个自动化的解决方案,可以在特定时间或周期内执行预定义的 SQL 操作。以下是如何设置 MySQL 事件调度器以实现数据归档的步骤:
启用事件调度器
首先,确保 MySQL 事件调度器是启用的。你可以通过以下命令来检查和启用:
SHOW VARIABLES LIKE 'event_scheduler';
如果返回值是 OFF,你可以通过以下命令启用它:
SET GLOBAL event_scheduler = ON;
或者在 MySQL 配置文件(my.cnf 或 my.ini)中添加:
event_scheduler = ON
创建归档表
假设你有一个主表 logs,你需要一个归档表 logs_archive 来存储历史数据:
CREATE TABLE IF NOT EXISTS logs_archive LIKE logs;
创建事件
现在,可以创建一个 MySQL 事件来定期将旧数据从主表移动到归档表。例如,将一个月前的数据归档:
CREATE EVENT archive_old_logs ON SCHEDULE EVERY 1 MONTH STARTS CURRENT_TIMESTAMP + INTERVAL 1 DAY DO BEGIN -- 将一个月前的数据插入到归档表 INSERT INTO logs_archive (id, message, log_date) SELECT id, message, log_date FROM logs WHERE log_date < CURDATE() - INTERVAL 1 MONTH; -- 从主表中删除已归档的数据 DELETE FROM logs WHERE log_date < CURDATE() - INTERVAL 1 MONTH; END;
验证事件
你可以通过以下命令查看事件是否创建成功:
SHOW EVENTS;
管理和监控
- 修改事件:如果需要更改事件的时间或逻辑,可以使用 ALTER EVENT 命令。
- 禁用事件:如果暂时不需要归档,可以禁用事件:ALTER EVENT archive_old_logs DISABLE;
- 删除事件:如果不再需要该事件,可以删除:DROP EVENT archive_old_logs;
注意事项
- 备份数据:在自动化删除数据之前,确保数据已经被正确归档并备份。
- 性能影响:在高负载的环境中,归档操作可能会影响性能,建议在低流量时段执行。
- 错误处理:在实际环境中,建议增加错误处理机制,以防止由于意外情况导致的数据丢失。
通过这些步骤,你可以使用 MySQL 事件调度器实现对历史数据的自动归档,从而简化数据管理流程。
使用日期分区表
使用分区表对 MySQL 历史数据进行归档是一个有效的方法,可以提高查询性能并简化数据管理。以下是如何使用分区表进行数据归档的步骤:
确定分区策略
首先,你需要决定如何对数据进行分区。常见的分区策略包括按日期(例如,按年、月、周)或按其他列(如 ID 范围)进行分区。对于历史数据归档,按日期进行分区是最常见的做法。
创建分区表
假设我们有一个日志表 logs,我们可以按日期进行分区。以下是一个简单的示例,按年份进行分区:
CREATE TABLE logs ( id INT AUTO_INCREMENT, message TEXT, log_date DATE, PRIMARY KEY (id, log_date) ) PARTITION BY RANGE (YEAR(log_date)) ( PARTITION p2020 VALUES LESS THAN (2021), PARTITION p2021 VALUES LESS THAN (2022), PARTITION p2022 VALUES LESS THAN (2023), PARTITION pmax VALUES LESS THAN MAXVALUE );
添加新分区
每年或每个时间周期结束时,添加新的分区。例如,为 2023 年添加新分区:
ALTER TABLE logs ADD PARTITION ( PARTITION p2023 VALUES LESS THAN (2024) );
移动旧数据到归档表
当一个分区的数据被视为历史数据时,可以将其数据移动到归档表中。你可以使用 ALTER TABLE…REORGANIZE PARTITION 来实现:
CREATE TABLE logs_archive LIKE logs; ALTER TABLE logs REORGANIZE PARTITION p2020 INTO ( PARTITION p2020_archive VALUES LESS THAN (2021) ); ALTER TABLE logs_archive EXCHANGE PARTITION p2020_archive WITH TABLE logs;
删除旧分区
一旦数据被移动到归档表并确认无误,可以删除旧分区以释放空间:
ALTER TABLE logs DROP PARTITION p2020;
查询归档数据
查询归档数据时,需要从归档表中检索:
SELECT * FROM logs_archive WHERE log_date < '2021-01-01';
注意事项
- 备份数据:在执行分区和数据移动操作之前,确保对数据进行了适当的备份。
- 性能影响:分区表的设计和管理可能会对性能产生影响,尤其是在高负载的环境中。
- 分区限制:MySQL 对分区表有一些限制,例如分区的数量,确保在设计时考虑到这些限制。
通过上述步骤,你可以有效地使用分区表对 MySQL 中的历史数据进行归档管理。
使用第三方工具 Percona Toolkit
Percona Toolkit 是一组用于 MySQL 的高级命令行工具,其中包括 pt-archiver,这是一个用于高效归档和清理数据的工具。pt-archiver 可以将旧数据从主表移动到归档表或删除它们,并且在大数据集上运行时可以最小化对数据库性能的影响。
安装 Percona Toolkit首先,你需要安装 Percona Toolkit。可以使用包管理器进行安装,例如在 Ubuntu 上:sudo apt-get install percona-toolkit。或者在 CentOS 上:sudo yum install percona-toolkit准备归档表
确保你有一个用于存储归档数据的表。它通常与主表具有相同的结构。例如:
CREATE TABLE orders_archive LIKE orders;
使用 pt-archiver 进行数据归档
pt-archiver 可以通过命令行运行。下面是一个基本的命令示例:
pt-archiver --source h=localhost,D=your_database,t=orders --dest h=localhost,D=your_database,t=orders_archive\ --where "order_date < CURDATE()-INTERVAL 1 YEAR" --limit 1000 --commit-each --no-delete\ --user=username --password=password
- –source: 指定源数据库和表。
- –dest: 指定目标数据库和表。
- –where: 定义要归档的数据条件。
- –limit: 每次操作处理的行数(可以根据负载调整)。
- –commit-each: 每处理完一批行后提交事务。
- –no-delete: 归档后不删除源数据(如果要删除,则去掉此选项)。
- –user 和 –password: MySQL 的认证信息。
选项说明
- –no-delete: 如果你只想复制数据而不删除源数据,请使用这个选项。否则,pt-archiver 默认会删除已归档的数据。
- –progress: 可以添加此选项以显示进度,例如 –progress 1000 会每处理 1000 行显示一次进度。
- –dry-run: 如果想先测试命令而不实际执行归档,可以使用这个选项。
- –bulk-insert: 可以启用批量插入,以提高归档速度。
- –sleep: 可以设置在每次批量操作后休眠的时间,以减少对生产环境的影响。
验证归档结果
在运行完 pt-archiver 后,检查目标表以确认数据已正确归档:
SELECT COUNT(*) FROM orders_archive;
注意事项
- 性能影响: 尽管 pt-archiver 设计为最小化性能影响,但在生产环境中运行时仍需小心,尤其是在高负载时期。
- 备份: 在大规模删除或移动数据之前,确保数据库已备份。
- 安全性: 确保在命令中使用的用户名和密码的安全性,尤其是在生产环境中。
通过这些步骤,你可以使用 Percona Toolkit 中的 pt-archiver 工具高效地对 MySQL 数据进行归档。


