Graphite 是处理可视化和指标数据的优秀开源工具。它有强大的查询 API 和相当丰富的插件功能设置。事实上,Graphite 指标协议(metrics protocol)是许多指标收集工具的事实标准格式。然而,Graphite 并不总是一个可以简单部署和使用的工具。由于设计方面的原因,加上它使用过程中涉及大量的小 I/O 操作,在规模化应用中会遇到一些问题,而且部署起来可能有点麻烦。
Graphite 是一个 Github 项目,没有自己的独立域名网站,文档也 host 在专门存放文档的网站上。
Graphite 基于 Python,由三部分组成:
- Carbon:基于 Twist 的 TCP Server,负责接收数据,用简单到死的文本协议,因为够简单,所以 Yammer Codahale Metrics、Netflix Servo、StatsD、Collectd、Logstash,人人都有一个到 Graphite 的插件。
- Whisper:类库,将数据存储成 RRD (round-robin-database) 文件,数据粒度随时间递减,可以存储更长时间的其据。其继承者是Ceres,不再固定文件大小。
- Graphite-Web:基于 Django 的 Web 应用,支持Restful 的 URL 获取图片或 JSON 数据,URL 里可以带各种有用的函数。
基于 Python 的单点性能可能不高,但 Graphite 有 Cache、HA、Scalable 方面的专门设计。
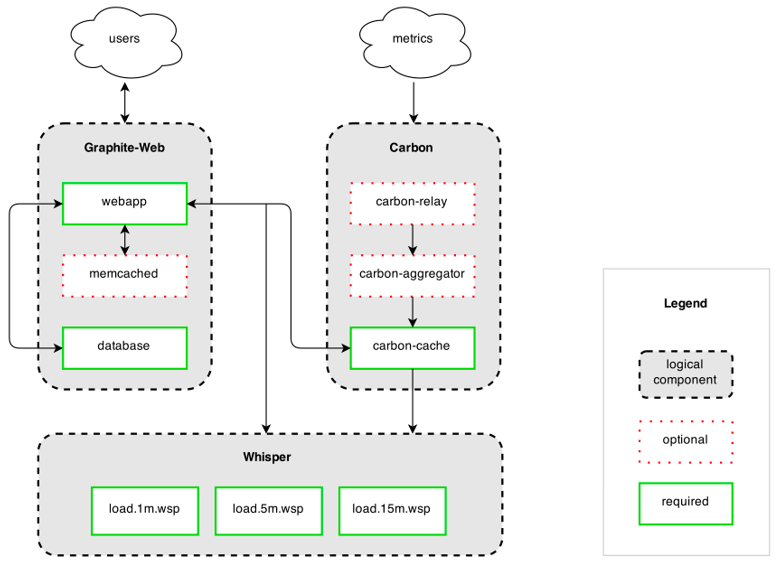
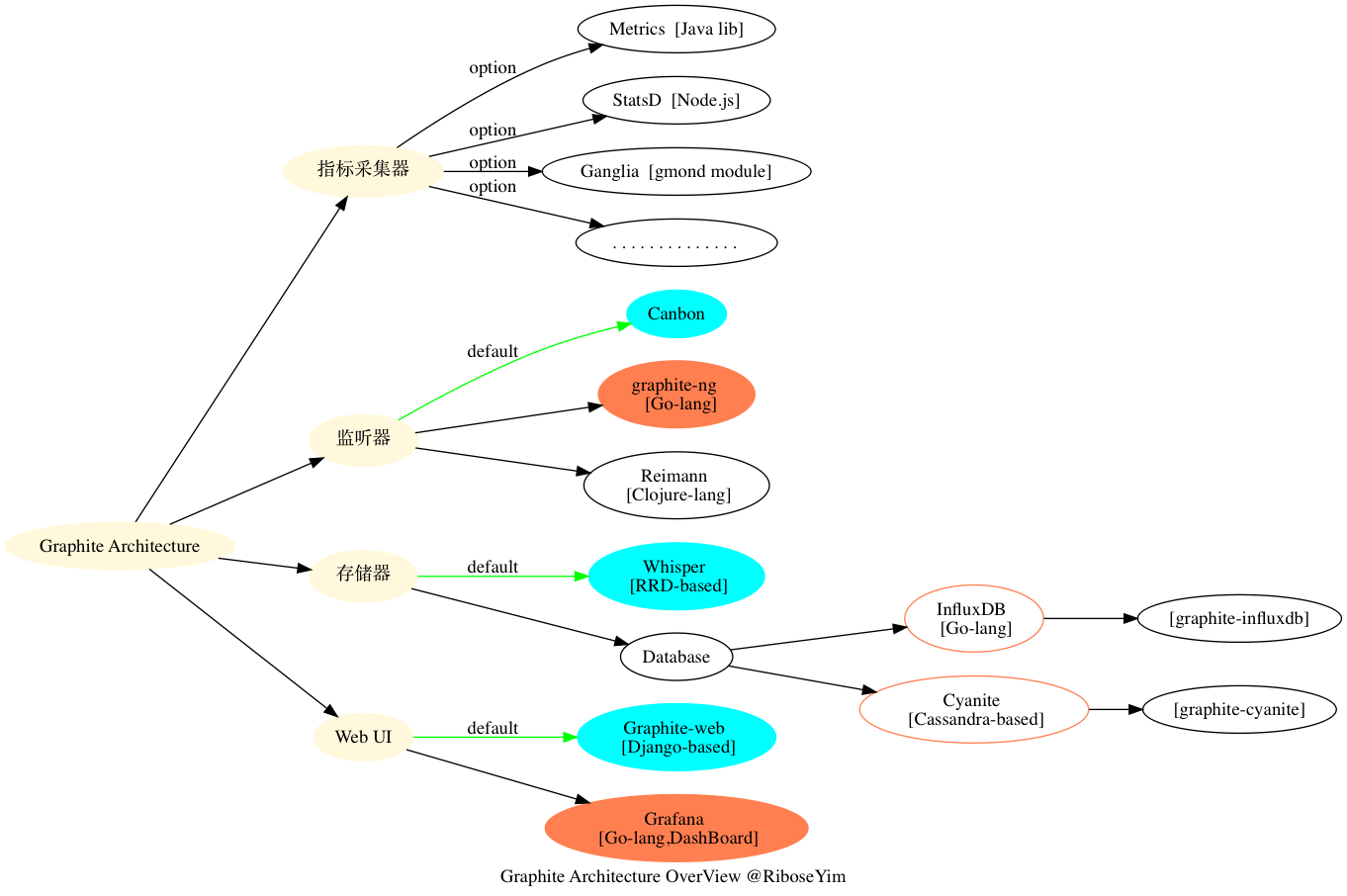
虽然 Graphite 包含三个组件可能会导致一些实施的问题,但也有积极的成果。每一个模块都是一个独立的单元,这样你就可以按照实际的需要混合和匹配使用三个组件中的哪一个。同时意味着您可以为自己构建一个完全定制化的 Graphite 部署方案。
对于 Graphite 的每一个组成部分来说,都可以是一个 Graphite 的方案或者是非 Graphite 的替代品。
指标采集器:Dropwizard Metrics, StatsD
Graphite 部署方案中的第一个步骤根本不是 Graphite 的组成部分。这是因为 Graphite 自身并不支持采集任何指标;Graphite 需要有人将指标数据发送给它。这通常不是一个特别大的限制,因为大多数指标采集器都支持以 Graphite 格式提供指标数据,但仍然有一些东西需要注意。我们可选的不同指标采集器可以列一个庞大的列表,但是没有一个工具是包含在基础 Graphite 中的。
选择你的指标采集器 – Graphite 文档中提供了一个工具列表,包括流行的选择像 CollectD 和 Diamond,但它很少更新,所以你还可以考虑以下两个方案:
- Dropwizard Metrics 是一个 Java 库,通过一系列指标为你提供生产环境的可视化。它有一个 Graphite Reporter,可以将所有的指标数据发送到 Graphite 实例。对于需要在 Java 生态中使用 Graphite 的场景来说,它是一个不错的选择。
- StatsD 是一个基于 js 运行的网络守护进程,来自 Etsy (网络电商平台)。它可以监听一系列统计、指标数据,并将它们聚集到像 Graphite 这样的工具中。StatsD 也可以和很多其他的可视化、指标采集工具一起工作。
Graphite 不和特定的指标采集器捆绑。然而,Graphite 指标协议是非常常见的,因此不难找到一个或多个与您的应用程序一起工作的协议。既然有这么多的指标采集器和 Graphite 配合良好,你不需要只选择一个,你可以选择从多个数据源发送指标。
监听器:Carbon, graphite-ng, and Riemann
Graphite 的另一部分是用于监听发送的指标数据并将其写入磁盘的组件:Carbon。Carbon 是由守护进程组成的,在工作方式方面有一些内置的灵活性。在基本的小规模部署中,Carbon 守护程序会监听指标数据并将它们报告给 Whisper 存储数据库。然而,随着规模的增长可以添加一个聚合元素(Aggregation),它在一段时间内缓冲指标数据,然后将它们发送给一个大块中的 Whisper。你也可以使用 Carbon 传递指标副本到多个 Carbon 后台。当你达到更高的规模、需要多个 Carbon 后台程序来处理传入的指标数据时,这一点特别有用。缺点和潜在的问题:人们通常遇到的问题通常跟规模相关。就规模应用而言,Carbon 有以下几个缺点:
- 一个单独的 Carbon 守护程序处理能力有限,因为它是用 Python 语言设计的。本机代码不支持一次多个线程同时运行(Multiple threads),所以可能出现 Carbon 守护程序刚刚启动时丢弃指标数据的情况。
- Carbon 有一个它一次能处理负载数量的阈值,但这个阈值并没有传达给你。
- Carbon 并没有持续打开 Whisper 的文件句柄,所以存储每个指标都需要多步的完整读/写序列。
基于标准的 Graphite 部署实例中,这些情况的解决方法是将工作划分为中继器(Carbon relays)和缓存(Carbon caches)。尽管如此,您仍然需要注意负载,因为超过了 Carbon 的负荷会导致数据丢失。如果这个后果对你来说无法接受,可以看看 Carbon 的替代解决方案。
Carbon 替代方案:
- graphite-ng,本质上是基于 Go 语言重写了一遍 Carbon,以解决上面提到的几个问题。迄今为止,该项目的重点是改进 Carbon 的中继和聚合功能。如果你喜欢 Carbon 的功能,但是又想要绕过一些性能方面的限制,这是一个不错的选择。
- Reimann,基于 Clojure 语言实现(属于 LISP 编程语言家族),Reimann 是用来聚集和处理“事件流(event streams)”。事件和流都是相当简单的概念,Riemann 能代替 Carbon 把它们发送到 Graphite 实例。它在这个过程增加了一些提供了额外的好处,例如告警功能。如果你想设计一个远离 Carbon 的架构,这是一个很好的选择,还能加入一些涉及告警方面的能力。
存储数据库:Whisper, InfluxDB, Cyanite
您需要选择的下一个组件是存储数据库。在 Graphite 体系结构中称之为 Whisper。Whisper 是一种固定大小的数据库,用于存储时间序列数据,在保存和取样方面提供了相当的精确度。在标准的 Graphite 部署中,Carbon 将指标值写入 Whisper 存储,用于在 Graphite-web 组件中实现可视化。
缺点和潜在问题:Whisper 基于 RRD(Round-Robin Database),但写入操作的时候有一些关键性的差异,例如回填项目历史数据和处理不规则数据的能力。这里有一些指标和可视化工具的有用特性,但它们的实现都是基于某种折衷。
- 因为 Whisper 是用 Python 编写的,所以相对来说性能较慢;
- 按照 Whisper 的设计,它会遇到一些存储空间的问题,因为每个指标都需要一个文件,并且都是单个实例。这是一种有意的权衡,以实现前面提到的一些好处,但不可否认,Whisper 对磁盘空间的利用效率较低。
- 由于 Carbon 和 Whisper 在设计方面的原因,它们最终都涉及到大量的 IO 请求。当你超越小型部署时,磁盘 IO 的伸缩能力会成为摆在面前的一个问题。
Whisper 替代方案:
- Influxdata(InfluxDB)是一个基于 LevelDB、用 Go 语言编写的时间序列数据库。influxdata 能够解决一些磁盘 IO 写优化问题,同时不要求 one metric=one file。influxdata 支持 Carbon 使用的协议,使它能够悄悄置换 Whisper,实现类似 SQL 的查询语言。甚至已经有一些项目设计用来使 influxdata 的置换更简便易行,例如 graphite-influxdb 项目,使得可以和 Graphite 的 API 无缝衔接。influxdata 属于非常有前途的新兴项目,可以在广泛的范围内与其他工具一起工作。
- 基于 Cassandra 的存储数据库。得益于graphite-cyanite 项目的工作,基于 Cyanite 数据库可以很容易实现这一目的。Cyanite 的开发规划目标就是在 Graphite 体系结构中替换 Whisper,这意味着它可以和 Carbon、Graphite-web 一起工作(需要少量的一些依赖)。使用 Cyanite 有助于解决 Whisper 在大规模部署场景中存在的性能和高可用问题。
Graphite 体系结构中,数据存储组件是 Whisper。在大规模应用中,除非你在硬件方面大量投入、把它分解成复杂的手动集群模式,否则将悄悄地会遇到一些性能和可用性问题。如果你需要关注这些问题,可以使用数据库的替代选项来提高性能和可用性。
可视化组件:Graphite-Web 和 Grafana
一旦你收集并存储了指标数据,就下来的步骤就是可视化它们。Graphite-web 的角色就是提供可视化。Graphite-web 是一种基于 Django 的 Web 应用程序,提供指标数据可视化和交互能力。它在数据的处理方面提供了相当多的能力,但可视化组件并不十分美观(也就是说“土”、“丑”)。Graphite-web 作为前端组件,我们将着重讨论用户体验的相关内容。
Graphite-web 替代方案:
归功于卓越的 Graphite API,目前有一系列第三方仪表盘工具可以支持 Graphite。因为有如此众多的可视化选项,它们的优劣其实主要取决于个人品味,再次不作过多扩展,但我确实想特别指出其中的一个。也许最具潜力的 Graphite 可视化替代方案,或至少是人们谈论最多的是 Grafana。
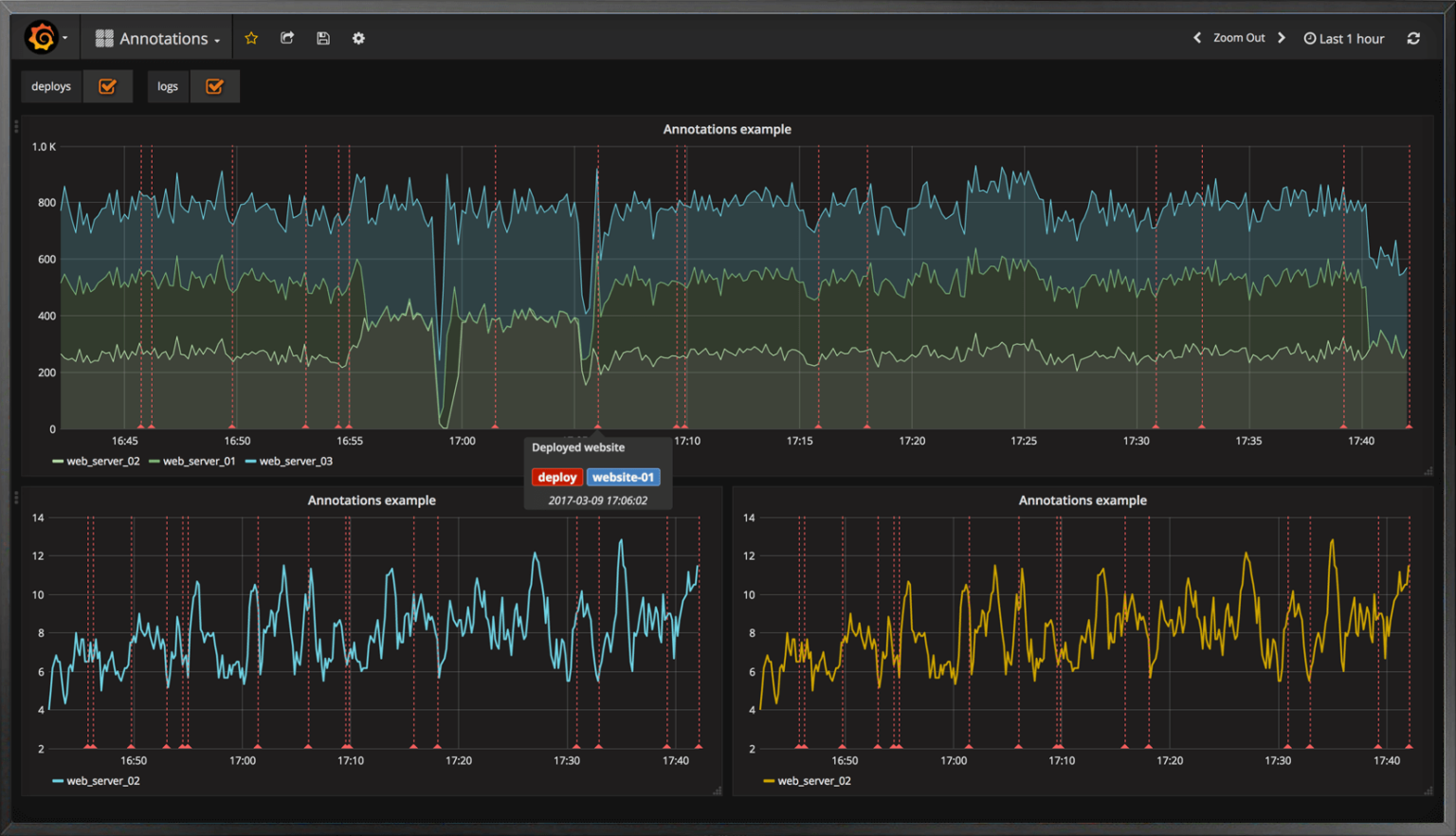
Grafana 是一个开源的仪表盘工具,可以兼容 Graphite 和 InfluxDB。Grafana 曾经只是一个基于 Elasticsearch 存储的前端仪表盘工具,从 V2.0 版本开始,它拥有了一个支持用户自定义的后端存储组件。Grafana 在设计之初即考虑到支持 Graphite 创建更加优美的可视化组件,因此它非常适合替换默认的 Graphite-web。Grafana 功能相当丰富,性能稳定。Grafana 拥有一个后端组件,如果你也可以找到纯粹的前端工具,Graphite 文档中提供了工具列表。
如果你觉得 Graphite 提供的默认可视化效果过于基础和乏味,有大量的可视化替代方案可以选择。其中一些是纯粹客户端,有的包含一个存储你建立的仪表盘后端组件。不管你要什么,你都能在这里找到东西。
代码级指标–Trends
OverOps 发布了一个新的功能,可以让你把代码级指标从 JVM 应用程序中的错误、与变量状态在一起发送到 Graphite。详细:https://www.overops.com
总结
所有针对 Graphite 的投诉都集中于(它的工作性能不够稳定,仪表盘丑陋!规模化部署是硬伤!),但不妨碍它成为一个很流行的工具。如果你想要一个开源的指标和可视化工具,为许多企业级工具提供支持,那么 Graphite 值得一试。其中最重要的一点是,你可以自定义数据内容。Graphite 并不是由完全特定的组件一起工作,其中的乐趣何在?经过一些尝试和错误,您可以在您自己的环境中构建一个完全定制化的、非常有用 Graphite(或类似 Graphite 的)部署方案。
参考链接:


