EGADS (Extendible Generic Anomaly Detection System) 是 Yahoo 一个开源的大规模时间序列异常检测项目,主要由两个模块构成,一个是时间序列构造模块,另一个是异常检测模块。
给定一段时间的离散值(构成一个序列),时间序列模块会学习这段序列的特征,并试图重新构建一个和原序列尽量接近的序列。结果和原序列一同送入异常检测模块,基于不同的算法(原则,阈值),异常点会被标记出来。
时间序列构造模块提供了多种算法 (Time-series Modeling Module)
- Double Exponential Smoothing Model 双指数平滑 – 也称为 Holt 指数平滑 – 改进了常见的简单指数平滑模型,考虑了数据中含有有趋势因素的情况。
- Moving Average Model 移动平均预测模型基于人工构建的时间序列,其中给定时间段的值由该值的平均值和某些前后时间段的值代替。
- Multiple Linear Regression Model 多变量线性回归模型
- Naive Forecasting Model 朴素预测模型是移动平均预测模型的一个特例,即当平滑周期数为 1 时的特例。
- Olympic Model 去掉一个最高分,去掉一个最低分,然后计算最近 k 周的数据的平均数,作为当前的预测值。
- Polynomial Regression Model 单变量多项式回归模型
- Regression Model 单变量线性回归模型
- Simple Exponential Smoothing Model 简单指数平滑回归模型
- Spectral Smoother 基于输入时间序列 Hankel 矩阵的奇异值分解(SVD)实现平滑技术
- Triple Exponential Smoothing Model 三指数平滑,也称为 Winters 方法, 是双指数平滑模型的改进,考虑了数据中含有季节性和周期性
- Weighted Moving Average Model 加权移动平均模型,由当前周期和上个周期的数据做的加权平均值做为当前的预测值
异常检测模块 (Anomaly Detection Module)
- Extreme Low Density Model 超低密度模型,很简单有效的密度模型。
- Adaptive Kernel Density Change Point Detector 拐点检测模型
- K Sigma Model 经典 K-sigma 模型
- DBScan Model(Density-Based Spatial Clustering of Applications with Noise)基于 DBScan 密度的模型,在空间中作聚类,如果目标序列可以比较好的分类的话会有不错的效果。
序列构造自动选优
不同类型的数据可能适合不同的模型,选择 Auto Forecast Model,程序会自动把所有 TMM 都跑一遍,并推选偏差值最小的模型送入异常检测模块。值得注意的是,这里自动选取的标准只关注了还原度,但还原度高并不直接代表能更好的查找异常,在使用本方法的时候要留意在心。
多数投票算法
不同的异常检测算法从不同的角度定义了异常。实践过程发现,单一异常算法并不能找出所有异常点,还会出现一系列的假阳性异常。使用 Majority Voting,规定半数以上算法识别为异常的点才输出为结果,在实际数据中提供了远高于单一算法的准确度。
整体架构
EGADS 框架由三个主要部分组成:时间序列建模模块(TMM),异常检测模块(ADM)和报警模块(AM)。给定一个时间序列,TMM 组件模拟产生时间序列,由 ADM 和 AM 组件进行消费处理,分别计算误差并过滤不感兴趣的异常。
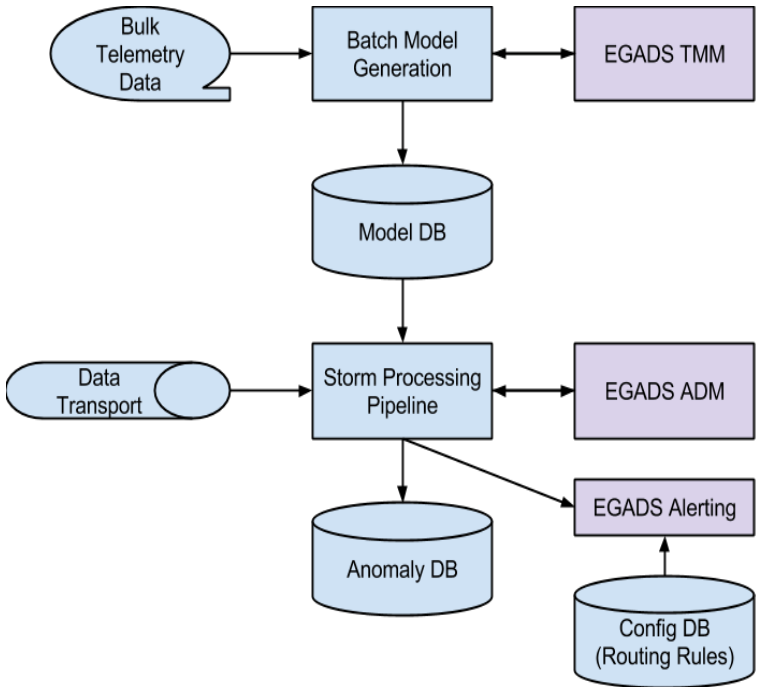
此外,异常检测,还需要几个支撑组件来驱动完成。首先,所有的异常检测模型都是离线批处理(batch)生产的,然后应用到实时环境(realtime)。其中批处理由三个步骤组成:
- 监测(即监视的时间序列数据)数据批量存储在 Hadoop 集群上
- 批量模型生成器针对这些数据运行,并为目标时间序列构建模型
- 模型存储在模型数据库中
然后在线实时流使用这些存储的模型,具体步骤如下:
- 数据流入 Storm 进行流式处理
- 集群中的一个模块调用 EGADS ADM,根据存储在模型数据库中的模型来评估输入数据点
- 如果存在异常,则将其发送到由组合规则和其他包含特定逻辑组成的辅助规则流(见第 4 节)
- 根据规则,如果异常是警报事件,则生成事件,存储在状态数据库中,并转发到警报路由系统
- 警报路由系统应用路由配置规则将警报发送给相应的处理人员
可扩展性
EGADS 的监控需要每秒分析超过百万级数据点,亿级别时间序列。要求在 CPU 负载,I/O 和内存占用方面具有可扩展性,并且数据点的处理需要尽可能高效。这意味着需要预先计算尽可能多的模型。从磁盘读取模型是不切实际的会降低性能,因此模型应该存储在内存中。另一方面,为了控制成本,模型应尽可能小。
异常检测算法
目前,EGADS 能够检测出三类异常:
- 异常值:给定输入时间序列 x,异常值是时间戳值对 $(t, x_t)$,其中观测值 $x_t$ 与该时间序列的期望值 $E(x_t)$ 不同
- 波动点(Change Points):给定输入时间序列 x,波动点是指在某个时间 t,其状态(行为)在这个时间序列上表现出与 t 前后的值不同
- 异常时间序列:给定一组时间序列 X=\{x^i|}$,异常时间序列 $x^j\in X$ 是在 X 上与大多数时间序列值不一致的部分
异常检测
EGADS 提供了两类用于检测输出的算法:
插件方法
EGADS 中异常值检测的第一类方法称为插件方法。为了模拟输入时间序列的正常行为,可以业务和时序数据的特点来插入大量的时间序列模型和预测模型(例如 ARIMA,指数平滑,Kalman 滤波,状态空间模型等)。这就是为什么我们将这个总体策略称为插件方法。应该注意的是,所有这些模型都在 EGADS 中用于时间序列预测,这是我们框架的另一个特征。
我们提出的插件框架由两个主要组件组成:时间序列建模模块(TMM)和异常检测模块(ADM)。给定时间序列 $x=\{x_t\in R:\forall\geq0\}$,TMM 提供时间 t 的 $x_t$ 的预测值,由 $u_t$ 表示。我们也将这个量称为 $x_t$ 的预期值。TMM 可以是机器学习模型,其基于数据或基于规则进行预测,在时间 tt 上挖掘数据点 xtxt 的具体表现特征(如波动或异常)。可以认为 TMM 只是一个可以产生预测的黑匣子模块。在这个意义上,我们提出的框架是通用的,不依赖于任何特定的时间序列建模框架。给定预测值 $u_t$ 和实际观测值 $x_t$,ADM 计算一些我们称为偏差度量(DM)的偏差概念。
最简单的衡量偏差的方法是预测误差,即:$PE_t=x_t-u_t$。如果错误超出某些固定阈值,则会发出警报。这种简单的方法在某些情况下可能会起作用,但是对于大多数的方法来说,它不会是一个很好的策略,因为它不能捕获到相对错误的具体信息。
相对误差 $RE_t$ 定义为 $u_t$ 的一个因素:$RE_t=\frac{x_t-u_t}{u_t}=\frac{x_t}{u_t}$ 通过对相对误差进行阈值处理,可以检测异常值,同时对所期望值的幅度进行归一化。虽然这些阈值确定了异常检测模块的敏感度,然而,很难确定异常检测的最佳度量。事实上,给定时间序列的最优度量的选择取决于时间序列的性质以及 TMM 性能。例如,如果我们处理一个非常规则的时间序列,我们有一个准确的模型,使用预测误差进行异常检测可能就足够了,因为它预期是正常分布的。在其他情况下,最佳度量可能在预测误差和相对误差之间存在某种差异。因此,EGADS 默认跟踪一组偏差度量,使用系统的人可以创建自己的错误度量。
基于分解的方法
EGADS 中第二类异常值检测方法是基于时间序列分解的思想,在时间序列分析中,通常将时间序列分解为:趋势、季节性和噪声的三个要素。通过监测噪声分量,可以捕获异常值。更准确地说,如果点 $x_t$ 的噪声分量的绝对值大于某个阈值,则可以认为 $x_t$ 为异常值。
变点检测
在一些文献里有提到一种基于时间窗口的变点检测技术,在 EGADS 中,目前采用基于模型的方法。在这些方法中,时间序列的预期行为通上节中提到的建模技术建模。我们结合上节中描述的插件方法来计算输入时间序列的残差序列(或模型预测的偏差)。然后对残差系列应用绝对变化点检测的方法来检测残差分布。我们使用内核密度估计(Kernel Density Estimation)非参数估计残差分布和 Kullback-Leibler(KL 距离,常用来衡量两个概率分布的距离)来测量分布变化。
检测异常时间序列
EGADS 支持的另一类异常检测技术涉及检测异常时间序列。异常时间序列 T 定义为与其他时间序列有明显的平均偏差的时间序列。假设所有的时间序列是均匀的,并且来自相同的源(即,是相同簇的一部分),则可以简单地计算相对于其他时间序列的时间序列(i)的平均偏差。在 EGADS 中,我们目前的方法是基于各种时间序列特征将时间序列聚类到一组簇 C 中,包括趋势和季节性,光谱熵,自相关,平均欧几里德距离等。在聚类后,我们通过测量集群质心内和之间的偏差和时间序列(i)执行帧内或群集时间序列异常检测。这种 EGADS 异常检测类型的常见场景是用来进行分类。例如,如果网络工程师希望在数百万个时间序列中找到异常的服务器,那么以前的方法可能不切实际,因为建模是按照每个时间序列的基础完成的,而不考虑其他度量的行为。这种异常检测类型的另一个应用是发现类似的异常,这与以前的场景相反。
报警
异常检测的最终目标是产生准确和及时的警报。EGADS 通过两阶段过程实现这一点,首先通过阈值选择产生一组候选异常,然后对给定的规则过滤不相关的异常。
阈值选择
阈值选择的作用是根据异常检测模块(ADM)产生的偏差度量选择合适的阈值。目前,EGADS 基于以下两种阈值选择算法实现:
- $K\sigma$ 偏差
- 密度分布
第一种方法是参数化的,并假定数据正态分布,有明确的平均值和标准偏差。依靠高斯分布,并根据为“3 sigma 规则”(即:其中 99.73% 的样本位于平均值的三个标准偏差之内。因此,根据 $K\sigma$ 中的 K 值,可以确定在时间 t 观测样品的可能性。根据所需的敏感度,可以测量给定的样品是否在 K=2 或 1 的所有样品的 95.45% 或 68.27% 之内。请注意,这里的假设是我们的偏差度量是正态分布的。
第二种方法是非参数的,并且对于偏差度量不是正态分布的情况是有用的。基本思想是找到偏差度量分布的低密度区域。一种方法是使用诸如局部离群因子(LOF)的算法。通过将对象的局部密度与其邻居的局部密度进行比较,可以识别具有相似密度的区域,以及具有比邻居密度明显更低的密度的点,这些点被认为是异常值。
过滤
过滤是传递给应用的最后阶段的处理。虽然作为过滤阶段的输入的候选异常在统计上是显著的,但并不是所有异常都与特定用例相关。例如,一些应用对时间序列中的尖峰感兴趣,而其他应用对下降感兴趣,而其他应用对变化点感兴趣。EGADS 提供了一个简单直观的界面,允许用户标记时间序列的哪些区域是异常的。然后,该反馈被 EGADS 与时间序列和模型特征一起用于训练一个分类器,该分类器预测异常 $a_i$ 是否与用户 $u_j$ 相关。EGADS 使用的时间序列数据特征如表所示。
| 时间序列功能 | 描述 |
| 周期(频率) Periodicity (frequency) | 周期对于确定季节性非常重要。 |
| 趋势 Trend | 如果平均水平存在长期变化,则存在 |
| 季节性 Seasonal | 当时间序列受季节性因素影响时,如一年中的一个月或一周中的某一天 |
| 自相关 Auto-correlation | 代表远程依赖。 |
| 非线性 Non-linearity | 非线性时间序列包含通常不由线性模型表示的复杂动力学。 |
| 偏态 Skewness | 测量对称性,或更加明确地说,缺乏对称性。 |
| 峰度 Kurtosis | 如果数据相对于正常分布达到峰值或平坦,则采取措施。 |
| 林中小丘 Hurst | 衡量时间序列的长期记忆。 |
| 李亚普诺夫指数 Lyapunov Exponent | 衡量附近轨迹的发散速度。 |
EGADS 提取的时间序列及其特征的一个示例:
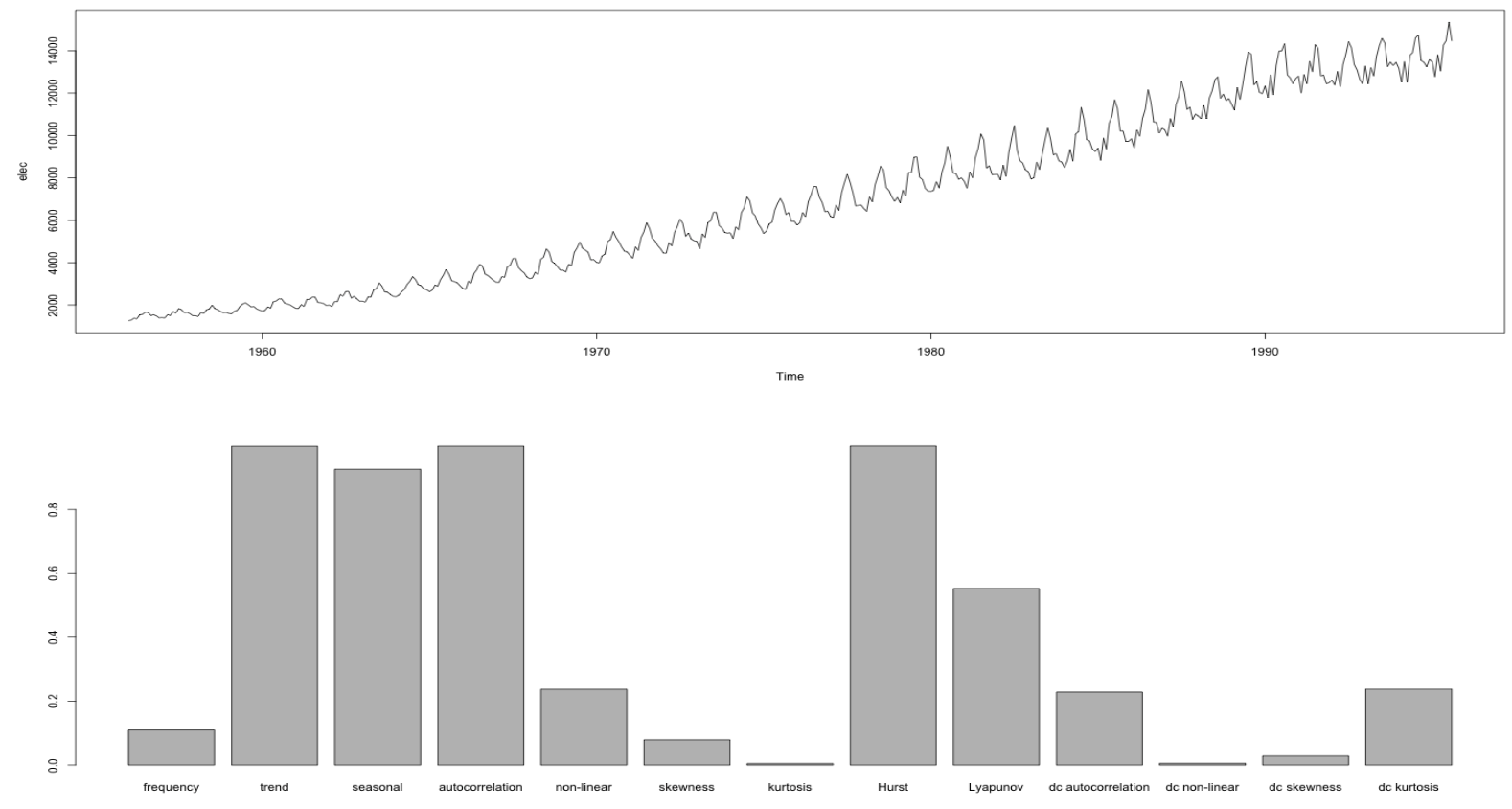
注意,以 dc 开始的指标是在时间序列上经过调整后(即删除趋势和季节性数据后)得到的。
实验研究
数据
用于实验的数据集由 1:1 的合成和真实数据混合而成。我们已经创建了一个合成的时间序列生成工具,该工具随着框架和基准数据的开放。使用该工具,通过指定长度,幅度,异常数,异常类型,异常大小,噪声水平,趋势和季节性来生成合成时间序列。真实数据集使用了雅虎会员登录数据 (YML)。合成和真实数据在时间序列都包含 3000 个数据点,YML 数据包含了 3 个月的数据点。除非另有说明,所有实验均以 1000 次随机选取的时间序列进行,结果取平均值。还要注意,合成和真实数据都有异常标签,方便测量精度和召回率。
建模实验
时间序列建模(由 EGADS 中的 TMM 组件捕获)是异常检测的基本部分。通常情况下,异常检测与底层时间序列模型一样好。由于大量的候选模型,模型选择变得至关重要,并且取决于时间序列特征和可用资源。在下面的实验中,我们展示了时间序列特征对模型性能的影响,并显示了精度,实验中使用的模型和误差度量分别参见下表。
用于建模实验的模型列表:
| 模型 | 描述 |
| Olympic Model | 季节模型,其中下一个点的预测是先前 n 个时期的平滑平均值 |
| 指数平滑模型 | 用于产生平滑时间序列比较流行的模型,双重和三重指数平滑变量增加了模型的趋势和季节性,用于实验的 ETS 模型自动选择最佳“拟合”指数平滑模型 |
| 移动平均模型 | 在这种模式下,预测是基于人为构建的时间序列,其中给定时间段的值被该值的平均值和一些前后时间段的值所取代,加权移动平均和初始预测模型是移动平均模型的特例 |
| 回归模型 | 使用一个或多个变量来对 xx 和 yy 之间的关系进行建模 |
| ARIMA | Autoregressive integrated moving average |
| (T)BATS 系列 | 带有 Box-Cox 变换的指数平滑状态空间模型 |
用于建模实验的指标列表:
| 模型 | 描述 |
| Bias | 误差的算术平均值 |
| MAD | 平均绝对偏差,也称为 MAE |
| MAPE | 平均绝对百分比误差 |
| MSE | 误差的均方 |
| SAE | 绝对错误的总和 |
| ME | 平均误差 |
| MASE | 平均绝对比例误差 |
| MPE | 平均百分比误差 |
时间序列特征和性能
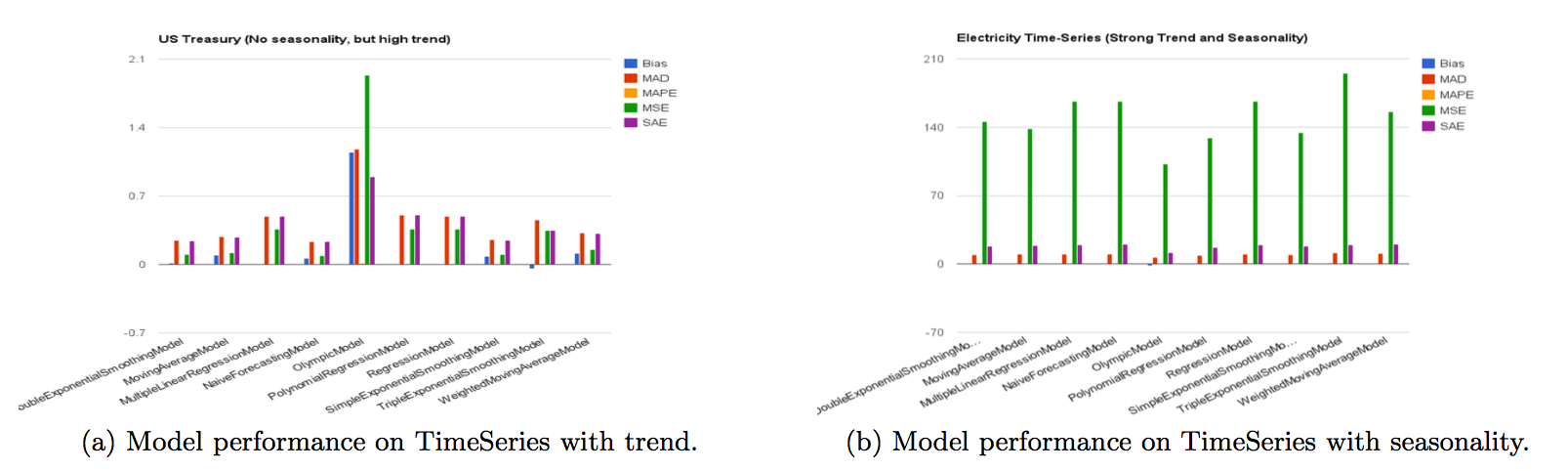
为了证明时间序列特征对模型性能的影响,我们比较了不同模型的时间序列与不同特征的误差度量。下图显示了时间序列特征在模型行为中起着重要作用。例如,季节性模式的 Olympic 模型在数据集上表现不佳,没有季节性和强劲趋势。EGADS 能够跟踪历史时间序列特征和模型性能,使用这些历史信息,EGADS 选择由表中描述的误差度量判断的最佳模型(给定时间序列特征)。实际上,基于数据特征进行模型选择比针对每个模型执行交叉验证要快得多。
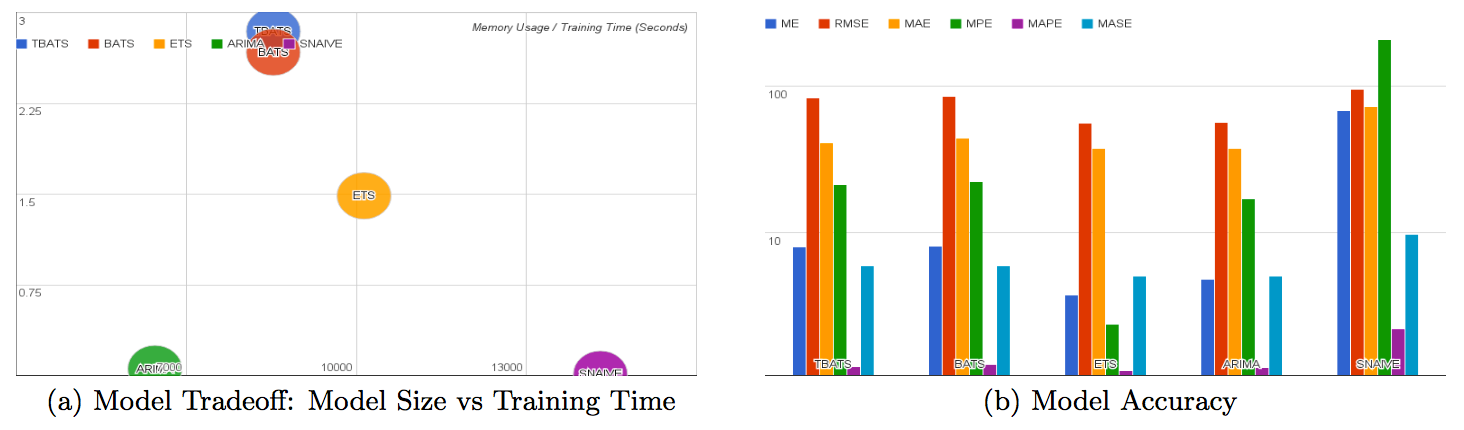
时序模型的可扩展性
时序模型需要高性能技术以支持大规模(例如每秒数百万点)数据流的实时计算,因此需要在模型大小、训练时间和准确性之间进行权衡。例如,从图中可以看出,季节性天性模型很快训练,但是具有较大的存储要求和较高的平均误差。在雅虎,首先设定了资源和模型训练时间的目标,然后选择相应的模型。换句话说,目标是将资源和模型建立时间限制下使得表 3 中的错误减到最小。
异常检测实验
在本节中,我们比较了开源系统与 EGADS,参考的开源系统如表所示:
| 模型 | 描述 |
| EGADS Extreme Low-密度模型异常值 | EGADS 基于密度的异常检测 |
| EGADS CP | 基于 EGADS 内核的波动点检测 |
| EGADS KSigma Model 异常值 | EGADS 重新实现了经典的 k-西格玛模型 |
| Twitter Outlier | 基于广义 ESD 方法的开源 Twitter-R 异常检测库 |
| Extreme I&II R 异常值 | 开源单变异常值检测,阈值绝对值和残差检测异常 |
| BreakOut Twitter CP | 来自 Twitter 基于 ESD 统计测试来检测变化点的一个库 |
| ChangePt 1 R CP | 一个 R 库,实现各种主流和专门的变化点方法,用于在数据中查找单个和多个变化点 |
| ChangePt 2&3 R CP | 检测平均值和变量的变化 |
异常模型在不同数据集上的表现:
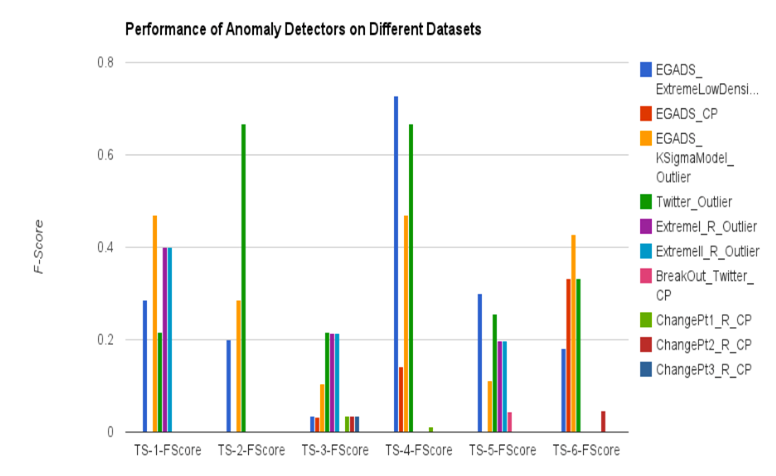
结果可以看出,没有一个最佳的异常检测模型能适合所有业务场景,不同的算法需要结合检测不同类型的异常来确定。但是,EGADS 的设计初衷是在用户对数据类型的时间序列和异常类型不了解的情况下,该系统能够优雅和稳健地处理数据中存在的各种异常现象。因此,EGADS 被构建为将一组异常检测模型组合成一个最佳的框架的库。这些模型的异常被转发到过滤组件以进行精确的异常检测。
异常过滤实验
异常的重要性往往取决于实际应用场景。具体来说,一些用户可能对展示恶意攻击的时间序列行为感兴趣,而其他用户可能对收入有兴趣。
将各种模型跑出来的所有的异常点:
- Weighted Moving Average Model 是在 8 个 tsmm 模型里比较出来,对我们业务数据来说 12 小时长的时序数据,是拟合最好的模型。
- 经过 6 个 adm 模型的运行对比,DBScan Model, Extreme Low Density Model, kSigma 这三个模型较为灵敏,能够检测出绝大多数异常,准确率各不相同。
- DBScan, Low Density 和 kSigma 召回率较高
- kSigma 准确率低,有误检
- kernel density,Naive,Simple 召回率低
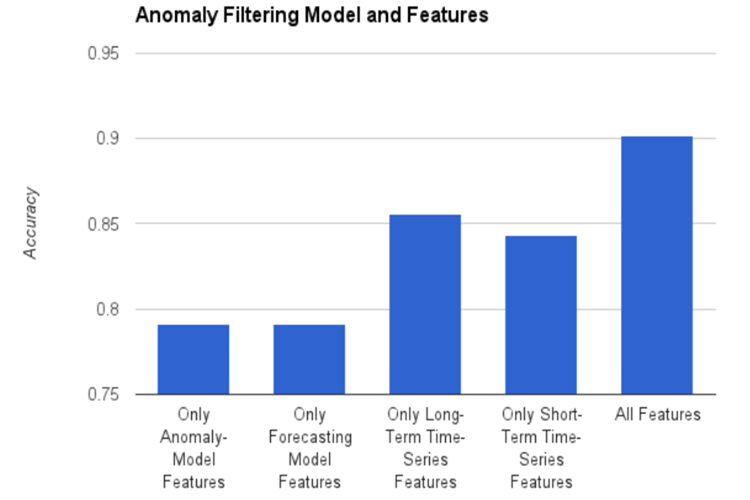
为了解决这个要求,过滤阶段扫描所有模型的所有异常 $a_i$,并使用分类为 $a_i$ 作为真正的模型。在 YM 用例的过滤阶段使用的模型是基于AdaBoost 的增强树模型。AdaBoost 的核心原理是在变化的数据上进行适合一系列 weak learners(例如,小决策树),最后的结果是通过组合加权多数表决产生的。图中的实验结果表明,在滤波阶段使用不同的模型特征,得到比较好的精确率和召回率。
结论
异常检测是许多具有故障应用的实时监控系统的核心部分,检测,欺诈检测,网络入侵检测等等。尽管它至关重要,但实际上实施全自动异常检测系统是一项具有挑战性的任务,这些挑战通常导致解决方案不是可扩展的或高度专业化的,也导致了较高的误报率。
在本文中,我们介绍了 EGADS,雅虎实现的通用异常检测系统,对不同的 Yahoo 属性进行数百万个时间序列进行自动监控和警报。正如我们在本文中所描述的,Hadoop 上的 EGADS 的并行架构以及它通过 Storm 的流处理机制使得它能够在雅虎的数百万个时序数据集上执行实时异常检测。此外,EGADS 采用不同的时间序列建模和异常检测算法来处理不同的监控场景。通过将这一组算法与机器学习机制结合在警报模块中,EGADS 自动适应对用户重要的异常检测用例。所有这些功能都有效地创建了一个功能强大的异常检测框架,它是通用的和可扩展的。我们对真实和综合数据集的展示实验表明,与其竞争对手的解决方案相比,我们的框架具有优越的适用性。
参考链接:
- 大规模时间序列数据自动异常检测架构
- https://github.com/yahoo/egads
- https://webscope.sandbox.yahoo.com/catalog.php?datatype=s&did=70&guccounter=1


