文章内容如有错误或排版问题,请提交反馈,非常感谢!
InfluxDB简介
InfluxDB是一个开源的时间序列数据库,专门设计用于处理高写入和查询性能的时间序列数据。这类数据通常包括物联网(IoT)传感器数据、应用程序性能监控数据、实时分析和事件数据等。InfluxDB提供了强大的存储和查询能力,支持实时数据的收集、存储、分析和可视化。
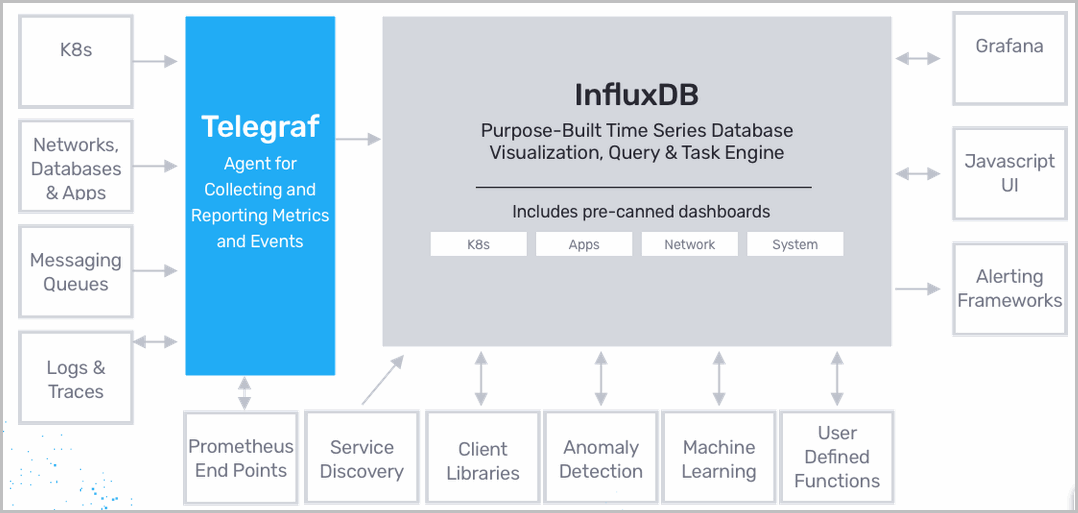
核心特性
- 时间序列数据模型:
- 专门设计用于处理时间序列数据,数据点由时间戳、字段和值组成。
- 支持标签(tags)用于元数据存储,便于数据的高效查询和过滤。
- 高性能写入和查询:
- 支持高吞吐量的数据写入,能够处理每秒数百万个数据点。
- 提供优化的查询引擎,支持复杂的查询、聚合和下钻操作。
- 内置支持的时间序列函数:
- 提供丰富的内置时间序列函数,如聚合、变换、窗口函数等。
- 支持实时计算和分析,适用于监控和报警场景。
- 数据保留策略:
- 支持数据保留策略(Retention Policies),自动管理数据的生命周期。
- 用户可以定义数据的保留期限,自动删除过期数据,节省存储空间。
- 时序数据压缩:
- 提供高效的数据压缩算法,减少存储需求。
- 支持差分编码和其他压缩技术,提高存储效率。
- 集成和扩展:
- 提供多种客户端库和工具,支持与其他系统和语言的集成。
- 支持插件机制和扩展,增强数据库功能。
应用场景
- 物联网(IoT)数据监控:
- 收集和存储大量传感器数据,支持实时监控和分析。
- 提供高效的数据查询和聚合,适用于设备状态监控和故障检测。
- 应用性能监控(APM):
- 监控应用程序和基础设施的性能指标,如CPU使用率、内存消耗、请求延迟等。
- 支持实时报警和历史趋势分析,帮助优化系统性能。
- 实时分析和可视化:
- 支持实时数据分析和可视化,适用于金融、物流、能源等行业的实时决策。
- 提供丰富的可视化选项,帮助用户理解和利用数据。
- 日志和事件数据处理:
- 处理和存储大规模日志和事件数据,支持复杂的事件查询和分析。
- 提供实时的事件流处理能力,支持事件驱动的应用程序。
InfluxDB的架构
InfluxDB是一个专为处理时序数据而设计的开源数据库,广泛应用于监控、物联网(IoT)和实时分析等领域。其架构设计旨在高效存储和查询时间序列数据。
核心架构
- 时间序列存储引擎
- 时间序列数据模型:InfluxDB使用键值对的形式存储时间序列数据,每个数据点由时间戳、字段和值组成,支持丰富的数据类型。
- 测量(Measurements):类似于传统数据库中的表,用于组织时间序列数据。
- 标签(Tags):用于对数据进行索引和过滤的元数据,通常用于标识数据的来源或类别。
- 字段(Fields):实际存储的数据值,支持多种数据类型(如整数、浮点数、字符串等)。
- 存储引擎
- TSM(Time-Structured Merge Tree):InfluxDB使用TSM存储引擎来优化时间序列数据的写入和查询性能。TSM文件支持高效的压缩和快速读取。
- WAL(Write-Ahead Log):在将数据写入TSM文件之前,数据会先写入WAL,确保在系统崩溃时数据不会丢失。
数据写入和查询
- 写入路径
- 高效写入:InfluxDB设计为高效地处理大量数据点的快速写入,适合高频数据采集。
- 批量写入:支持批量写入以提高性能和吞吐量。
- 查询语言
- InfluxQL:类SQL的查询语言,专为处理时间序列数据设计,支持聚合、分组和降采样等操作。
- Flux:一种更加灵活和功能强大的脚本语言,支持复杂的查询、数据转换和分析。
高可用性和扩展性
- 集群模式(企业版):支持集群部署,实现数据的高可用性和负载均衡。
- 复制和分片:通过数据复制和分片,InfluxDB能够在多个节点上分布存储数据,提高系统的可用性和扩展性。
数据保留和降采样
- 保留策略:用户可以定义数据保留策略,自动删除过期数据,以节省存储空间。
- 连续查询:支持定义连续查询,自动计算和存储降采样数据,优化存储和查询性能。
安全性
- 身份验证和授权:支持用户身份验证和基于角色的访问控制,确保数据安全。
- TLS加密:支持数据传输的TLS加密,保护数据的机密性。
生态系统和工具
- Telegraf:官方的插件驱动的数据采集代理,支持从多种数据源采集数据并写入InfluxDB。
- Chronograf:用于可视化和监控的用户界面,支持创建仪表盘和警报。
- Kapacitor:流式数据处理引擎,支持实时数据处理和警报。
InfluxDB与TimescaleDB的对比
TimescaleDB和InfluxDB都是流行的时序数据库,但它们在架构设计、功能特性和使用场景上存在一些显著的区别。

以下是对这两种数据库的对比:
架构与基础技术
- TimescaleDB:
- 基础:构建在PostgreSQL之上,扩展了PostgreSQL的功能以优化时序数据的存储和查询。
- 数据模型:利用 PostgreSQL 的关系型数据模型,支持丰富的数据类型和复杂的查询。
- 存储引擎:通过分片(chunking)和压缩技术优化时序数据的存储和查询性能。
- InfluxDB:
- 基础:专为时序数据设计的数据库,具有独立的存储引擎。
- 数据模型:时间序列数据模型,使用键值对存储数据点,支持测量、标签和字段。
- 存储引擎:使用 TSM(Time-Structured Merge Tree)优化数据写入和查询。
查询语言
- TimescaleDB:
- SQL 支持:完全支持 SQL 查询,用户可以利用 PostgreSQL 的强大功能进行复杂查询、联接和分析。
- 扩展函数:提供了专门用于时序数据的 SQL 扩展函数,例如时间聚合、降采样等。
- InfluxDB:
- InfluxQL:类 SQL 查询语言,专为时序数据设计,支持聚合、分组和降采样。
- Flux:更强大和灵活的脚本语言,支持复杂的查询和数据转换。
性能和扩展性
- TimescaleDB:
- 性能:通过优化的存储机制和索引技术,提供高效的写入和查询性能。
- 扩展性:支持水平扩展,通过 TimescaleDB 的多节点功能实现分布式部署。
- InfluxDB:
- 性能:专为高频数据写入优化,能够处理大量数据点的快速写入。
- 扩展性:企业版支持集群部署,实现高可用性和负载均衡。
数据保留和管理
- TimescaleDB:
- 数据保留:通过 PostgreSQL 的表分区和 TimescaleDB 的自动化管理工具进行数据保留和管理。
- 数据压缩:支持数据压缩以减少存储空间。
- InfluxDB:
- 保留策略:用户可以定义数据保留策略,自动删除过期数据。
- 连续查询:支持定义连续查询进行数据降采样。
生态系统和集成
- TimescaleDB:
- PostgreSQL 生态:可以利用 PostgreSQL 丰富的生态系统和工具。
- 兼容性:支持与其他 SQL 数据库和工具的集成。
- InfluxDB:
- TICK Stack:与 Telegraf、Chronograf 和 Kapacitor 集成,提供数据采集、可视化和处理的完整解决方案。
- 插件支持:通过 Telegraf 支持多种数据源的集成。
使用场景
- TimescaleDB:
- 适用场景:适合需要复杂查询和分析的应用场景,如金融数据分析、物联网数据处理等。
- 优势:利用 SQL 的灵活性和 PostgreSQL 的功能,支持复杂数据模型和分析需求。
- InfluxDB:
- 适用场景:适合需要高频数据写入和实时监控的场景,如系统监控、传感器数据收集等。
- 优势:高效的写入性能和专门针对时序数据优化的查询能力。
TimescaleDB 和 InfluxDB 各有其优势和适用场景。选择使用哪种数据库通常取决于具体的需求,例如数据模型的复杂性、查询需求、写入性能和生态系统的支持等。对于需要复杂 SQL 查询和强大分析功能的场景,TimescaleDB 是一个不错的选择;而对于需要处理大量时序数据且关注写入性能的场景,InfluxDB 则可能更为适合。
参考链接:


