Elasticsearch 是一个基于Apache Lucene (TM) 的开源搜索引擎。无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。但是,Lucene 只是一个库。想要使用它,你必须使用 Java 来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene 非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。Elasticsearch 也使用 Java 开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。它提供了近实时的索引、搜索、分析功能。Elasticsearch 不仅仅是 Lucene 和全文搜索,我们还能这样去描述它:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理 PB 级结构化或非结构化数据
所有的这些功能被集成到一个服务里面,你的应用可以通过简单的 RESTful API、各种语言的客户端甚至命令行与之交互。它可以用于全文搜索、结构化搜索、分析以及将这三者混合使用,使用案例如下:
- 维基百科使用 Elasticsearch 提供全文搜索并高亮关键字,以及输入实时搜索 (search-as-you-type) 和搜索纠错 (did-you-mean) 等搜索建议功能。
- 英国卫报使用 Elasticsearch 结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。
- StackOverflow 结合全文搜索与地理位置查询,以及 more-like-this 功能来找到相关的问题和答案。
- Github 使用 Elasticsearch 检索 1300 亿行的代码。
上手 Elasticsearch 非常容易。它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。
- 它提供了强大的搜索功能,可以实现类似百度、谷歌等搜索。
- 可以搜索日志或者交易数据,用来分析商业趋势、搜集日志、分析系统瓶颈或者运行发展等等
- 可以提供预警功能(持续的查询分析某个数据,如果超过一定的值,就进行警告)
- 分析商业信息,在百万级的大数据中轻松的定位关键信息
在 ElasticSearch 中,我们常常会听到 Index、Type 以及 Document 等概念,将 Elasticsearch 和传统关系型数据库 Mysql 做一下类比:

注意:MySQL 的 Index 和 Elasticsearch 的 Index 含义并不一致。
Elasticsearch 集群可以包含多个索引 (indices) (数据库), 每一个索引可以包含多个类型 (types) (表), 每一个类型包含多个文档 (documents) (行), 然后每个文档包含多个字段 (Fields) (列)。数据被存储和索引在分片 (shards) 中, 索引只是把一个或多个分片分组在一起的逻辑空间。我们只需要知道文档存储在索引 (index) 中。其他细节都可以有 Elasticsearch 搞定。
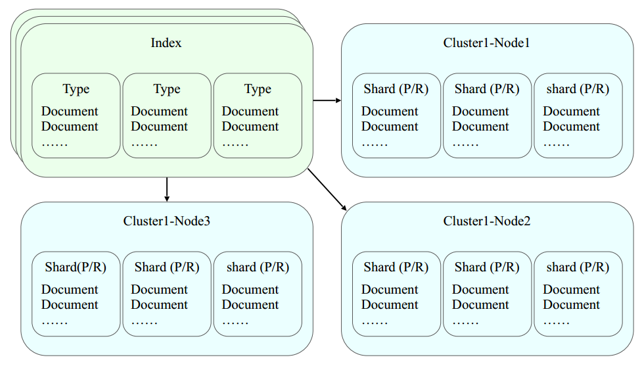
一些基本概念:
- Cluster/集群:Cluster 是一组服务器构成的集成,用于协同存储数据、索引数据、检索数据和解析数据。Cluster 具有唯一标识名,你只需要指定集群标识名(默认是 elasticsearch),启动的时候,凡是集群是这个名字的,都会默认加入到一个集群中,选举 master 节点和节点管理都是自动完成的。当然一个节点也可以组成一个集群。
- Node/节点:Node 是参与到 Cluster 的单个服务器节点,具有唯一标识名,可加入到指定的 Cluster 中。是一个运行着的 Elasticsearch 实例。
- Index/索引:Index 是一类文档的集合,是具有相同业务特征的数据文档集合 (不是相同数据结构),相当于传统数据库中的数据库。ES 数据的索引、搜索和分析都是基于索引完成的。Cluster 中可以创建任意个 Index。每个 Index(对应 Database)包含多个 Shard,默认是 5 个,分散在不同的 Node 上,但不会存在两个相同的 Shard(相同的主和复制)存在一个 Node 上。当索引创建完成的时候, 主分片的数量就固定了, 但是复制分片的数量可以随时调整。
- Type/类型:Type 是 Index 中数据的,用于标识不同的文档字段信息的集合,相当于传统数据库的表。在 0 之后的版本直接做了插入检查,禁止一个索引下不同 Type 的字段类型冲突。举例来说,在一个博客系统中,你可以定义一个 user type, 可以定义一个 blog type, 还可以定义一个 comment type。
- Document/文档:Document 是 ES 数据可被索引化的基本的存储单元,需要存储在 Type 中,相当于传统数据库的行记录,使用 json 来表示。
- Shard/分片:一个索引可能会存储大量的数据,进而会让单个节点超出硬件能承受范围。举例来说,存储了 10 亿文档的单个节点,会占用 1TB 磁盘空间,并且会导致查询的时候速度很慢。为了解决这个问题,Elasticsearch 提供了分片也就是 shards 对 index 进行划分成更小的部分。当你创建 index 的时候,你可以简单地指定你想要的碎片数量。每一个碎片具有和 index 完全相同的功能。碎片最主要的两个作用是:它允许你水平地切割你的容量体积;它允许你并行地分发作业,提高系统的性能。默认在创建索引时会创建 5 个分片,这个数量可以修改。分片的数量只能在创建索引的时候指定,不能在后期修改。
- Replicas/副本:因为各种原因,所以数据丢失等问题会时有发生,碎片也可能会丢失,为了防止这个问题,所以你可以将一个或多个索引碎片复制到所谓的复制碎片,简称为副本。副本最主要的两个作用是:它提供了高可用性, 以防碎片/节点失败。之于这点,所以副本的永远不要和原始碎片分布在同一个节点上;它可以扩展系统的吞吐量,因为搜索可以在所有副本执行。默认情况下,Elasticsearch 为每个索引分配了 5 个主碎片和 1 个副本,这意味着在你的集群中,如果至少有两个节点,那么每个索引将有 5 个主碎片和 5 个复制碎片,总共 10 碎片/索引。
注意:ES 并不是一个标准的数据库,它不像 MongoDB,它侧重于对存储的数据进行搜索。因此要注意到它不是实时读写的,这也就意味着,刚刚存储的数据,并不能马上查询到。缺省配置下,shard 每秒自动更新,所以会有 1S 的延时。
ElasticSearch 生态圈你所应该了解的内容:(后续的文章会一一介绍,尽请期待~)
参考链接:


