什么是 Google Search Appliance
Google Search Appliance 是先前 Google 销售的一款小型搜索服务器,可以帮助你快速的搭建一套搜索引擎系统。它实际了一款个小型的 Google,里面包含的 Google 的搜索算法等,你可以用它来做自己的站内搜索引擎,但更加有用的是你可以通过这台机器去研究 Google 蜘蛛的运行规律,去改变网页上的内容来达到最佳的 SEO 效果等。以下内容来自官方文档。

Google Search Appliance 抓取队列
抓取队列是设备等待抓取的网址以及已到抓取时间的网址的集合。该信息可帮助您确定在恰当时间是否正在抓取特定主机,以及为什么来自某文档的信息比其他信息要新等。
抓取队列的快照会显示在获取快照之前等待被抓取的网址。每一快照都包含以下信息:
| 项目 | 说明 |
| PageRank | 要抓取的资源的网页排名。网页排名是影响资源在队列中位置的因素之一,它会让较重要文档的抓取频率高于较不重要的文档。请注意,在导出快照时不会包含网页排名信息。 |
| 上次抓取时间 | 最后一次抓取该网址的时间。 |
| 下一个预定时间 | 预定抓取资源的时间。该时间可能会改变,并且受网页排名、队列到期项目状况及其他因素的影响。过期项在被抓取前显示为红色。如果您一直看到同一到期项,则可能需要进一步进行调查。
只有在首次抓取了网址之后,才会显示下一个预定时间。 |
| 更改间隔 | 希望对这一网络资源进行更改的频率。首次抓取之后,设备将所有网址的更改间隔初始化为两天。
然后,设备会根据网址的实际更改频率调整更改间隔。 设备在每次抓取网址时都会了解在上次抓取后该资源是否发生过更改。如果资源已更改,更改间隔会缩短。如果资源未发生更改,更改间隔会延长。 您可以使用抓取频度调节功能更改这一计算过程。 只有在首次抓取了网址之后,”更改间隔”才会出现。 |
| 网址 | 所含内容被抓取的网络资源。 |
对 SEO 的启示:
- PageRank 会影响抓取频率
- 抓取频率受页面本身的更新频率影响
Google Search Appliance 搜索日志
搜索日志记录了从索引获取信息的用户请求。您可以生成并导出这一信息,然后将其输入喜欢的日志分析软件或报告软件。
下面是搜索日志可提供的信息的一些示例:
- 用户执行了哪些类型的查询?
- 用户点击了用户界面的哪些部分?
- 为用户提供服务的速度如何?
- 用户得到所需结果了吗?
- 您需要通过配置相关查询、关键字匹配、查询扩展或单一框功能帮助用户查找相关信息吗?
“高级搜索报告”中的每个条目表示用户在 Search Appliance 用户界面(搜索页或结果页)上的一次点击。每个条目由以下项的值组成:
- 以百分之一秒为单位的点击时间
- 做出点击的用户的 IP 地址
- 会话 ID 的占据位置,始终为空
- 点击类型,如下表所述
- 点击起始页(用户点击得到的结果页)
- 点击排名(用户点击得到的结果页的排名)
- 点击数据,通常为空
- 查询(返回结果的用户查询)
- 用户点击的网址
下面的例子显示了高级搜索报告中的一个条目:121331555476,172.18.75.121,,onebox,0,0,,hobo,http://www.tropo.com/
下表描述了 Search Appliance 内置的点击类型:
| 点击类型 | 说明 |
| 高级 | 搜索页上的高级搜索链接 |
| advanced_swr | 对其他文字的高级搜索 |
| c | 搜索结果 |
| 缓存 | 结果页上的缓存文档 |
| 集群 | 结果页上的集群标签 |
| db | 结果页上的数据库内容 |
| desk.groups | 搜索页顶部的论坛链接 |
| desk.images | 搜索页顶部的图片链接 |
| desk.local | 搜索页顶部的本地链接 |
| desk.news | 搜索页顶部的资讯链接 |
| desk.web | 搜索页顶部的网络链接 |
| 帮助 | 搜索页上的搜索提示链接 |
| 关键字匹配 | 结果页上的关键字匹配 |
| 徽标 | 超链接徽标 |
| nav.next | 导航,下一页 |
| nav.page | 导航,特定页 |
| nav.prev | 导航,上一页 |
| 单一框 | 结果页上的单一框 |
| sitesearch | 结果页上的”更多结果来自…链接” |
| 排序 | 结果页上的排序链接 |
| 拼写 | 拼写建议 |
| 同义词 | 结果页上的相关查询 |
| 其他 | 未注解链接 |
对 SEO 的启示:
- 用户在搜索结果页的操作可能影响后续的排名
Google Search Appliance 查询扩展
查询扩展可让 Search Appliance 自动向用户的搜索查询添加额外字词,以返回更多相关结果。使用查询扩展时,Search Appliance 可扩展两类字词:
- 用户给出的词的同词干词。例如,如果用户查找”engineer”,Search Appliance 能向查询中添加”engineers”。
- 一个或多个以空格分隔的字词(与用户提供的词互为同义词或与密切相关)。例如,如果用户搜索”FAQ”,设备可能将”frequently asked questions”添加到该查询,或者如果用户输入”office building”,查询可能扩展到包含”office tower”。
每个前端都具有相应的策略,用于指定是否使用 Search Appliance 的内置逻辑(”标准”字词集)、您自己的同义词列表(”本地”字词集)或同时使用二者(”完全”字词集)。
标准字词
默认情况下,会以英语、法语、德语、意大利语、葡萄牙语和西班牙语提供 Search Appliance 查询扩展字词。逻辑会考虑查询中字词的上下文,并可能在一个查询中将某个字词与它的同义词匹配,而在另一个查询中却不这么做。
本地字词
本地查询扩展策略由两种文件构成:同义词文件和黑名单文件。您可以使用一种类型的文件,也可以同时使用两种类型的文件,还可以创建最多含有 100 个文件的组合文件。
本地同义词对于配置网站特有的术语表很有用。下面是一些示例:
- 部件制造商可以配置将作废部件号与替代部件号进行匹配的同义词。对旧部件感兴趣的用户将也会收到新部件的相关信息。
- 大学可以通过配置同义词将课程缩写扩展成全称。例如,关于 CS101 的查询可以包含从 computer science 101 得到的结果。
- 制造商可以配置其产品大类的相关查询,以便加入其产品名的查询。
您可以通过创建黑名单控制查询扩展。黑名单是从查询扩展中排除的一组字词。黑名单可用于删除不想要的搜索结果,这些搜索结果源自与您环境中使用的特殊字符匹配或阐明了它们的同义词。假设您为生产名为“Glue”的产品的软件公司管理设备,该产品能够实现不同软件组件的交互。您可以在黑名单中添加“glue”,以确保用户查询不会扩展到“adhesive”。
请注意:包含特殊字符与符号(&)和下划线(_)的同义词被视为有效,并且其结果会得以扩展。
对于使用所支持语言的客户,我们提供了预配置本地同义词文件。英语文件名为 Google_English_stems,法语文件名为 Google_French_stems,依此类推。默认情况下,这些文件会出现在查询扩展文件列表中。每个文件都包含一组可作为标准字词补充的常用字词。您可以照“原样”使用预配置本地文件;也可以下载文件并进行修改,然后将修改后的文件上传;还可以禁用该文件。不过,您不能删除这些文件。
对 SEO 的启示:
- 做关键词优化前吗,需要确定是否有扩展关键词
Google Search Appliance 过滤器
通过服务>前端>过滤器页,按前端限制用户的搜索。您可以使用以下过滤器和策略:
- 域-将搜索限制在一个或多个域名(并非 IP 地址)
- 语言-将搜索限制在所有语言或所选择的一组语言
- 文件类型-将搜索限制在一个或多个文件类型,例如 HTML、PDF 等等
- 元标记-按元标记中的值和值类型过滤搜索,您可以通过元标记过滤搜索结果,通过使用“all”或“any”、值类型和值做出限制。
- 查询扩展策略-选择这样一种策略,该策略决定了利用同义词时查询所扩展的程度
- 结果自定义调整政策-选择一种影响 Search Appliance 评定文档与用户搜索查询
相关性方式的政策
如果您在前端(通过元标记过滤器区域)设置了元标记过滤器,Search Appliance 将会把这些设置作为 requiredfields 和 partialfields 输入参数附加到搜索查询中。如果您在前端以及在 requiredfields 和 partialfields 输入参数中都设置了元标记过滤器,那么前端设置将覆盖您添加到搜索查询中的任何输入参数。下表列出了前端元标记值类型,以及 Search Appliance 附加到每个值类型的搜索请求中的输入参数。
| 前端值类型 | 输入参数 |
| 精确 | requiredfields=name:value |
| 部分 | partialfields=name:value |
| 存在 | requiredfields=name |
查询扩展策略:使用查询扩展策略为用户搜索查询提供更丰富的结果集。利用查询扩展,设备可以向用户输入的搜索查询中添加同义词。您可以使用内置同义词集,或提供您自己的同义词集,也可以结合使用内置字词和您自己的同义词。如果您使用“本地”或“完全”查询扩展,则还可以利用黑名单阻止指定字词的扩展。
对 SEO 的启示:
- HTML 页面标识语言
- 优先精确匹配
Google Search Appliance 相关查询
您可以使用“相关查询”将替代字词或短语与指定的搜索字词关联起来。当用户输入指定的搜索字词时,替代字词将作为建议显示出来。用户可以点击建议的替代字词开始另一次搜索。例如,如果用户搜索“Mark Twain”,搜索结果将建议搜索“Sam Clemens”。如果用户搜索“File Transfer Protocol”,搜索结果将建议搜索“FTP”。除非您使用 XSLT 样式表修改文本,否则相关查询会显示在搜索页上“您还可以尝试”的后面。
仅当用户的搜索字词与您的指定完全相同时,才会在搜索结果页上作为建议显示相关查询。相关查询不适用于部分搜索字词。例如,如果您将相关查询“Sam Clemens”与搜索字词“Mark Twain”关联,当用户查询“Mark Twain stories”时,搜索结果不会给出建议“Sam Clemens stories”。
相关查询是单向执行的。如果您指定字词 B 是字词 A 的相关查询,在用户搜索字词 A 后,搜索页会显示尝试搜索字词 B 的建议。但如果用户搜索字词 B,就不会显示建议。要创建双向关联,您可以指定两个查询,这样每个字词都是另一个的相关查询。
在相关查询页上,您可以输入搜索字词并指定想要向用户建议的相关查询。搜索字词和相关查询可以是字词或词组。
示例:
| 搜索字词 | 相关查询 |
| NATO | 北大西洋公约组织 |
| 北大西洋公约组织 | NATO |
| Mark Twain | Sam Clemens |
| Sam Clemens | 无 |
对 SEO 的启示:
- 相关查询是单向的
Google Search Appliance 关键字匹配
利用关键字匹配,您可以在自己网站上宣传特定网页。例如,如果某个部门将要发布新的“运营”网页,而该网页应在进行某类查询时返回,则您可以在特定搜索字词(例如运营)与这一新网页间建立关联,从而将用户定向到这一新的网页。在查询包含字词运营时,会返回该新网页的链接,并且该链接会显示在搜索结果旁边(如同文字广告一样)。如果网页尚未成为“生产索引”的一部分,或者指向网页的链接很少,从而造成网页在结果列表中出现的位置低于您希望的位置,则该功能对于直接提高这些网页的点击量特别有用。
要创建关键字匹配,您必须提供返回特定结果时所用的“字词” 、“词组” 或“完全匹配” 标准。创建关键字匹配的规则如下所示:
| 关键字匹配类型
|
标准(不区分大小写)
|
如果搜索查询是“Abraham Lincoln” | 关键字匹配的原因 |
| 关键字匹配 | 必须出现在查询中某一位置的字词。 | 关键字匹配=“Abraham”和“Lincoln” | 如果您的关键字匹配为“Abraham Lincoln”,则搜索查询必需同时包含“Abraham”和“Lincoln”才能触发该关键字匹配。
要获得“Abraham”或“Lincoln”的关键字匹配,请输入两个关键字匹配:一个用于“Abraham”,另一个用于“Lincoln”。 |
| 词组匹配 | 出现在查询中任何位置的词组。对于匹配的词组,所有字词都必须出现,并且字词的顺序应相同,中间没有插入的字词,还要与查询中的所有连字符匹配。 | 词组匹配=“Abraham Lincoln”、“President Abraham Lincoln”、“Abraham Lincoln president”和“young Abraham Lincoln” | 由于字词是按照您在搜索查询(“Abraham Lincoln”)中输入的顺序显示的,因此这些都是词组关键字匹配。由于“the Tall”将词组“Abraham Lincoln”中的两个词分开,因此“Abraham the Tall Lincoln”不是词组匹配。 |
| 完全匹配 | 词组应与查询完全匹配。 | 完全匹配=“Abraham Lincoln” | 只有“Abraham Lincoln”与查询是完全匹配。“President Abraham Lincoln”和“Abraham Lincoln’s”不是完全匹配。 |
对于每个“字词”、“词组”或“完全匹配”,您最多可以提交五个指定的网址。不过,默认情况下,每一搜索最多只会返回三个关键字匹配。如果您希望将这一数字增加为五个,可以使用 XML 参考文档中提供的 numgm 参数。
Google Search Appliance 集合
抓取工具访问您在抓取并编制索引 > 抓取网址页输入的网址和网址格式并为其编制索引。结果索引是您在抓取并编制索引 > 集合页看到的默认集合(default_collection)。
管理员可以创建作为完整索引子集的文档集合。每个集合都是由一组网址格式定义,其中涵盖了该集合中文档的网址。您也可以导入某个以前从系统导出的集合配置。
集合让您的用户得以搜索索引的特定部分。例如,您可以创建产品集合或人力资源集合,以便实现仅对您索引中的产品或人力资源部分进行搜索。
Search Appliance 的集合数量上限是 1500,超过这个集合数目可能导致服务失败。重置索引可解决此问题。
默认集合
除了您创建的集合,在默认情况下,Search Appliance 还会针对以下内容创建集合:
- 完整索引(您可以自行选择是否对用户公开)
- 基于语言的网页,支持仅搜索特定语言的网页
- 元标记 – 支持仅搜索具有特定元标记名称或名称值对的网页
搜索集合
对单个集合的搜索结果与完全索引搜索有相同的相关性排名。因为它被限制为搜索单个集合的内容,所以只是搜索内容的不同。
使用页面布局助手,您可以自动修改搜索表单,从而纳入按集合搜索菜单。
对集合进行搜索:要将搜索过程限制到已定义的集合,需要向搜索查询的网址中添加以下内容:&site=COLLECTION_NAME
- 示例:在集合“Human_Resources:”中对“度假”的搜索:http://www.google.cn/search?q=度假&output=xml&client=yoursite&site=human_resources。该搜索仅返回 Human_Resources 集合的网址中的度假结果。
- 在集合“Development”和“Marketing”中搜索“产品”:http://www.google.cn/search?q=产品&output=xml&client=yoursite&site=(development)|(marketing)。对于“product”的搜索结果来自于 Development 或 Marketing 集合。
Google Search Appliance 抓取频度调节
在“抓取频度调节”页上,您可以对不同网址的抓取时间进行微调。您可以增加对新闻文档的抓取频度,而减少对存档文档的抓取频度。在服务器文档对 GET 请求中的 If-Modified-Since 标头响应不正确时,您也可以重新抓取那些在正常情况下不会被重新抓取的网址。
频繁抓取
您可能有经常更改的内容,更新频率为每小时一次,甚至每几分钟一次。在抓取并编制索引 > 抓取频度调节页上,您可以指定经常更改的网页的网址格式,这样就可以经常抓取它们,保证您提供的索引是最新的。
频繁更改的内容部分超载有可能降低系统性能。请尽可能减少网址数量以避免降低性能。
很少抓取
为从未更新或修改的文档编制索引,如稳定的数据库等;或为邮件或新闻存档中那些只是逐步增加的文档编制索引,您可以让抓取工具重复使用那些已抓取的网址。网址的重复使用减轻了您网络服务器上的负载。请确保可以从起始网址中访问您指定的存档网址格式,并且这些格式还存在于仅跟踪和抓取以下格式的网址框中。
始终强制重新抓取
首次抓取网址时,将为数据编制索引并存储在磁盘上。随后,为加快抓取速度并减少服务器负载,只有在 Google Search Appliance 的 If-Modified-Since 请求标头上的日期之后修改的文件才会被抓取。这些更新将添加到索引中去。
只有当您的索引中出现了过期网页时,才能在始终强制重新抓取部分输入网址格式。尽管抓取工具确实会尽力找出日期发生错误的服务器并自动做出调整,但还是可能出现其他类型的错误配置。
请确保您的服务器保持正确时间。如果您认为您的一台或多台网络服务器不支持 If-Modified-Since 选项或有配置错误,请使用此部分输入要重新抓取的网址格式。向您的网站管理员提交您的网络服务器的问题。
对 SEO 的启示:
- If-Modified-Since 的使用
Google Search Appliance 主机负载计划
抓取网址的数量上限
您的许可指定了您可以抓取的网址的上限。不过,如果您的网址尚未达到许可所规定的上限,您可以为想要抓取的网址指定较小的数量上限。如果您输入的数字小于许可指定的总页数上限,您可以提高系统性能。在您点击保存时间表和主机负载按钮后,系统最多比您指定数量多抓取约 10% 的内容系统抓取的网址要稍微多一些,这样在清除重复后,页数与您指定的上限将非常接近。
请注意:如果您将此框保留为空,系统将不断抓取网址,直至达到您的许可的上限。
网络服务器主机负载
网络服务器主机负载值指定了在各个网络服务器上为进行抓取建立的并行连接的个数上限。我们建议您从 4 个连接开始,只有当确信您的网络服务器能够处理您指定的负载时再逐渐提高该值。如果您无法确定网络服务器的负载能力,请与您所抓取网站的网站管理员联系。
对于文件服务器和对于代理服务器后面的网络服务器,设备处理主机负载的方式有所不同。在这些情况下,设备会将多个服务器视为单一主机,并将一个主机负载设置应用于所有服务器。例如,如果在有 10 个文件服务器的环境中将主机负载设置为 4,那么一次最多只能连接四个服务器,按抓取队列指定的顺序对全部 10 个服务器进行抓取。
警告:一些服务器可能无法处理高负载。
如果抓取工具认定服务器不能处理定义的主机负载,它将降低抓取速率,直到达到可接受的响应时间为止。
请注意:并行连接的数量偶尔可能低于您在此指定的值,这取决于您的系统行为。系统会尽力保持这个数量。
网络服务器主机负载例外
网络服务器主机负载例外使您通过为指定的网络服务器分配不同的主机负载上限来指定网络服务器主机负载例外。在您没有指定主机负载例外的时间段中,将应用默认的网络服务器主机负载。例如,您可能有三个网络服务器,它们可以在夜间处理更多的抓取负载。对于这三台网络服务器,从晚上 12 点到早晨 6 点设置的默认主机负载为 4,而您可以指定一个比 4 高的负载。
要尽可能减少服务器在日间的主机负载,可以对从上午 9:00 至下午 5:00 这一时间段设置例外值 0,这样服务器将不能处理额外负载。
您输入的主机名应该是完全限定的主机名,可以为 ASCII 或 IP 地址。
当使用代理抓取网站时,将使用相同的主机负载来抓取代理后面的所有网站。所用的主机负载将是针对使用代理抓取的所有网址格式指定的主机负载上限。您应该执行以下操作中的一项操作:
- 对您想使用代理来抓取的网站不指定主机负载,这种情况下会使用主机负载上限
- 指定足够小的主机负载以不影响任何代理站点的性能
以下规则也适用于本页上的条目:
- 每行只允许有一个主机名条目
- 主机负载为零(0)并不会完全停止抓取,而只是将与主机的接触次数减少为每小时大约三次
- 您可以将负载系数指定为小数值。例如,5、1 或 2.0
值 2 表示,平均每个主机只使用两个并行连接。值 .25 表示,平均只有 25% 的时间在使用与网络服务器的连接。
对 SEO 的启示:
- 服务器性能会影响抓取效率
Google Search Appliance 文档日期
利用文档日期页,您可以按文档中的日期来排列和显示搜索结果。您可以在此页定义 Search Appliance 为文档编制索引时所用的规则。
Search Appliance 可从文档的标题、正文、网址或元标记中提取日期,也可从 HTTP 服务器返回的最后修改日期中提取日期。默认情况下,会在 HTTP 标头针对所有文档返回的最后修改日期字段中查找日期。文档日期搜索还会在非 HTML 文件的正文中查找日期。
对于从标题、正文、网址或元标记中提取的日期而言,遇到的第一个最常用格式的日期即视为文档日期。已移到某个目录并按最后修改日期排序的文件可以反映复制或移动该文件的日期。
Search Appliance 可以提取以下范围内的日期:
- 开始日期:1970 年 1 月 1 日
- 结束日期:从现在起两天后
SearchAppliance 能够识别大多数格式合理的日期。不过,请不要使用仅提及年份(YY 或 YYYY)的格式,例如 2002。对于格式为月年的日期,则会假定日期为当月第一天。目前,文档日期可以识别大多数 Latin-1 月份名称,但不能识别中文、日语或韩语的月份名称。
使用日期为 ISO-8601 格式 (YYYY-MM-DD) 的元标记,以避免文档标题或正文中多个日期及多种格式所引起的混乱。
如果没有找到文件日期,编制索引时则不必包含日期数据。无日期数据的结果会显示在有日期的结果后面,并按相关性排序。
如果您的一些文档包含默认日期规则的例外情况,请输入这些文件的具体网址或格式,并将这些规则置于列表顶端。处理这些规则时,会按照规则列表中指定的顺序进行。包含文档有效日期的第一条规则会决定该文档的日期。
以下为使用 Google 管理员工具获取的文档最后修改日期:
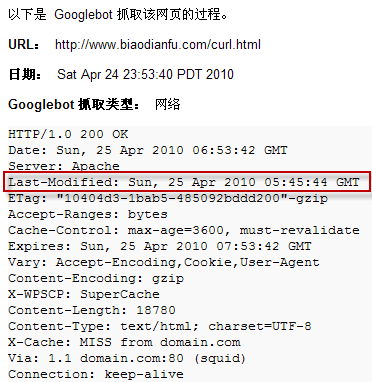
对 SEO 的启示:
- 网页的日期时间影响排名
Google SearchAppliance 对“robots.txt”文件的访问权
如果网络服务器配置为要求对所有 HTTP 或 HTTPS 请求进行身份验证,请确保创建格式与“/robots.txt”文件匹配的身份验证规则。
为了遵循“漫游器排除协议”,抓取工具将会检索 /robots.txt。如果结果是获得 HTTP 401(需要身份验证)响应代码,抓取工具将无法抓取网站上其他任何网址。如果访问 /robots.txt 的结果是 HTTP 200(成功)或 HTTP 404(未找到)响应代码,就可以对那个 HTTP 或 HTTPS 网站的内容继续进行抓取。
如果网站需要对所有请求进行身份验证,并且不存在与 /robots.txt 匹配的身份验证规则,抓取工具将会收到 HTTP 401 响应代码并且无法抓取网站上其他网址。
Google SearchAppliance 抓取时间表
在指定要抓取的网址并配置了用于抓取的服务器之后,可以通过抓取并编制索引 > 抓取时间表页选择抓取模式,对于预定抓取模式,可以指定抓取您的服务器的次数。
抓取模式
SearchAppliance 具有以下抓取模式:
- 持续抓取。如果您想让抓取工具自动查找更新内容并编制索引,请选择该模式
- 预定抓取。如果您想精确控制所有抓取的时间和持续时间,请选择该模式。当出现以下情况时,预定抓取就会结束:
- 已经超过您指定的时间限制
- 抓取工具达到了您的许可指定的文档限制
- 抓取工具达到了“抓取并编制索引 > 主机负载计划”页上“抓取网址数量上限”下设置的限制
- 抓取工具已经抓取了所有可获得网址
抓取时间表
抓取时间表允许您将抓取与发生在您的服务器上的其他任何系统活动(例如常规系统备份)结合起来。
您可以创建抓取时间表,也可以将抓取限制为指定的持续时间(以小时和分钟表示)。如果您设置抓取时间限制,抓取工具会运行指定的小时数和分钟数,或者运行到抓取了所有网址时为止。例如,如果您设置了两个小时的时间限制,并将开始时间安排为凌晨 2 点,那么除非抓取工具不到 2 个小时就完成抓取,否则它就会在凌晨 2 点到 4 点之间抓取您的服务器。
对 SEO 的启示:
- Google 的几种抓取方式:
- 漫游器,主要针对的是所有网站,它会一直运行,主要是用来收集网址。
- 针对某一网站的限时抓取,所以怎么让搜索引擎在一定时间内索引到一定的页面就是 SEO 要做的内链的构建。同时搜索引擎一般在凌晨 2 点到 4 点之间大量抓取网页也是为了减轻目标服务器的压力。
问题:服务器放在不同时区可能存在抓取时间点不在凌晨的问题
Google SearchAppliance 勿抓取以下格式的网址
以下内容为 Google SearchAppliance 勿抓取以下格式的网址自带配置,了解搜索引擎不抓取哪些网址,才能避免自己生成的网址不被搜索引擎接受,同事如果自己想要不让搜索引擎收入某些页面,也可以在 URL 中使用某些特殊的符号等。
# The following are popular file type extensions - uncomment the lines to
# disable crawling them
# Microsoft Word
# regexpIgnoreCase:\\.doc$
# Microsoft Excel
# regexpIgnoreCase:\\.xls$
# regexpIgnoreCase:\\.xlw$
# Microsoft Powerpoint
# regexpIgnoreCase:\\.ppt$
# Microsoft Access
# regexpIgnoreCase:\\.mdb$
# DBase/Xbase
# regexpIgnoreCase:\\.dbf$
# Adobe Portable Document Format (PDF)
# regexpIgnoreCase:\\.pdf$
# Rich Text Format (RTF)
# regexpIgnoreCase:\\.rtf$
# The following are some typical Microsoft SharePoint patterns that you
# may not want to crawl - uncomment the lines to disable crawling them.
# contains:_layouts
# contains:_vti_bin
# WebFldr.aspx$
# Upload.aspx$
# EditForm.aspx$
# These patterns prevent crawling of repetitive URLs
# prevents http://example.com/foo/foo/foo/.....
regexp:/([^/]*)/\\1/\\1/
# prevents http://example.com/foo/bar/foo/bar/....
regexp:/([^/]*)/([^/]*)/\\1/\\2/
# prevents http://example.com/foo?bar=1&bar=1&bar=1...
regexp:&([^&]*)&\\1&\\1
##############################################
# File types we don't crawl
# Images
.gif$
.jpg$
.jpeg$
.png$
# Used instead of jpeg sometimes
.jpe$
.pcx$
.tif$
.tiff$
.bmp$
# Binaries/Executables
regexpIgnoreCase:\\.dll$
regexpIgnoreCase:\\.exe$
.a$
.o$
.so$
.bin$
.class$
.jnilib$
# Font types
# truetype font
.ttf$
.pfb$
.pfm$
.afm$
# Mac files
.hqx$
.sea$
.dmg$
# Adobe
# .ps$
# .ps.gz$
# .ps.Z$
.eps$
.ai$
# Media
.ram$
.wav$
.avi$
.mid$
.mov$
.mpg$
.mpeg$
.mp3$
.ogg$
.3gp$
.m4a$
.m4v$
.wma$
.wmv$
.wrl$
# Databases
.dat$
.dta$
.log$
.lst$
# Archives, except .ps.gz, .ps.Z
.bz2$
.jar$
.arj$
.cab$
.rar$
.rpm$
.tar$
.zip$
.tar.gz$
.upp$
.tgz$
.sdd$
regexpIgnoreCase:([^.]..|[^p].|[^s])[.]z$
regexpIgnoreCase:([^.]..|[^p].|[^s])[.]gz$
.lzh$
.msi$
# Linux distribution files
.hdr$
.iso$
.img$
.gpg$
# Google
.gg$
.kml$
.kmz$
.skb$
.skp$
# Others
.gbk$
.fac$
.ghg$
.mdic$
.chm$
.mht$
# Apache directory listings
/?S=A$
/?S=D$
/?D=A$
/?D=D$
/?M=A$
/?M=D$
/?N=A$
/?N=D$
/?C=N&O=A$
/?C=M&O=A$
/?C=S&O=A$
/?C=D&O=A$
/?C=N&O=D$
/?C=M&O=D$
/?C=S&O=D$
/?C=D&O=D$
/?C=N;O=A$
/?C=M;O=A$
/?C=S;O=A$
/?C=D;O=A$
/?C=N;O=D$
/?C=M;O=D$
/?C=S;O=D$
/?C=D;O=D$
# Invalid characters
contains:\001
contains:\002
contains:\003
contains:\004
contains:\005
contains:\006
contains:\007
contains:\010
contains:\011
contains:\012
contains:\013
contains:\014
contains:\015
contains:\016
contains:\017
contains:\020
contains:\021
contains:\022
contains:\023
contains:\024
contains:\025
contains:\026
contains:\027
contains:\030
contains:\031
contains:\032
contains:\033
contains:\034
contains:\035
contains:\036
contains:\037
contains:\040
contains:\177
# Invalid endings
.html/$
.htm/$
.phtml/$
.ghtml/$
.asp/$
.jsp/$
.shtml/$
# Invalid endings
!/
"/
$/
%/
&/
'/
(/
)/
+/
,/
./
</
=/
>/
{/
|/
}/
~/
[/
\\\/
]/
^/
`/
Google Search Appliance 有效网址格式规则
当您指定网站上应该或不应该抓取的网址时,或在建立基于网址的集合时,网址应符合下列有效格式。
任一包含主机/路径分隔斜线的网址子字符串
| http://www.google.cn/ | www.google.cn上使用HTTP协议的任意网页 |
| www.google.cn | www.google.cn上使用任意支持协议的网页 |
| google.cn/ | google.cn域内的任意网页 |
字符串任一后缀
您可以利用$在字符串结尾指定后缀。
| home.html$ | 以home.html结尾的所有网页 |
| .pdf$ | 扩展名为.pdf的所有页 |
字符串的前缀
您可以通过在字符串开头加上^来指定前缀。前缀可以和后缀组合使用,以获得更精确的字符串匹配。例如,^candycane$与字符串”candycane”完全匹配。
| ^http:// | 使用HTTP协议的任一网页 |
| ^https:// | 使用HTTPS协议的任一网页 |
| ^http://www.google.com/page.html$ | 仅指定网页 |
网址的任意子字符串
利用前缀”contains”指定这些格式。
| contains:coffee | 包含”coffee”的任一网址 |
| contains:beans | 包含“beans”的任一网址 |
以-(减号)符号标记的例外
| candy.com/
-www.candy.com/ |
表示“www.chocolate.candy.com”是匹配项,但“www.candy.com”不是 |
GNU正则表达式库中的正则表达式
在设备中,正则表达式:
- 区分大小写(除非您指定“regexpIgnoreCase:”)
- 将保留字符添加到正则表达式中时,应使用两个转义字符(反斜杠“\\”)。请注意:regexp:和regexpCase:等同。
regexp:-sid=[0-9A-Z]+/regexp:http://www\\.example\\.google\\.cn/.*/images/ regexpCase:http://www\\.example\\.google\\.cn/.*/images/ regexpIgnoreCase:http://www\\.Example\\.Google\\.cn/.*/IMAGES/
注释
| #这是注释 | 允许使用以#开始的空行和注释。这些注释会从网址格式中删除并被忽略 |
对SEO的启示:
- 避免在URL中出现以上问题
GoogleSearchAppliance抓取与编制索引
在您开始抓取网络内容前,您需要指定一个或多个起始位置。您可以通过指定要遵循的网址格式和要避免的网址格式来控制和优化抓取幅度。如果要抓取指定的网址,那么这个网址必须符合仅跟踪和抓取以下格式的网址框中的“至少一个”网址格式,并且“不能”符合勿抓取以下格式的网址框中的任何网址格式。
请注意:如果某个网址既符合仅跟踪和抓取以下格式的网址中的格式,又符合勿抓取以下格式的网址中的格式,将不抓取该网址。
网址区分大小写。如果您希望使用不区分大小写的网址,请使用操作符regexpIgnoreCase。
抓取工具可以访问使用HTTP、HTTPS和SMB协议的内容。
您可以利用以下选项控制和定义抓取。
从以下网址开始抓取
起始网址(每行输入一个)控制抓取起始位置。通过跟踪起始网址中所列文档(一个或多个)内的链接,可以访问到您希望在所有集合中包含的全部内容。
这些网址只是抓取的起始点。它们告诉抓取工具从何处开始抓取。但是,仅当起始网址中的链接符合仅跟踪和抓取以下格式的网址中的格式时,才会跟踪这些链接并为其编制索引。例如,如果您在该部分中指定起始网址http://mycompany.com/,并在仅跟踪和抓取以下格式的网址部分中指定格式www.mycompany.com/,则抓取工具将会寻找网页http://www.mycompany.com/中的链接,但仅会抓取符合格式www.mycompany.com/的网址并为其编制索引。
此窗口中所有的条目都应是完全限定网址,使用以下格式:
<协议>://<主机>[:端口]/[路径]
在此格式中,协议可包括HTTP、HTTPS(适用于安全内容)或SMB(适用于文件共享)。在方括号[]中包含的信息是可选的。在<主机>[:端口]后的正斜杠“/”是必需的。
有效示例:
https://www.example.com/secure/ http://www.example.com/help/ smb://fileshare.mycompany.com/my-sharename/
| 无效示例: | 原因: |
| http://www/ | 无效,因为主机名不是完全限定的。完全限定主机名包括本地主机名和完整域名。例如:mail.corp.company.com。 |
| www.example.com/ | 缺少协议信息,所以无效。 |
| http://www.example.com | <主机>[:端口]后必须使用“/”。 |
抓取工具将会多次重试抓取暂时无法访问的网址。
仅跟踪和抓取以下格式的网址
从以下网址开始抓取框中的所有条目都需要在仅跟踪和抓取以下格式的网址框中有相应的条目,否则将显示错误信息。
只有符合您在此窗口中指定的格式(每行一个)的网址才会被跟踪和抓取。这样,您就可以控制在服务器上抓取哪些文件。
示例:
https://www.example.com/secure/ http://www.example.com:80/help/ smb://fileshare.mycompany.com/my-sharename/ \\fileshare.mycompany.com\shared\
这些条目只能对包含以上字符串的网址进行抓取。例如,以下所有网址都将被抓取(假设它们没有包含在勿抓取网址中):
https://www.example.com/secure/file.txt http://www.example.com:80/help/projectA smb://fileshare.mycompany.com/my-sharename/folder1 \\fileshare.mycompany.com\shared\folder1
找到的网址会根据这些格式进行检查,以决定是否要纳入索引中。只会抓取符合这些格式的网址并为其编制索引。要抓取某一网址并为其编制索引,该网址中应存在一系列符合某一起始网址的“跟踪格式”的链接。如果不存在有效链接路径,您应将该网址添加至从以下网址开始抓取部分。
您在该窗口列出的网址格式须符合有效网址格式规则。要输入网址格式,请在该窗口输入有效网址。按下Enter键以添加其他格式。允许空行和注释(以#开始)。
“抓取网址”页上的网址区分大小写。如果您希望使用不区分大小写的网址格式匹配,请使用操作符regexpIgnoreCase。例如,假设您输入以下格式:
regexpIgnoreCase:http://www.mycompany.com/documents/
该格式也与以下网址相匹配:
http://www.mycompany.com/Documents/ http://www.mycompany.com/DOCUMENTS/
勿抓取以下格式的网址
文件类型搜索会提取文档中的所有纯文本并为其编制索引。但不会为图形、图表和格式化信息编制索引。您可以将任意文件格式排除在抓取和编制索引的格式之外,只需定义网址格式例外,就可阻止对这些网页进行抓取。符合您在该窗口中指定的格式(每行一个)的网址不会被抓取。
该选项可以阻止抓取特定的文件类型、目录或其他网页组。例如,在此框中输入格式contains:?将阻止抓取许多通用网关界面(CGI)脚本。
您在此处列出的网址格式必须符合有效网址格式规则。要输入网址格式,请在该窗口输入有效网址。按下Enter键,在新行中添加其他格式。允许空行和注释(以#开始)。
为方便起见,该框内预置了多个网址格式和文件类型,其中有些您可能不希望抓取工具为其编制索引。我们建议您,除非您检测到自己站点的某些部分目前被排除在了这些规则之外,否则请不要删除任何默认格式。
要使抓取工具不抓取某种格式或文件类型,请删除包含该文件类型的那一行中的#标记。


