Apache Lucene 简介
Apache Lucene 是一个高性能、可扩展的信息检索(IR)库,用于为应用程序提供全文搜索功能。Lucene 由 Apache 软件基金会维护,是一个开源项目,广泛应用于各种需要快速文本搜索和索引的场景。Lucene 的核心功能包括文本分析、索引创建、查询处理和搜索结果排序。
Apache Lucene 是一个强大而灵活的信息检索库,适合各种需要快速和准确文本搜索的应用场景。通过其丰富的功能和可扩展性,Lucene 帮助开发者构建高效的搜索解决方案,是构建现代搜索引擎和文本处理应用的理想选择。
核心特性
- 全文索引和搜索:
- Lucene 提供了强大的全文索引和搜索功能,能够处理大规模文本数据。
- 支持多种数据类型的索引,包括字符串、数字、日期等。
- 灵活的查询语言:
- 支持丰富的查询语法,包括布尔查询、短语查询、通配符查询、模糊查询、范围查询等。
- 用户可以构建复杂的查询来满足不同的搜索需求。
- 可扩展性和高性能:
- 设计为高性能的搜索引擎,能够快速处理大规模数据集。
- 支持索引分片和并行处理,以提高搜索效率。
- 文本分析和处理:
- 提供多种文本分析工具,如分词器、过滤器和标记器,帮助处理和标准化文本数据。
- 支持自定义分析器,以满足特定语言和领域的需求。
- 结果排序和评分:
- 提供基于 TF-IDF(词频-逆文档频率)模型的默认评分机制,用户可以自定义评分算法。
- 支持对搜索结果进行排序和分页处理。
- 丰富的扩展和集成:
- 支持与其他系统和框架的集成,如 Apache Solr 和 Elasticsearch,这些项目都基于 Lucene 构建。
- 提供插件机制,方便扩展和自定义功能。
优势
- 高效性:Lucene 以其高效的索引和搜索能力著称,能够处理大规模数据集。
- 灵活性:支持多种查询和分析功能,可以根据需求进行扩展和自定义。
- 成熟性:作为一个成熟的开源项目,Lucene 拥有丰富的文档和活跃的社区支持。
应用场景
- 搜索引擎:Lucene 可以作为搜索引擎的核心组件,用于构建网站、应用程序或企业内部的搜索功能。
- 日志分析:通过索引和搜索日志数据,实现快速日志查询和分析,支持故障排查和监控。
- 文档管理:用于文档管理系统中的全文检索,帮助用户快速查找和定位文档内容。
- 电子商务和推荐系统:在电子商务平台中,Lucene 可以用于商品搜索和推荐,提高用户体验和转化率。
Apache Lucene 的核心概念

Apache Lucene 的核心概念包括以下几个方面:
- 索引(Index):Lucene 使用倒排索引(Inverted Index)来存储文档数据,以便于快速搜索。倒排索引将每个术语映射到包含该术语的文档列表,从而加快查询速度。
- 文档(Document):文档是 Lucene 中信息存储的基本单元。每个文档可以表示为一个或多个字段的集合,类似于数据库中的一行。
- 字段(Field):字段是文档的组成部分,每个字段都有一个名称和一个值。字段可以被索引、存储或者两者兼有。不同的字段可以有不同的索引和存储策略。
- 术语(Term):术语是 Lucene 中最小的搜索单元,通常是从字段中提取的单词。术语由字段名称和文本组成。
- 分析器(Analyzer):分析器负责将文本分解为可索引的词汇单元(Tokens)。这个过程通常包括字符过滤、分词和词汇过滤。分析器对于处理不同语言和文本格式非常重要。
- 查询(Query):查询是搜索的核心机制,用于定义搜索条件。Lucene 支持多种查询类型,如 TermQuery、BooleanQuery、PhraseQuery 等,允许构建复杂的查询逻辑。
- 评分(Scoring):Lucene 使用评分机制来确定文档与查询的匹配程度。默认的评分算法基于 TF-IDF(词频-逆文档频率)模型,并结合其他因素如字段长度规范化。
- 目录(Directory):目录是一个抽象层,用于存储索引。Lucene 提供多种目录实现,如 FSDirectory(基于文件系统)和 RAMDirectory(基于内存)。
- 索引器(Indexer):索引器负责将文档添加到索引中。它处理文档的解析和字段的索引化。
- 搜索器(Searcher):搜索器用于执行查询并返回匹配的文档。它遍历倒排索引来查找符合查询条件的文档。
这些核心概念共同构成了 Lucene 的基础架构,使其能够高效地进行全文搜索和数据检索。
Lucene 的索引
索引的概念
索引(Index)是一种数据结构,用于加速数据的检索。在 Lucene 中,索引是以倒排索引(Inverted Index)的形式存储的。倒排索引的主要特点是将每个术语(Term)映射到包含该术语的文档列表,而不是将每个文档映射到其包含的术语。

倒排索引的结构
倒排索引通常包含以下部分:
- 术语字典(Term Dictionary):包含所有唯一的术语及其在索引中的位置。
- 文档列表(Posting List):对于每个术语,包含一个文档列表,每个文档记录了该术语在文档中的位置和频率。
- 文档信息(Document Information):包含每个文档的元数据,如文档 ID、长度等。
索引的创建过程
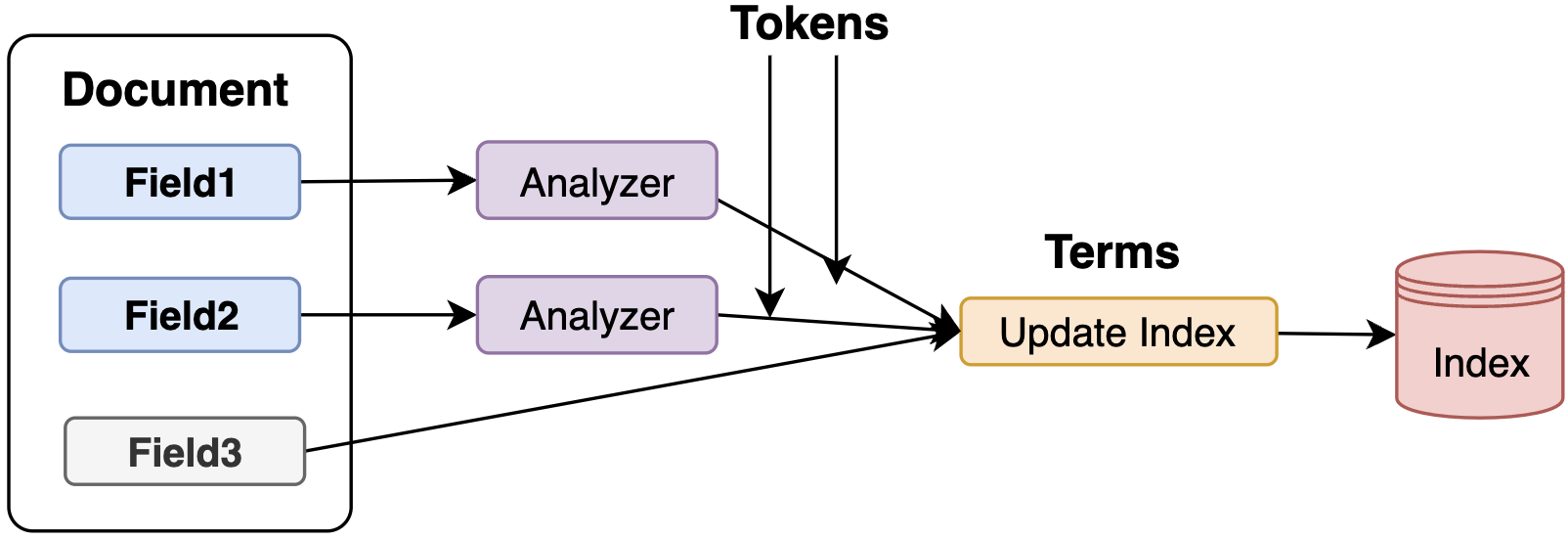
创建索引的过程可以分为以下几个步骤:
- 文档解析:将文档解析为多个字段(Field),每个字段包含名称和值。
- 字段分析
- 使用分析器(Analyzer)将字段值分解为词汇单元(Tokens)。分析器通常包括字符过滤、分词和词汇过滤等步骤。
- 术语生成:从词汇单元生成术语(Term),每个术语由字段名称和词汇单元组成。
- 倒排索引构建:将生成的术语及其对应的文档信息存储到倒排索引中。每个术语对应一个文档列表,记录了该术语在哪些文档中出现以及出现的位置和频率。
- 索引优化:通过合并小的索引段(Segment)来减少索引文件的数量,提高搜索性能。
索引的存储
Lucene将索引存储在**目录(Directory)**中,目录是一个抽象层,用于管理索引文件的存储。常见的目录实现包括:
- FSDirectory:基于文件系统的目录实现,将索引文件存储在磁盘上。
- RAMDirectory:基于内存的目录实现,将索引文件存储在内存中,适用于小型索引或测试环境。
索引的更新
Lucene支持对索引的动态更新,包括添加、删除和更新文档:
- 添加文档:
- 使用 IndexWriter 将新文档添加到索引中。
- IndexWriter 会自动处理分词和索引构建。
- 删除文档:
- 使用 IndexWriter 根据文档 ID 或查询条件删除文档。
- 删除操作不会立即从物理文件中移除数据,而是标记为删除,后续的优化操作会真正删除这些数据。
- 更新文档:
- 更新文档实际上是先删除旧文档,再添加新文档。
- 使用 IndexWriter 的 updateDocument 方法可以简化这一过程。
索引的优化
为了提高搜索性能,Lucene提供了索引优化的功能:
- 段合并(Segment Merging):
- 索引由多个段(Segment)组成,每个段是一个独立的倒排索引。
- 合并小的段可以减少索引文件的数量,提高搜索效率。
- 使用 IndexWriter 的 optimize 方法可以手动触发段合并。
索引的读取
索引的读取通过搜索器(Searcher)进行,主要步骤如下:
- 打开索引:使用 IndexReader 打开索引,获取索引的读取接口。
- 创建搜索器:使用 IndexSearcher 创建搜索器,IndexSearcher 封装了索引的搜索逻辑。
- 执行查询:使用 IndexSearcher 的 search 方法执行查询,返回匹配的文档列表。
- 评分和排序:搜索器根据评分机制对匹配的文档进行评分,并按评分排序。
索引的备份和恢复
为了保证数据的安全性和可靠性,Lucene支持索引的备份和恢复:
- 备份:
- 使用 IndexWriter 的 commit 方法将当前索引状态持久化到磁盘。
- 使用 IndexReader 的 clone 方法创建索引的副本。
- 恢复:从备份文件中重新加载索引,使用 IndexReader 的 open 方法打开备份索引。
Lucene的索引机制通过倒排索引实现了高效的数据检索。索引的创建、更新、优化和读取过程都经过精心设计,确保了搜索的高性能和灵活性。理解这些核心概念有助于更好地利用Lucene进行全文搜索和数据检索。
Lucene的分析器(Analyzer)
Lucene的分析器(Analyzer)是文本处理的关键组件,负责将输入文本转换为词汇单元(Tokens),以便进行索引和搜索。分析器在文本处理中扮演着重要角色,特别是在处理不同语言、文本格式和应用场景时。
分析器的组成
一个典型的Lucene分析器由以下三个主要组件组成:
- 字符过滤器(CharFilter):
- 在分词之前,对原始文本进行预处理。
- 例如,去除 HTML 标签、规范化文本等。
- 通常是可选的。
- 分词器(Tokenizer):
- 将输入文本分解为初始的词汇单元(Tokens)。
- 分词器是分析器的核心部分,决定了文本是如何被拆分的。
- 常见的分词器有 WhitespaceTokenizer、StandardTokenizer 等。
- 词汇过滤器(TokenFilter):
- 对初始的词汇单元进行进一步处理。
- 例如,转换为小写、去除停用词、词干提取等。
- 可以串联多个词汇过滤器以实现复杂的文本处理。
常见的分析器
Lucene提供了多种内置分析器,适用于不同的场景:
- StandardAnalyzer:
- 最常用的分析器,适用于大多数西方语言。
- 处理标点符号、去除停用词,并将文本转换为小写。
- SimpleAnalyzer:
- 仅通过空格分隔词汇单元,并将其转换为小写。
- 不去除停用词,也不处理标点符号。
- WhitespaceAnalyzer:
- 仅通过空格分隔词汇单元,不进行其他处理。
- KeywordAnalyzer:
- 将整个输入作为单个词汇单元,适用于精确匹配场景。
- StopAnalyzer:
- 去除常见的停用词(如“and”、“the”),适用于需要过滤常用词的场景。
- CustomAnalyzer:
- 用户可以根据需要自定义分析器,组合不同的字符过滤器、分词器和词汇过滤器。
分析器的使用
分析器在索引和查询阶段都被使用:
- 索引阶段:在将文档添加到索引时,分析器处理字段文本,生成词汇单元并创建倒排索引。
- 查询阶段:在处理用户查询时,分析器对查询字符串进行相同的分词和过滤,以确保查询和索引使用相同的词汇单元。
自定义分析器
用户可以通过组合不同的组件来创建自定义分析器,以满足特定需求:
Analyzer customAnalyzer = CustomAnalyzer.builder() .withTokenizer(StandardTokenizerFactory.class) .addTokenFilter(LowerCaseFilterFactory.class) .addTokenFilter(StopFilterFactory.class, "words", "stopwords.txt") .build();在这个例子中,自定义分析器使用了标准分词器,并添加了小写转换和停用词过滤。
分析器的选择
选择合适的分析器取决于应用的具体需求:
- 语言支持:不同的分析器支持不同的语言和字符集。对于多语言应用,可能需要使用特定的语言分析器。
- 性能:复杂的分析器可能会影响索引和查询性能。需要在精度和性能之间找到平衡。
- 文本特性:对于包含大量标点符号或特定格式的文本,可能需要自定义分析器来正确处理。
Lucene的分析器通过分词和过滤将文本转换为词汇单元,为索引和搜索提供了基础。理解和选择合适的分析器对于实现高效和准确的全文搜索至关重要。通过灵活地组合不同的组件,用户可以创建适合自己应用的自定义分析器。
Lucene的查询(Query)
Lucene的查询机制是其搜索功能的核心部分,支持复杂的搜索逻辑和灵活的查询组合。Lucene提供了多种查询类型和工具来构建、解析和执行查询。
查询的基本概念
- 查询(Query):定义了搜索条件,用于在索引中查找匹配的文档。
- 查询语法:Lucene支持一种类似于SQL的查询语法,允许用户构建复杂的查询。
常见的查询类型
Lucene提供了多种查询类型,每种类型适用于不同的搜索需求:
- TermQuery:
- 用于精确匹配某个字段中的单个术语。
- 适合精确搜索,如ID或关键字匹配。
- BooleanQuery:
- 组合多个子查询,可以使用逻辑运算符(AND、OR、NOT)进行组合。
- 支持构建复杂的查询逻辑。
- PhraseQuery:
- 用于搜索一组词语的精确短语匹配。
- 可以指定词语之间的最大距离(slop),允许一定程度的词序变化。
- WildcardQuery:
- 支持使用通配符(*、?)进行模糊匹配。
- *代表零个或多个字符,?代表一个字符。
- PrefixQuery:
- 用于搜索以特定前缀开头的术语。
- 类似于WildcardQuery,但只允许在术语末尾使用*。
- FuzzyQuery:
- 支持模糊匹配,允许一定程度的编辑距离(LevenshteinDistance)。
- 适用于拼写错误或相似词语的搜索。
- RangeQuery:
- 用于搜索在指定范围内的值。
- 支持数值、日期和字符串范围查询。
- MatchAllDocsQuery:
- 匹配索引中的所有文档。
- 通常用于统计或过滤所有文档的场景。
查询解析器(QueryParser)
QueryParser:
- Lucene提供了QueryParser来解析用户输入的查询字符串,将其转换为Query对象。
- 支持复杂的查询语法,包括布尔运算符、短语搜索、通配符等。
使用示例:
QueryParser parser = new QueryParser("content", new StandardAnalyzer()); Query query = parser.parse("lucene AND search");查询执行
IndexSearcher:
- 用于执行查询并返回结果。
- search方法返回一个TopDocs对象,包含匹配的文档及其评分。
执行查询示例:
IndexSearcher searcher = new IndexSearcher(indexReader); TopDocs results = searcher.search(query, 10); for(ScoreDoc scoreDoc : results.scoreDocs){ Document doc = searcher.doc(scoreDoc.doc); //处理结果 }评分与排序
- 评分机制:
- Lucene使用TF-IDF(词频-逆文档频率)及其他因素(如字段长度规范化)对文档进行评分。
- 可以自定义相似性模型(Similarity)以调整评分算法。
- 排序:
- 默认情况下,结果按相关性评分排序。
- 可以使用Sort对象自定义排序规则,如按字段值排序。
过滤器(Filter)
过滤查询(FilteredQuery):
- 使用过滤器对查询结果进行二次筛选。
- 过滤器不影响评分,仅用于排除不匹配的文档。
使用示例:
Query query = new TermQuery(new Term("content", "lucene")); Filter filter = new TermRangeFilter("date", "20230101", "20231231", true, true); Query filteredQuery = new FilteredQuery(query, filter);多字段查询
MultiFieldQueryParser:
- 支持在多个字段上执行查询。
- 可以为不同字段设置不同的权重。
使用示例:
String[] fields = {"title", "content"}; MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, new StandardAnalyzer()); Query query = parser.parse("lucene");Lucene的查询机制通过多样的查询类型和解析工具,提供了强大的搜索能力。用户可以根据具体需求选择合适的查询类型,并结合查询解析器和过滤器构建复杂的查询逻辑。了解这些查询工具和机制,有助于实现高效、准确的全文搜索应用。
Lucene的组件
Apache Lucene是一个功能强大的全文搜索库,其架构由多个组件构成,每个组件在搜索和索引过程中扮演着特定的角色。了解这些组件有助于更好地理解和使用Lucene。
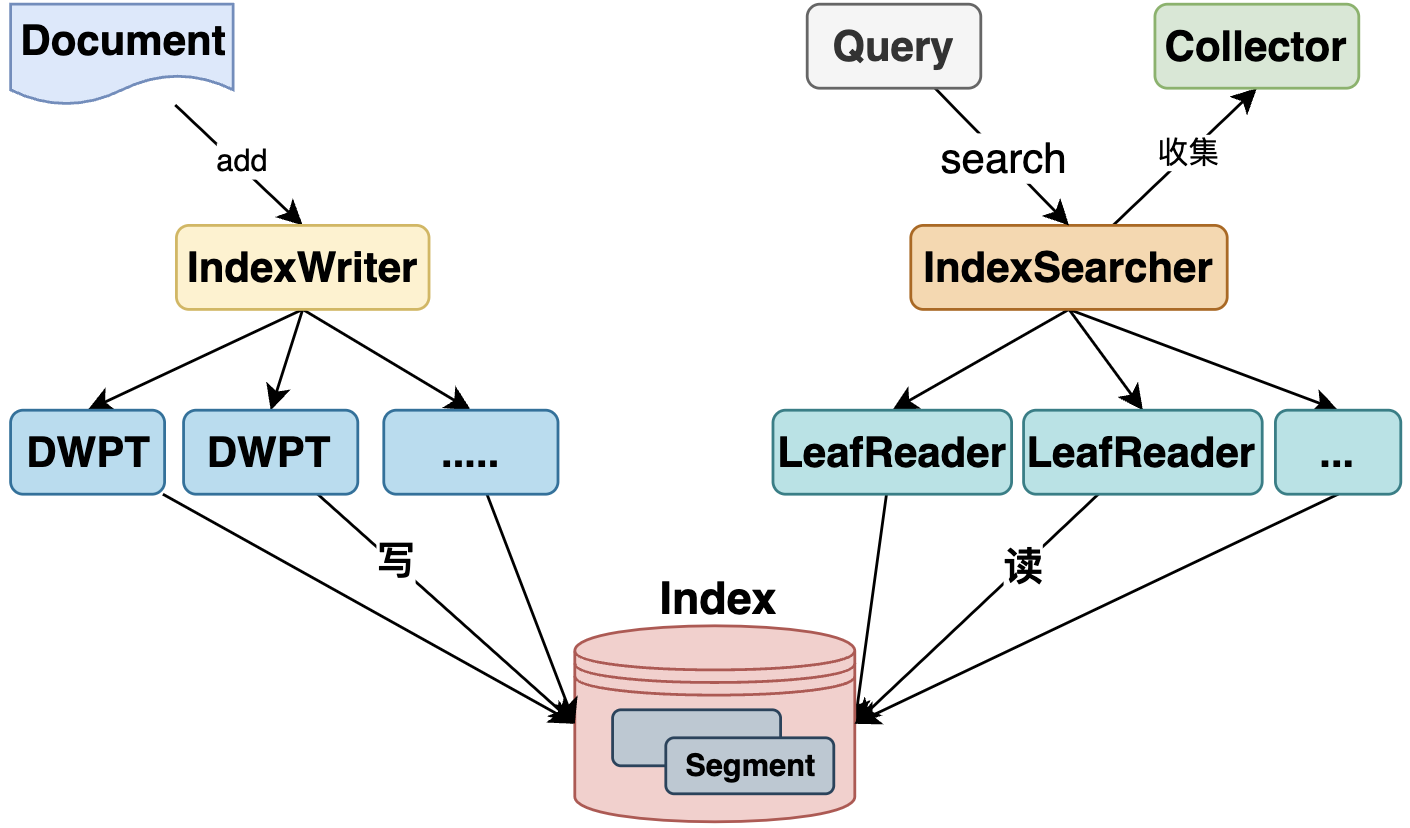
IndexWriter
功能:
- IndexWriter是Lucene中用于创建和更新索引的核心组件。
- 负责将文档添加到索引中、删除或更新已有文档。
- 管理索引段(Segment)的合并和优化。
特点:
- 提供了线程安全的操作,支持并发添加和更新文档。
通过配置 Analyzer,IndexWriter 能够处理文本分词和分析。
IndexReader
功能:
- IndexReader 用于读取索引内容,支持检索和分析文档。
- 提供了访问文档、术语和其他索引信息的接口。
特点:
- 主要用于查询和检索,而不是更新索引。
- 支持快照机制,可以在不关闭的情况下获取索引的稳定视图。
IndexSearcher
功能:
- IndexSearcher 是执行查询和返回搜索结果的核心组件。
- 利用 IndexReader 访问索引数据,并根据查询条件检索匹配的文档。
特点:
- 提供了多种查询执行方法,包括简单查询和排序查询。
- 通过使用 Collector,可以定制化结果收集和处理方式。
Analyzer
功能:
- Analyzer 负责将文本分解为词汇单元(Tokens),以便索引和搜索。
- 包含字符过滤器、分词器和词汇过滤器三个主要部分。
特点:
- 支持多种内置分析器,如 StandardAnalyzer、WhitespaceAnalyzer 等。
- 可以自定义分析器,以满足特定的文本处理需求。
Document
功能:
- Document 是 Lucene 中存储和索引的基本单元。
- 由多个字段(Field)组成,每个字段包含名称和值。
特点:
- 支持不同类型的字段,如文本字段、数值字段、存储字段等。
- 可以为每个字段配置不同的索引和存储选项。
Field
功能:
- Field 是文档的组成部分,表示一个数据属性。
- 包含字段名称和字段值,以及索引和存储配置。
特点:
- 支持多种数据类型,如字符串、整数、浮点数等。
- 可以配置字段是否被索引、存储或作为排序字段。
Query
功能:
- Query 定义了搜索条件,用于在索引中查找匹配的文档。
- Lucene 支持多种查询类型,如 TermQuery、BooleanQuery、PhraseQuery 等。
特点:
- 可以组合多个查询构建复杂的搜索逻辑。
- 支持查询解析器(QueryParser)将用户输入的查询字符串转换为 Query 对象。
Directory
功能:
- Directory 是 Lucene 用来存储索引的抽象层。
- 提供了索引文件的读写接口。
特点:
- 支持多种存储实现,如 FSDirectory(文件系统)、RAMDirectory(内存)等。
- 通过不同的实现,可以在性能和存储之间进行权衡。
Similarity
功能:
- Similarity 定义了文档与查询之间的评分机制。
- 默认使用 BM25 算法,但用户可以自定义相似性模型。
特点:
- 影响搜索结果的排序和相关性评分。
- 提供了自定义接口,允许用户根据应用需求调整评分规则。
Collector
功能:
- Collector 用于收集查询结果,通常与 IndexSearcher 配合使用。
- 可以定制化结果的收集和处理过程。
特点:
- 支持不同的收集策略,如分页、排序、过滤等。
- 提供了基础实现,如 TopDocsCollector,用于收集排名前 N 的文档。
Lucene 的组件通过相互协作,构成了一个高效、灵活的全文搜索引擎。每个组件在索引和搜索过程中扮演着特定的角色,从文本分析、索引创建,到查询执行和结果评分,都提供了丰富的功能和可扩展性。理解这些组件及其工作原理,是有效使用 Lucene 进行全文搜索开发的基础。
Lucene、Solr、Elasticsearch 如何选择?
选择 Lucene、Solr、Elasticsearch 中的一个来满足特定的搜索需求,取决于项目的具体要求、技术栈、团队的技术能力等因素。以下是对这三个工具的比较和选择建议:
Apache Lucene
特点:
- 低级库:Lucene 是一个 Java 库,提供了强大的全文搜索功能,但没有用户界面或集成的服务能力。
- 灵活性:因为是一个库,开发者可以高度自定义 Lucene 的使用方式。
- 复杂性:需要较深的搜索引擎技术知识来配置和使用。
适用场景:
- 自定义解决方案:如果你需要构建一个高度定制化的搜索功能,并且有开发团队能够深入理解和使用 Lucene。
- 嵌入式搜索:适用于希望在 Java 应用中直接嵌入搜索功能的场景。
Apache Solr
特点:
- 开源搜索平台:Solr 基于 Lucene 构建,提供了更多功能如分布式搜索、集群管理、缓存、数据导入等。
- 配置驱动:大部分功能可以通过配置文件设置,无需深入编程。
- 支持 RESTful API:可以通过 HTTP 请求进行管理和查询。
- 丰富的功能:包括分面搜索、地理搜索、丰富的数据类型支持等。
适用场景:
- 需要现成的搜索解决方案:如果你需要快速搭建一个搜索引擎,并且希望使用现成的功能和管理界面。
- 数据驱动的应用:适合需要复杂查询和分析功能的应用。
- 企业搜索:Solr 的丰富功能和稳定性非常适合企业级应用。
Elasticsearch
特点:
- 分布式搜索引擎:Elasticsearch 也是基于 Lucene,但更注重实时性和分布式架构。
- JSON over HTTP:使用 JSON 格式进行数据交互,易于集成到各种应用中。
- 强大的分布式特性:天然支持分布式存储和搜索,易于扩展。
- 实时搜索和分析:适合需要实时数据处理的应用。
适用场景:
- 实时数据分析:如果你的应用需要实时搜索和分析大规模数据(如日志、监控数据)。
- 云原生应用:Elasticsearch 的分布式特性非常适合云环境和大数据应用。
- 大规模数据:需要处理大量数据并保持高性能和可扩展性。
选择建议
- 开发复杂性:如果你的团队有能力处理底层搜索技术,可以考虑直接使用 Lucene,否则 Solr 和 Elasticsearch 会提供更高层次的功能和易用性。
- 功能需求:对于需要快速实现、配置丰富的搜索功能的项目,Solr 是一个不错的选择。而对于需要实时性和大规模数据处理的项目,Elasticsearch 更为合适。
- 社区和生态Elasticsearch 有一个庞大的社区和丰富的插件生态系统,适合需要快速获得支持和扩展功能的项目。
- 技术栈和集成:考虑你的现有技术栈,Solr 和 Elasticsearch 都提供了良好的 RESTful API,便于与其他系统集成。
参考链接:
- Apache Lucene – Welcome to Apache Lucene
- 大数据组件:Lucene 全文索引与搜索 – 腾讯云开发者社区 – 腾讯云 (tencent.com)
- Lucene 之使用详解分析 – 上善若泪 – 博客园 (cnblogs.com)
- Lucene search engine in action. Lucene is a powerful Java library that… | by Ivan Polovyi | Level Up Coding (gitconnected.com)
- Apache Lucene Full Text Search Tutorial | Toptal®


