在先前的文章中介绍了使用Python解析Nginx日志,今天主要介绍的是使用ELK(Elasticsearch + Logstash + Kibana)来监控Nginx日志。
备注:以下方案占用CPU和内存过大,不适合在云服务器部署。
工具简介
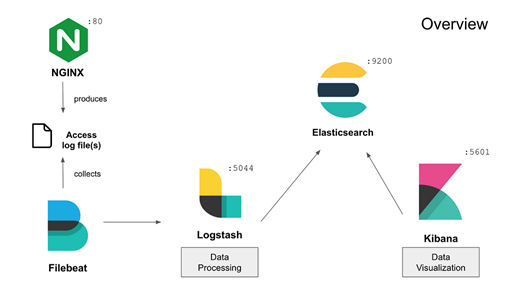
本教程涉及Filebeat、Elasticsearch、Logstash、Kibana四个工具。
Filebeat
- 用途:Filebeat是Elastic Stack(以前称为ELK Stack)的一部分,是一个轻量级日志文件采集器。
- 功能:它用于监控日志文件或日志目录,收集日志数据,然后发送到Elasticsearch或Logstash进行进一步处理。
- 场景:Filebeat特别适合于收集和转发日志数据,因其轻量级和易于配置的特点。
Elasticsearch
- 用途:Elasticsearch是一个高性能的搜索和分析引擎。
- 功能:它允许用户快速地存储、搜索和分析大量的数据。通常用于日志分析、全文搜索、安全智能、业务分析等领域。
- 特点:以其快速的搜索能力、水平扩展性和易用性而闻名。
Logstash
- 用途:Logstash是Elastic Stack的一部分,是一个服务器端数据处理管道。
- 功能:它可以同时从多个源接收数据,转换这些数据,然后将它们发送到您选择的”存储库”中,如Elasticsearch。
- 场景:Logstash特别适用于日志数据的收集、转换和解析。
Kibana
- 用途:Kibana是Elasticsearch的数据可视化面板工具。
- 功能:它提供了基于Web的界面,允许用户创建和分享各种复杂的仪表板,这些仪表板可以展示Elasticsearch索引中的数据。
- 特点:Kibana通常用于数据探索、可视化和仪表板的创建。
安装与配置
由于服务器是Ubuntu 22.04,所以以下教程针对的是的Ubuntu。以下是详细的过程。
安装和配置Elasticsearch
添加Elasticsearch GPG密钥
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
安装HTTPS传输
sudo apt-get install apt-transport-https
添加Elasticsearch源
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
更新并安装Elasticsearch
sudo apt-get update && sudo apt-get install elasticsearch
配置Elasticsearch在/etc/elasticsearch/elasticsearch.yml(根据需要修改配置)。
elasticsearch.yml文件提供了集群、节点、路径、内存、网络、发现和网关的配置选项。这些选项中的大多数都在文件中预先配置,但您可以根据需要进行更改。为了演示单个服务器配置,我们将只调整网络主机的设置。
Elasticsearch在9200端口上侦听来自各处的流量。您需要限制外部访问您的Elasticsearch实例,以防止外部人员通过其[REST API]读取您的数据或关闭Elasticsearch集群(https://en.wikipedia.org/wiki/Representational_state_transfer).要限制访问并提高安全性,请找到指定network.host的行,取消注释,然后将其值替换为localhost,如下所示:
sudo nano /etc/elasticsearch/elasticsearch.yml ... #----------------------------------Network----------------------------------- # # Set the bind address to a specific IP (IPv4 or IPv6): # network.host: localhost ...
我们已经指定了localhost,以便Elasticsearch侦听所有接口和绑定的IP。如果您希望它只在特定的接口上侦听,您可以指定它的IP来代替localhost。
启动Elasticsearch
sudo systemctl start elasticsearch sudo systemctl enable elasticsearch
测试是否安装成功
curl -X GET "localhost:9200"
{
"name": "VM-12-16-ubuntu",
"cluster_name": "elasticsearch",
"cluster_uuid": "4U2r4MnFRWqMbqwSbqyLtg",
"version": {
"number": "7.17.15",
"build_flavor": "default",
"build_type": "deb",
"build_hash": "0b8ecfb4378335f4689c4223d1f1115f16bef3ba",
"build_date": "2023-11-10T22:03:46.987399016Z",
"build_snapshot": false,
"lucene_version": "8.11.1",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
安装和配置Kibana
安装Kibana
sudo apt-get install kibana
配置Kibana在/etc/kibana/kibana.yml(设置Elasticsearch URL)。
在终端上打开/etc/kibana/kibana.yml文件,此文件包含Kibana的所有配置。
sudo nano /etc/kibana/kibana.yml
在文件中查找下面的行,该行可能已经存在:
#elasticsearch.hosts:["http://localhost:9200"]
删除前面的注释符号#,然后将Elasticsearch URL更改为您的Elasticsearch实例的URL,例如:
elasticsearch.hosts:["http://localhost:9200"]
确保URL包含正确的主机和端口,以便Kibana能够连接到您的Elasticsearch实例。
保存并退出文件。
启动Kibana
sudo systemctl start kibana sudo systemctl enable kibana
配置Kibana可被访问
因为Kibana被配置为只在localhost上侦听,所以我们必须设置一个反向代理以允许外部访问它。首先,使用openssl命令创建一个管理Kibana用户,用于访问Kibana web界面。例如,我们将此帐户命名为kibanaadmin,但为了确保更高的安全性,我们建议您为用户选择一个难以猜测的非标准名称。
以下命令将创建管理Kibana用户和密码,并将它们存储在htpasswd.users文件中。
echo "kibanaadmin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users
在提示下输入并确认密码。
接下来配置Nginx服务器。新建一个文件类似:sudo nano /etc/nginx/sites-enabled/kibana.biaodianfu.com
内容如下:
server {
listen 80;
server_name kibana.biaodianfu.com;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
测试并重启Nginx:
sudo nginx -t sudo systemctl reload nginx
访问http://kibana.biaodianfu.com/status查看kibana的运行状态。
安装和配置Filebeat
安装FileBeat
sudo apt-get install filebeat
启用Nginx模块
FileBeat提供了多种模块来简化日志文件的收集和解析,包括一个用于Nginx日志的模块。
sudo filebeat modules enable nginx
配置FileBeat
编辑FileBeat配置文件:
打开/etc/filebeat/filebeat.yml,配置FileBeat以将日志数据发送到Logstash。
output.logstash:
hosts: ["localhost:5044"]
设置Nginx日志路径
在/etc/filebeat/modules.d/nginx.yml中,确保正确设置了Nginx日志文件的路径。
sudo nano /etc/filebeat/modules.d/nginx.yml
配置日志路径:在access和error部分中,确保var.paths设置为您的Nginx日志文件的实际路径。默认路径通常如下所示:
- module: nginx
access:
enabled: true
var.paths: ["/var/log/nginx/access.log*"]
error:
enabled: true
var.paths: ["/var/log/nginx/error.log*"]
如果您的Nginx日志文件存储在不同的位置,请相应地修改var.paths。
测试配置
在应用更改之前,建议使用FileBeat测试您的配置文件,以确保没有语法错误。
sudo filebeat test config sudo filebeat test output
启动Filebeat
sudo systemctl start filebeat sudo systemctl enable filebeat
安装和配置Logstash
安装Logstash
sudo apt-get install logstash
创建Logstash配置文件
配置文件应包括用于解析Nginx日志的输入、过滤器和输出部分。
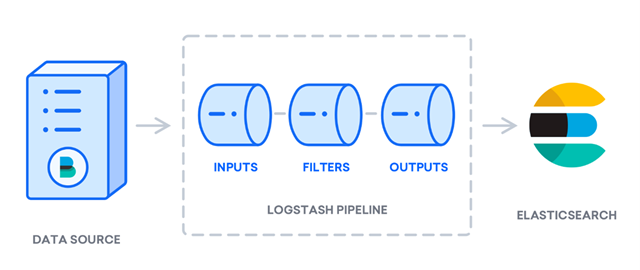
要设置Logstash配置文件以包含Filebeat,您需要创建一个Logstash配置文件,该文件定义了从Filebeat接收数据的方法。 在/etc/logstash/conf.d/中创建一个配置文件,例如
sudo nano /etc/logstash/conf.d/filebeat-input.conf
input {
beats {
port => 5044
}
}
filter {
if [fileset][module] == “nginx” {
if [fileset][name] == “access” {
grok {
match => { “message” => “%{COMBINEDAPACHELOG}” }
}
date {
match => [“timestamp”, “dd/MMM/YYYY:HH:mm:ss Z”]
}
}
}
}
output {
elasticsearch {
hosts => [“localhost:9200”]
index => “nginx-access-%{+YYYY.MM.dd}”
}
}
启动并测试 Logstash
启动 Logstash 并检查是否有错误。
sudo systemctl start logstash sudo systemctl enable logstash
重启 FileBeat
重启 FileBeat 以应用更改。
sudo systemctl restart filebeat
完成这些步骤后,FileBeat 应该开始从 Nginx 的 access.log 收集日志,并通过 Logstash 将其发送到 Elasticsearch。确保您的 Elasticsearch 集群已经运行并可以接收数据。
低性能服务器的应对方案
以下是在性能较差的云服务器上运行 Elasticsearch、Kibana、Logstash 和 Filebeat 的一些建议:
调整 Elasticsearch 的 jvm.options
Elasticsearch 的 jvm.options 文件通常位于 Elasticsearch 配置目录中。这个目录的具体位置取决于您的安装方式和操作系统,但通常位于以下位置之一:
sudo nano /etc/elasticsearch/jvm.options
在 jvm.options 文件中,您可以设置多个 JVM 参数,其中最常见的是以下两个:
- -Xms<size>:设置 JVM 的初始堆内存大小。例如,-Xms2g 表示设置初始堆内存为 2GB。
- -Xmx<size>:设置 JVM 的最大堆内存大小。例如,-Xmx2g 表示设置最大堆内存为 2GB。
通常建议将 -Xms 和 -Xmx 设置为相同的值,以避免堆内存自动扩展。
比如设置:
-Xms256m -Xmx256m
查看和关闭不必要的 Elasticsearch 插件
查看当前安装的插件
sudo bin/elasticsearch-plugin list
查看列表中的插件,并了解每个插件的功能。确定是否有插件是当前不需要的或者对系统性能有负面影响。
关闭不必要的插件
sudo bin/elasticsearch-plugin remove [插件名]
将 [插件名] 替换为您想要卸载的插件名称。
完成插件卸载后,需要重启 Elasticsearch 服务以使更改生效。
限制 Kibana 进程的内存使用
可以通过 Node.js 的环境变量来限制 Kibana 进程可以使用的最大内存。
使用以下命令来设置环境变量,限制 Kibana 进程的最大内存使用量。例如,要将内存限制为 256M,请使用:
export NODE_OPTIONS="--max-old-space-size=256"
设置环境变量后,需要重启 Kibana 服务以使更改生效。
调整 Firebeat 的扫描频率
调整 Filebeat 的扫描频率可以帮助管理其对资源的使用,尤其是在处理大量日志文件的情况下。扫描频率决定了 Filebeat 查看文件变化的频率等。
filebeat.inputs:
- type: filestream
id: my-filestream-id
enabled: false
paths:
# - /var/log/nginx/*.log
- /var/log/nginx/*.log
# prospector.scanner.exclude_files: ['.gz$']
prospector.scanner.exclude_files: ['.gz$']
scan_frequency: 30s
在这个例子中,scan_frequency 被设置为 30s。您可以根据需要调整这个值,例如改为 60s 或 5m。
对配置文件做出更改后,保存并关闭文件。重启 Filebeat 服务。
参考链接:


