DuckDB简介
DuckDB是一个开源的嵌入式在线分析处理(OLAP)数据库管理系统,专为快速分析查询而设计。它被称为“SQLite for Analytics”,因为它的设计目标是提供类似于SQLite的嵌入式数据库体验,专注于分析工作负载。
DuckDB允许您处理和连接不同格式的本地或远程文件,包括CSV、JSON、Parquet和Arrow,以及MySQL、SQLite和Postgres等数据库。您甚至可以在Python脚本或Jupyter笔记本中查询pandas或Polars数据框。
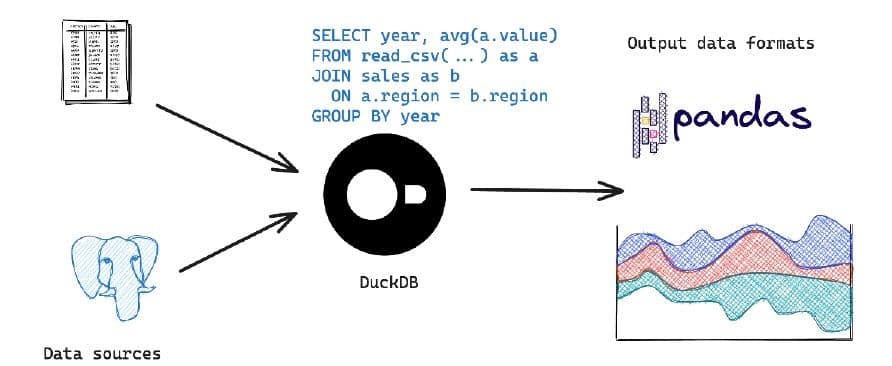
与pandas和Polars库不同,DuckDB是一个真正用于分析的数据库,它实现了高效的数据处理机制,可以在几秒钟内处理海量数据。借助其SQL方言,即使是复杂的查询也可以更简洁地表达。它允许您在数据库内部处理更多操作,避免代价高昂的客户端往返通信。
主要特性
- 嵌入式设计:DuckDB可以直接嵌入到应用程序中,无需独立的服务器进程。这使得它非常适合在本地环境中进行数据分析。
- 列存储格式:采用列存储的方式进行数据存储,这种方式在执行聚合和扫描操作时性能更佳,特别适合于分析型查询。
- SQL支持:提供对标准SQL的广泛支持,包括复杂查询、窗口函数、子查询和聚合操作,能够满足大多数分析需求。
- 高性能:设计上专注于高性能的分析查询,能够有效利用现代硬件的优势,如多核处理器和大内存。
- 跨平台:支持多种操作系统,包括Windows、macOS和Linux,使其能够在各种开发环境中使用。
- 轻量级:由于其嵌入式的特性,DuckDB的二进制文件非常小巧,这使得它能够快速部署和集成。
- 易于集成:提供多种语言的API接口,如Python、R和C++,方便与数据科学工具和工作流进行集成。
- 并行处理:支持并行查询处理,能够在多核系统上显著提升查询性能。
优势和局限
优势:
- 嵌入式:无需设置和管理独立的数据库服务器,简化了部署和使用。
- 高性能:在单节点环境下提供接近于分布式系统的查询性能。
- 简单易用:提供与SQLite类似的使用体验,易于上手。
局限:
- 规模限制:由于是嵌入式数据库,DuckDB更适合中小规模的数据集,对于超大规模的数据可能不如分布式系统。
- 功能限制:虽然支持丰富的SQL功能,但在分布式计算和高可用性等方面不如专门的分布式数据库系统。
应用场景
- 数据科学和机器学习:DuckDB非常适合嵌入到数据科学和机器学习工作流中,用于快速的数据探索和预处理。
- 嵌入式分析:可以直接集成到应用程序中,提供实时的分析功能,而无需依赖外部数据库服务。
- 数据探索和可视化:与Jupyter Notebook等工具结合使用,为数据分析师提供强大的数据查询和分析能力。
不适用场景
虽然DuckDB是一个非常强大的工具,特别适合于嵌入式分析和中小规模的数据集,但在某些情况下,它可能不是最佳选择。以下是一些不适合使用DuckDB的场景:
- 超大规模数据集:DuckDB是一个单节点的嵌入式数据库,虽然它在单机环境下性能优越,但对于超大规模的数据集(例如数TB或PB级别),分布式数据库(如Apache Hive、Presto或Spark)可能更合适,因为它们能够利用集群资源进行并行处理。
- 高并发需求:如果你的应用程序需要处理大量的并发查询或写操作,DuckDB可能不如专门设计用于高并发环境的数据库(如PostgreSQL或MySQL)来得合适。
- 实时事务处理:DuckDB是为分析型工作负载(OLAP)设计的,不适合处理高频次的事务型工作负载(OLTP)。对于需要实时事务处理的应用,传统的关系型数据库系统可能更适合。
- 分布式计算需求:如果你的应用需要在多个节点上进行分布式计算,DuckDB的单节点设计限制了其在分布式环境中的使用。
- 持久化和容错需求:DuckDB的嵌入式特性意味着它通常与应用程序紧密集成,这可能导致在系统崩溃时数据恢复能力较弱。对于需要强大容错和持久化能力的场景,其他数据库系统可能更合适。
- 复杂权限管理:如果你的应用程序需要复杂的用户权限和安全管理,DuckDB的内置功能可能无法满足这些需求。在这种情况下,具有丰富权限管理功能的数据库系统可能更适合。
- 生态系统集成:对于需要深度集成到特定企业级生态系统(如使用特定的消息队列、数据流处理框架等)的应用,可能需要选择支持这些集成的数据库系统。
总之,DuckDB是一个专注于嵌入式和分析型场景的数据库系统,对于那些需要分布式处理、大规模数据管理、高并发处理或复杂事务处理的应用场景,选择其他更合适的数据库系统可能更为明智。
DuckDB使用示例
数据处理流程
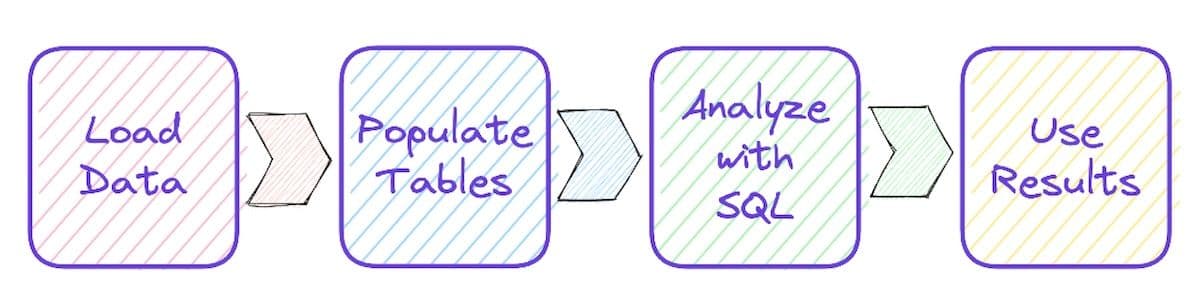
使用DuckDB进行数据处理的一般流程:
- 数据准备
- 确定数据来源:您的数据可以是平面文件(例如CSV、Parquet或JSON),也可以是其他数据库系统(例如Postgres或SQLite)中的数据。
- 选择数据处理方式:您可以临时使用DuckDB来转换、过滤数据并将其传递到另一种格式。在大多数情况下,您会创建持久化数据表,以便后续进行高效分析。在此过程中,您还可以转换和纠正列名、数据类型和值。如果您的输入数据是嵌套文档,可以将其展开并扁平化,以使关系数据分析更加轻松高效。
- 数据探索
- 确定分析需求:您需要弄清楚哪些SQL功能或DuckDB特性可以帮助您进行分析或转换。
- 进行探索性数据分析(EDA):快速获取数据分布、范围和关系的概览。
- 数据分析
- 构建SQL语句:逐步构建相关的SQL语句,并逐个步骤验证生成的样本结果是否符合您的预期。
- 创建辅助表或视图:在此阶段,您可能会创建额外的表或视图,以方便后续使用高级SQL功能(例如窗口函数、公共表表达式和透视表)。
- 结果输出
- 确定结果去向:决定如何使用分析结果,例如将它们转换为文件或数据库,通过应用程序或API提供给用户,或者在Jupyter notebook或仪表板中进行可视化呈现。
数据格式和来源
DuckDB支持多种数据格式和数据源,让您可以轻松检查和分析数据。与其他数据系统(例如SQL Server)不同,您无需预先指定架构细节。当读取数据时,数据库会使用合理的默认值和数据中固有的架构信息,您也可以根据需要进行覆盖。
DuckDB支持多种数据格式,让您可以轻松加载和分析数据:
- CSV文件: 可以批量并行加载CSV文件,并自动映射其列。
- DataFrames内存: DuckDB可以直接处理同一个Python进程中的DataFrame内存,无需复制数据。
- JSON/JSONLines格式: DuckDB可以将JSON或JSONLines格式的数据解构、扁平化并转换为关系型表格。DuckDB还提供JSON数据类型用于存储此类数据。
- Parquet文件: DuckDB可以查询Parquet文件及其架构元数据。查询中使用的谓词会下推到Parquet存储层进行计算,以减少加载的数据量。Parquet是数据湖泊理想的列式格式,可用于读写数据。
Apache Arrow 列式数据: DuckDB 可以通过 Arrow 数据库连接 (ADBC) 访问 Apache Arrow 列式数据,无需复制和转换数据。
DuckDB 的数据结构
DuckDB 支持各种表格、视图和数据类型。对于表格列、处理过程和结果,DuckDB 提供了比传统数据类型更多的选择,例如字符串 (varchar)、数值 (整数、浮点数、十进制数)、日期、时间戳、间隔、布尔值和 BLOB (大二进制对象)。
DuckDB 还支持结构化数据类型,例如枚举、列表、映射 (字典) 和结构体。
- 枚举 (enum) 是集合中经过索引的命名元素,可以高效存储和处理。
- 列表 (list) 或数组 (array) 可以容纳多个相同类型的元素,并且提供各种操作列表的函数。
- 映射 (map) 是高效的键值对,用于保存键控数据点。它们在 JSON 处理过程中使用,可以通过多种方式构建和访问。
- 结构体 (struct) 是一致的键值结构,其中相同的键始终具有相同数据类型的的值。这使得结构体的存储、推理和处理更加高效。
DuckDB 还允许您创建自己的类型,扩展功能也可以提供额外的的数据类型。DuckDB 可以通过表达式创建虚拟列或派生列,这些列由其他数据派生而来。
开发 SQL 查询
在分析数据时,您通常会从理解数据结构开始。然后,您可以从简单的查询逐步创建更复杂的查询。
您可以使用 DESCRIBE 命令来了解数据源、表格和视图的列和数据类型。掌握这些信息后,您可以通过运行计数查询 (count(*)) 在全局范围内或按时间、位置或项目类型等维度进行分组,来获取数据集的基本统计信息和分布。这可以让您初步了解可用数据的一些情况。
DuckDB 甚至还提供了一个 SUMMARIZE 子句,可以为您提供按列的统计信息:
- count
- min, max, avg, std (标准差)
- approx_unique (估计的 distinct 值计数)
- percentiles (百分位数 q25、q50、q75)
- null_percentage (数据中为 null 的部分)
为了编写分析查询,您可以先使用 LIMIT 子句处理数据子集,或者只查看单个输入文件。首先概述您需要的结果列(这些列有时可能会进行转换,例如使用 strftime 格式化日期)。这些是您需要按其分组的列。然后根据需要对数据应用聚合和过滤器。DuckDB 提供了许多不同的聚合函数,从传统的 min, avg, sum 到更高级的函数,例如 histogram, bitstring_agg, list 或近似值函数(例如 approx_count_distinct)。还有一些高级聚合函数,包括百分位数、熵或回归计算以及偏度。对于运行总计以及与前后行的比较,您可以使用窗口函数聚合 OVER (PARTITION BY column ORDER BY column2 [RANGE…])。分析语句中重复使用的一部分可以提取成命名的公共表表达式 (CTE) 或视图。为了提高可读性,还可以将计算的一部分移动到子查询中,并使用其结果来检查是否存在或进行一些嵌套数据准备。
在构建分析语句时,您可以随时检查结果以确保它们仍然正确,并且您没有走错路。这将引导我们进入有关使用查询结果的下一个也是最后一个部分。
使用或处理结果
您已经编写了语句并从 DuckDB 快速获得了分析结果。现在该做什么呢?
编写完语句并从 DuckDB 快速获得分析结果后,您可能会想知道如何利用这些结果。这里提供了一些常用的方法:
保存结果
将结果保留以便日后使用或与其他数据进行比较会非常有用。DuckDB 提供了多种方式保存结果:
- 创建表格: 使用 CREATE TABLE <名称> AS SELECT… 语句可以轻松地将结果创建为一个永久表格。
- 导出文件: DuckDB 支持将结果导出为多种格式的文件,例如 CSV、JSON、Parquet、Excel 和 Arrow。
- 其他数据库格式: 通过自定义扩展,DuckDB 还支持将结果导出为 SQLite、Postgres 等其他数据库格式。
- DuckDB 命令行界面 (CLI): 对于较小的结果集,您可以使用 DuckDB CLI 将数据直接输出为 CSV 或 JSON 格式。
数据可视化
俗话说“百闻不如一见”,可视化的图表通常比阅读原始数据更直观易懂。DuckDB 提供了一些数据可视化选项:
- 内置 bar 函数: 使用此函数可以在终端直接生成数据的条形图。
- 命令行绘图工具: 您可以使用一些命令行绘图工具(例如 youplot)快速生成结果的图表。
高级可视化:
对于更复杂的可视化需求,您可以借助庞大的 Python 和 Javascript 生态系统。具体步骤如下:
- 转换结果为 DataFrame: 将 DuckDB 的查询结果转换为 DataFrame 格式。
- 绘图工具: 使用 Python 的 matplotlib 或 ggplot、R 的 ggplot2 或 Javascript 的 d3、nivo、observable 等库将 DataFrame 转换为各种类型的图表。
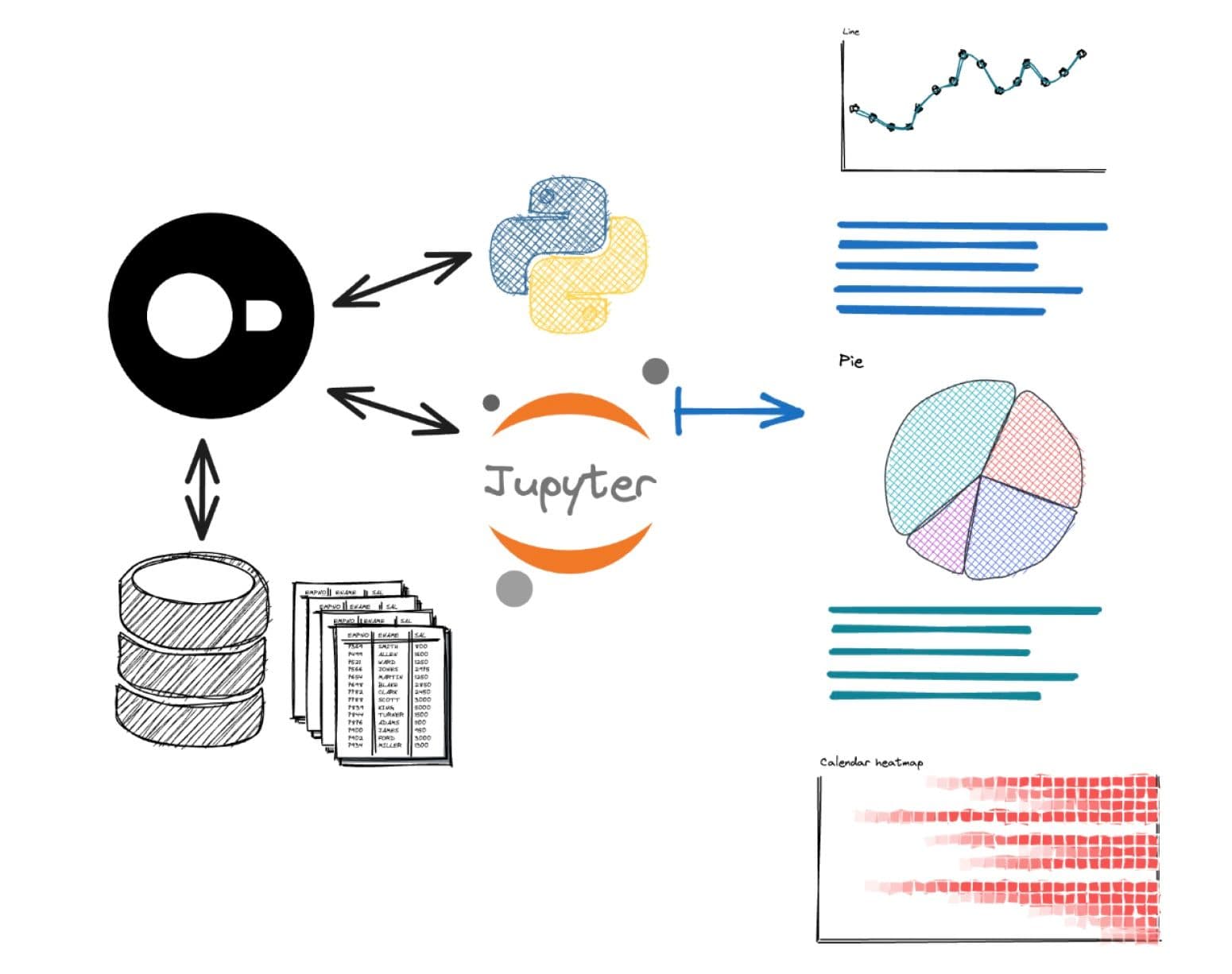
得益于 DuckDB 的高效运行,您可以直接将查询结果提供给 API 端点,供您或其他人以后使用,或者将其集成到 Streamlit 等应用程序中进行处理。
Python 使用 DuckDB 示例
安装 DuckDB
首先,你需要安装 DuckDB。可以通过多种方式安装,比如在 Python 环境中:pip install duckdb在 Python 中使用
import duckdb
# 创建一个内存数据库连接
con = duckdb.connect(database=':memory:')
# 创建一个表
con.execute('CREATE TABLE users (id INTEGER, name VARCHAR, age INTEGER)')
# 插入数据
con.execute("INSERT INTO users VALUES (1, 'Alice', 30), (2, 'Bob', 25), (3, 'Charlie', 35)")
# 查询数据
result = con.execute('SELECT * FROM users WHERE age > 30').fetchall()
print(result) # 输出: [(3, 'Charlie', 35)]
# 关闭连接
con.close()
其他特性
DuckDB 支持读取和写入多种数据格式,例如 CSV、Parquet 和 JSON。以下是一个读取 CSV 文件的示例:
# 假设你有一个 CSV 文件名为 'data.csv'
con.execute("CREATE TABLE data AS SELECT * FROM 'data.csv'")
result = con.execute("SELECT * FROM data").fetchall()
print(result)
参考链接:


