CrewAI简介
CrewAI是一个基于LangChain构建的多智能体框架,其设计目标是通过促进协作智能,使AI智能体能够无缝协作处理复杂的任务。它专注于协调角色扮演的自主AI Agent,通过使用LLM大语言模型作为协调器来促进协作,使得多个Agent像一个默契十足的团队一样工作,每个Agent扮演不同的角色,共同完成一项大的任务。
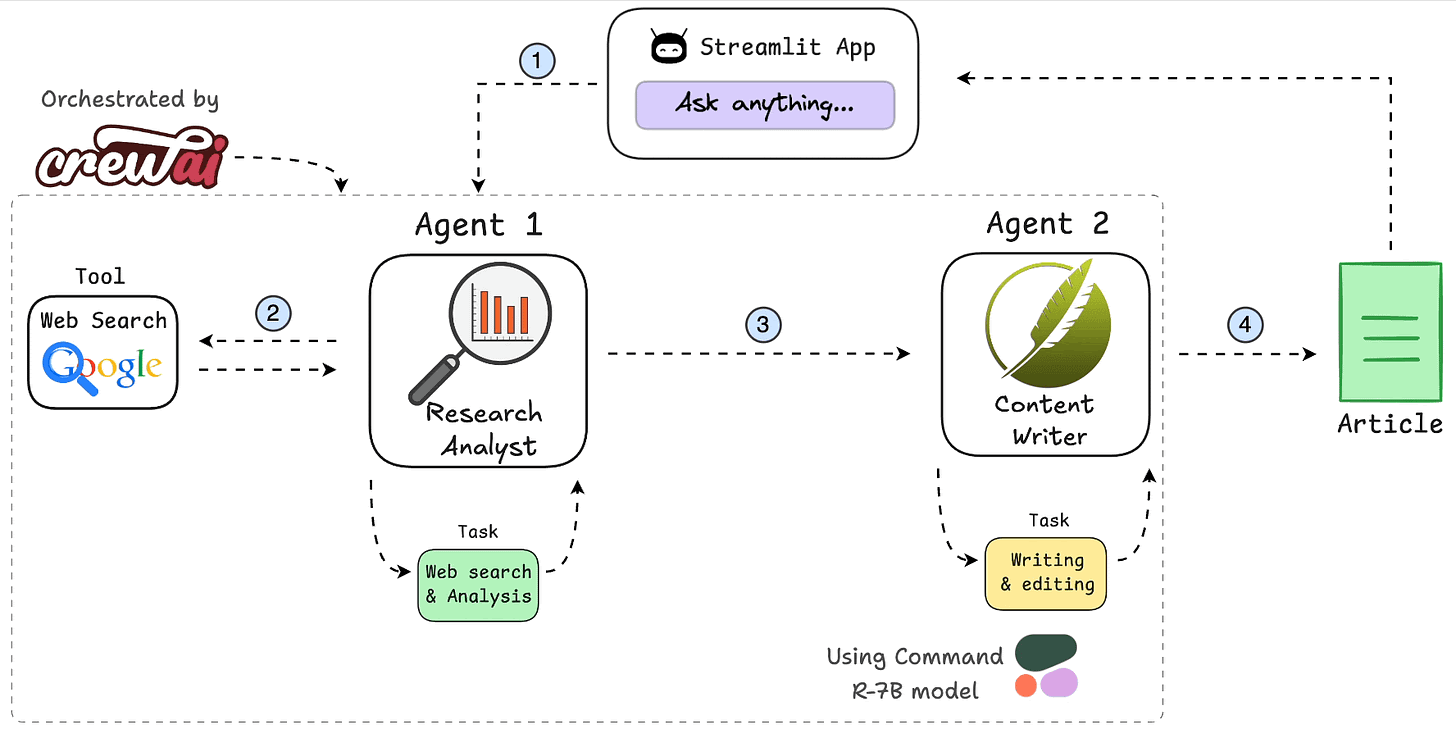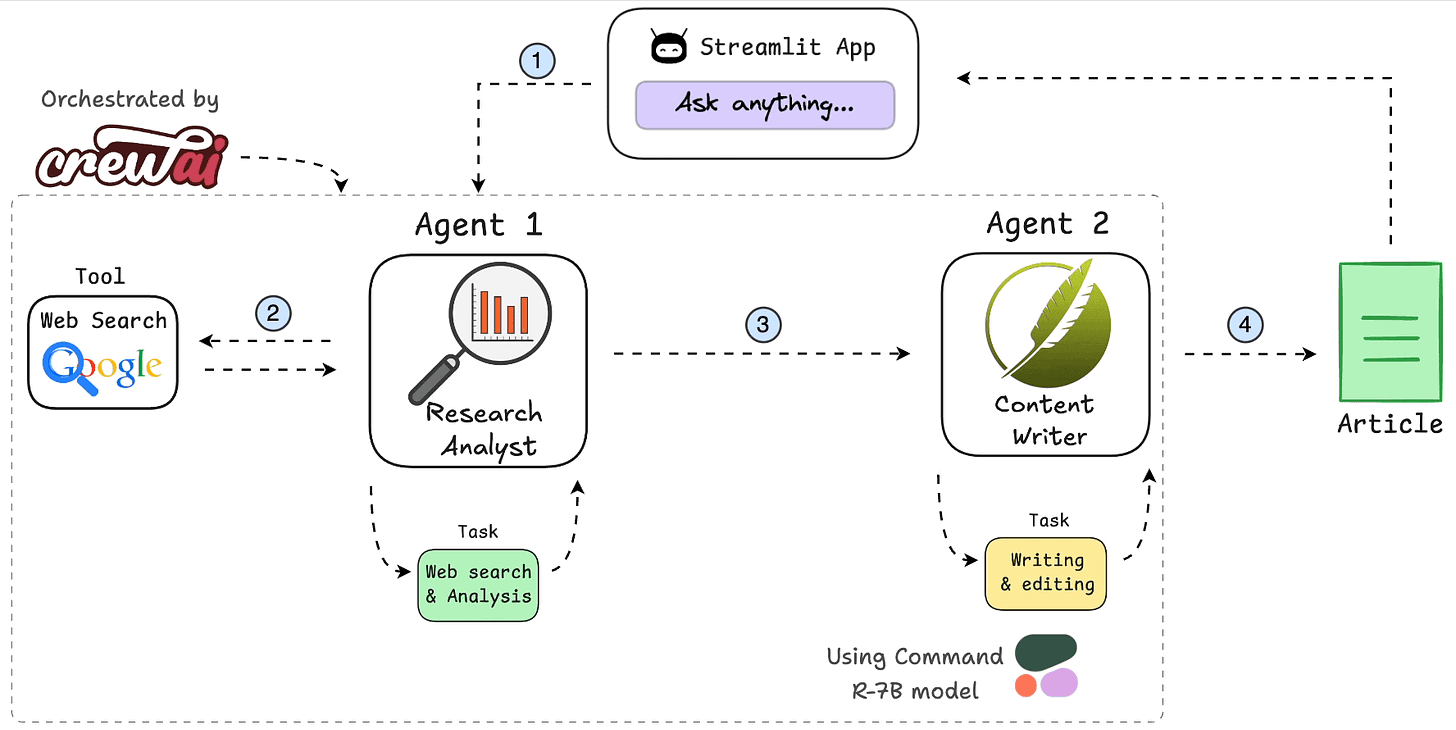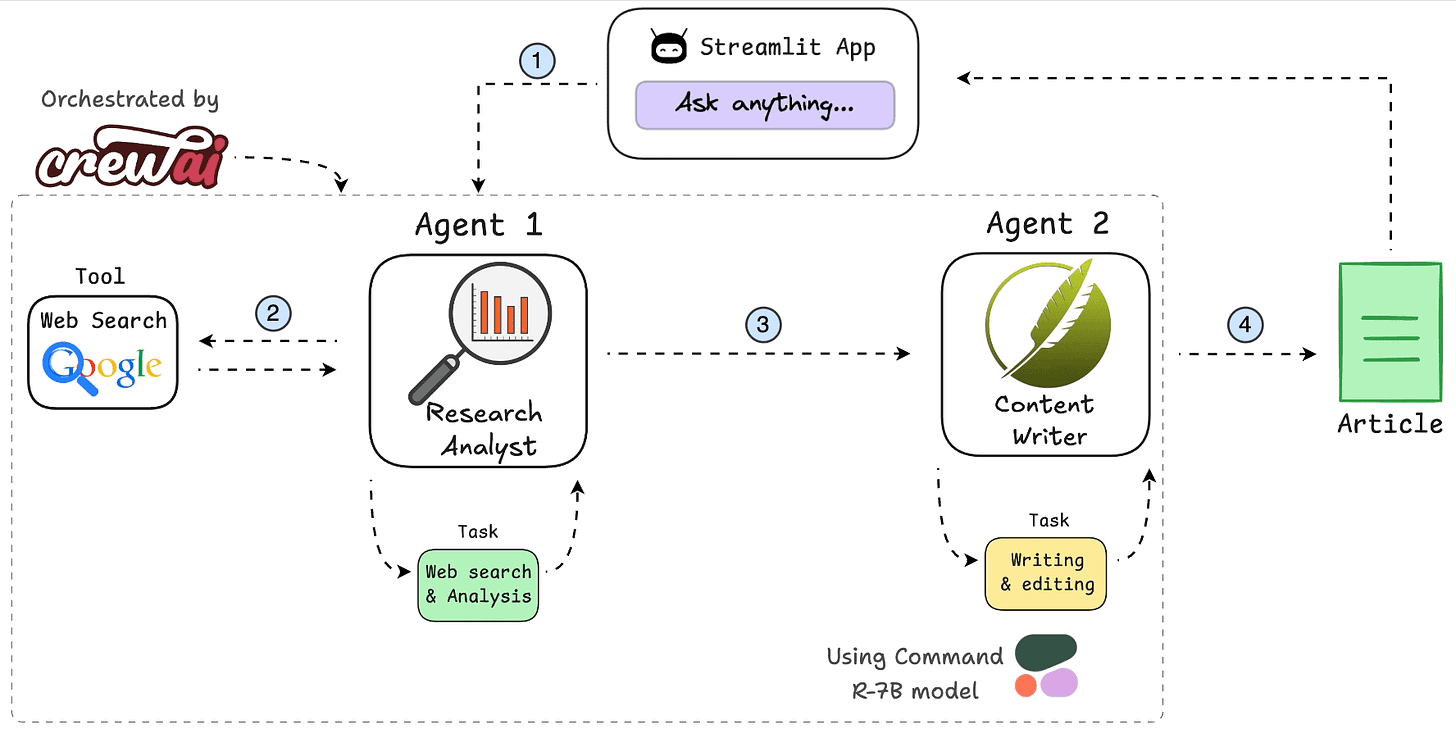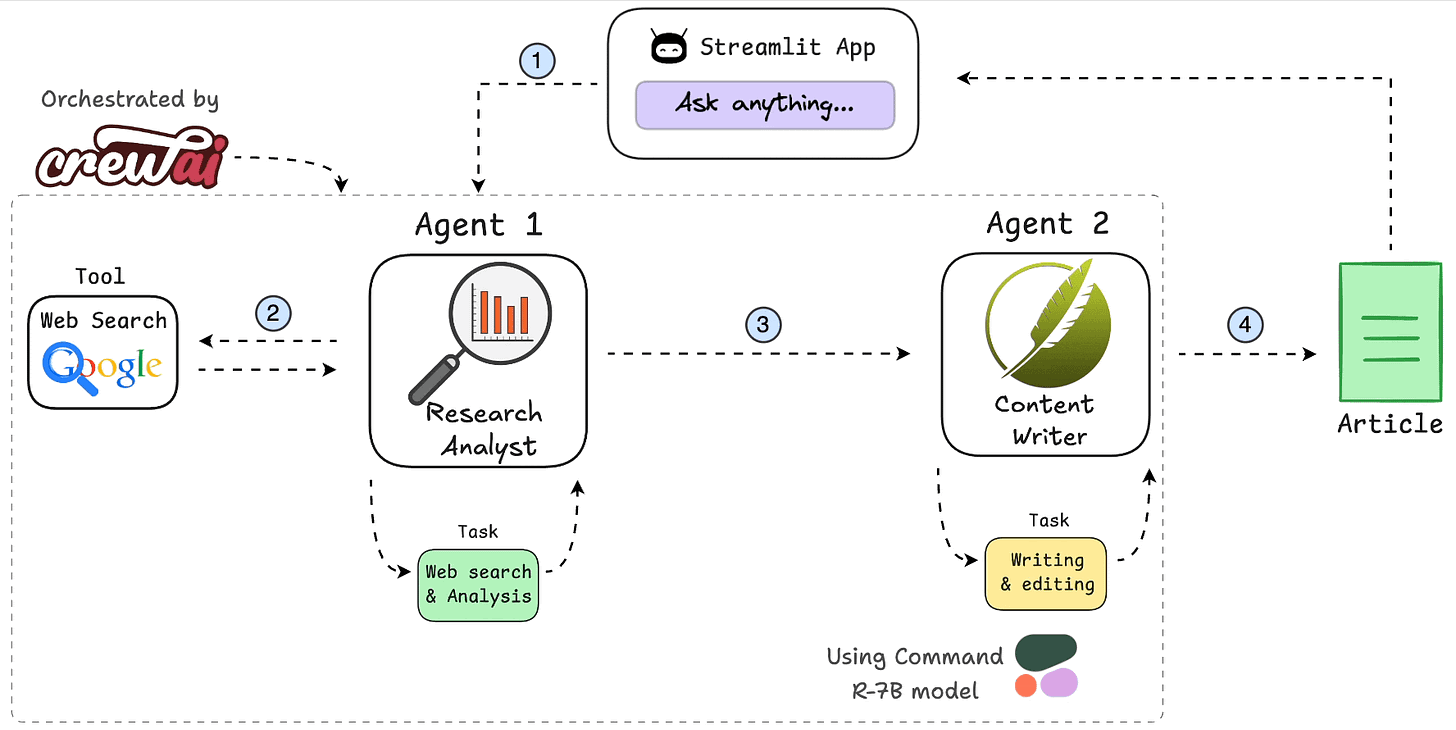
核心特性
- 多智能体协作:
- CrewAI允许用户创建多个AI代理,每个代理可以扮演不同的角色,如项目经理、产品经理、开发人员等,通过协作完成复杂任务。
- 这些代理能够无缝协作,处理复杂问题,其能力远超单个智能体系统。
- 灵活的任务管理:
- 支持自定义任务,用户可以动态地定义和分配任务给不同的代理。
- 提供了灵活的任务管理方式,包括顺序执行和层级流程,并且正在研发更复杂的流程管理方式,如基于共识和自主决策的流程。
- 基于角色的代理设计:
- 用户可以为代理定制特定的角色、目标和工具,以满足不同的需求。
- 每个代理都有自己的角色定位和任务目标,能够根据自己的角色执行相应的任务。
- 自主代理间任务委托:
- 代理之间能够自主地委托任务并在彼此之间询问,提高了问题解决的效率。
- 这种自主性使得CrewAI在处理复杂任务时更加灵活和高效。
- 与开源模型兼容:
- CrewAI支持多种大型语言模型(LLMs),包括OpenAI和开源模型,如GPT系列、GLM等。
- 这为用户提供了模型选择的灵活性,可以根据具体任务需求选择合适的模型。
- 动态和适应性的过程设计:
- 支持动态调整任务流程和代理配置,以适应不同的应用场景和需求变化。
- 提供了可定制的工具集,用户可以根据需要添加或删除工具。
核心功能
- 智能体分工与角色定义
- 开发者可自定义智能体的角色、目标、工具(Tools)和决策逻辑。
- 示例角色:
- 研究员:负责数据收集和分析。
- 文案写手:生成报告或内容。
- 审核员:验证结果准确性。
- 任务分解与分配
- CrewAI自动将复杂任务拆分为子任务,并根据智能体的能力动态分配。
- 支持任务间的依赖关系管理(如任务B需在任务A完成后启动)。
- 通信与上下文共享
- 智能体通过共享上下文(如中间结果、关键数据)协作,避免重复工作。
- 支持异步通信和实时协调。
- 工具集成
- 智能体可调用外部工具(如搜索引擎、数据库、API)或自定义函数(如Python脚本)。
- 决策与自治
- 智能体根据预设规则或LLM(如GPT-4)生成决策,决定下一步行动。
应用场景
- 自动化工作流。例如:自动生成市场报告(研究→分析→撰写→审核)。
- 复杂问题解决。例如:调试代码错误(分解问题→分派给不同专家智能体)。
- 模拟与培训。例如:模拟客户服务团队处理咨询。
- 数据密集型任务。例如:多步骤数据分析(清洗→建模→可视化)。
CrewAI的架构
CrewAI 架构全景图
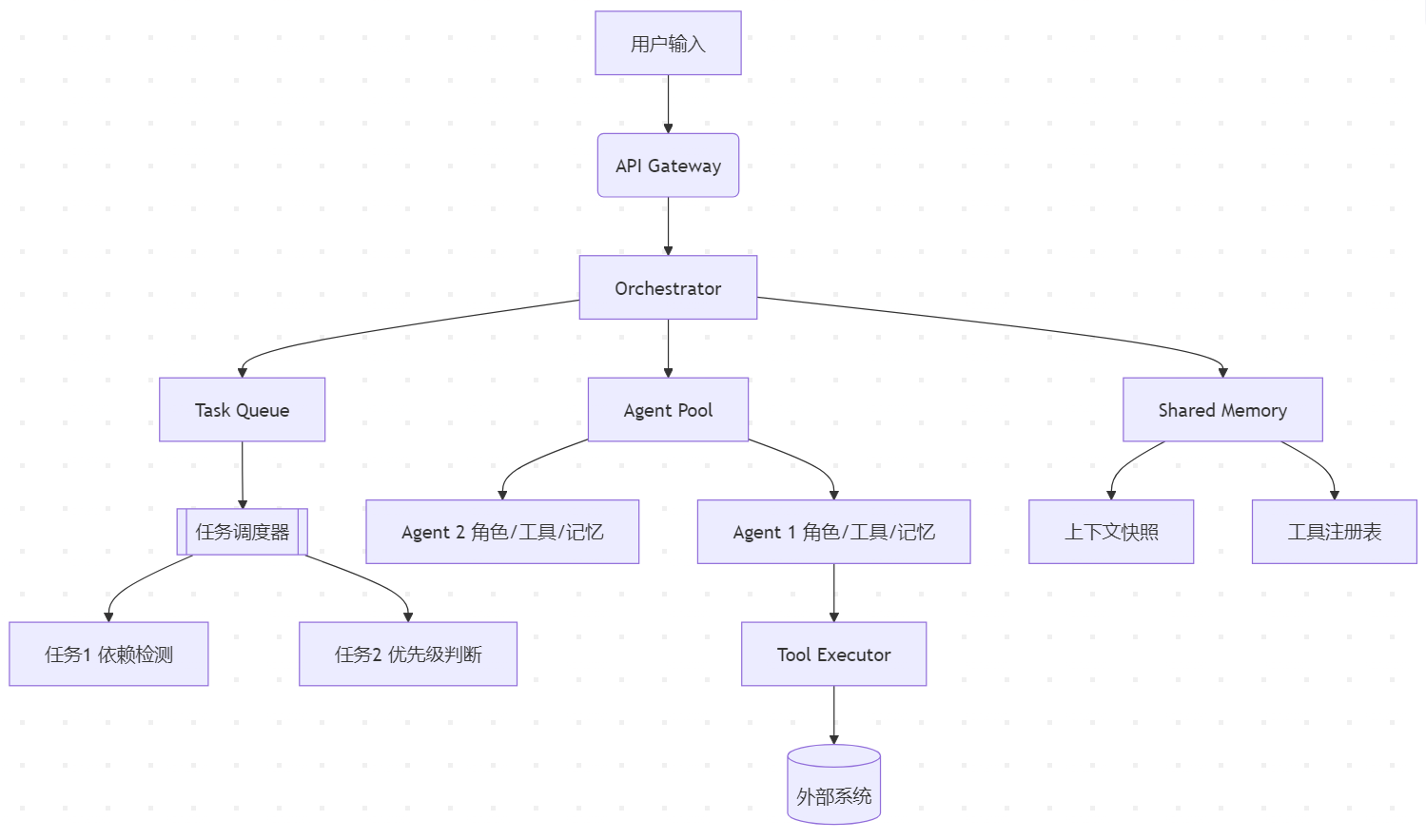
核心模块分解
协调控制层 (Orchestration Layer)
任务解析器 (Task Parser)
class TaskParser:
def parse(self, user_input: str) -> Dict:
# 使用LLM进行意图识别
intent = self.llm.classify_intent(user_input)
# 知识图谱驱动的任务分解
return self.knowledge_graph.split(intent)
- 功能:将自然语言请求转换为结构化任务树
- 关键技术:BERT+CRF的意图识别模型
智能体执行层 (Agent Layer)
智能体实例结构
class Agent:
def __init__(self, config: AgentConfig):
self.role: str = config.role # 角色定义
self.tools: ToolRegistry = config.tools # 工具集合
self.memory: VectorDB = FAISS() # 向量记忆库
self.policy: PolicyNetwork = load_policy() # 决策模型
- 内存管理:采用分层记忆机制
- 短期记忆:环形缓冲区存储最近10条交互
- 长期记忆:向量数据库存储关键知识片段
任务调度层 (Task Scheduler)
优先级调度算法
def schedule(tasks: List[Task]) -> List[Task]:
# 基于强化学习的动态优先级算法
state = get_system_state()
q_values = rl_model.predict(state, tasks)
return sorted(zip(tasks, q_values),
key=lambda x: x[1], reverse=True)
- 调度策略:混合Q-Learning与启发式规则
- 关键指标:任务依赖度、资源占用预估、截止时间
关键数据流分析
任务执行流程
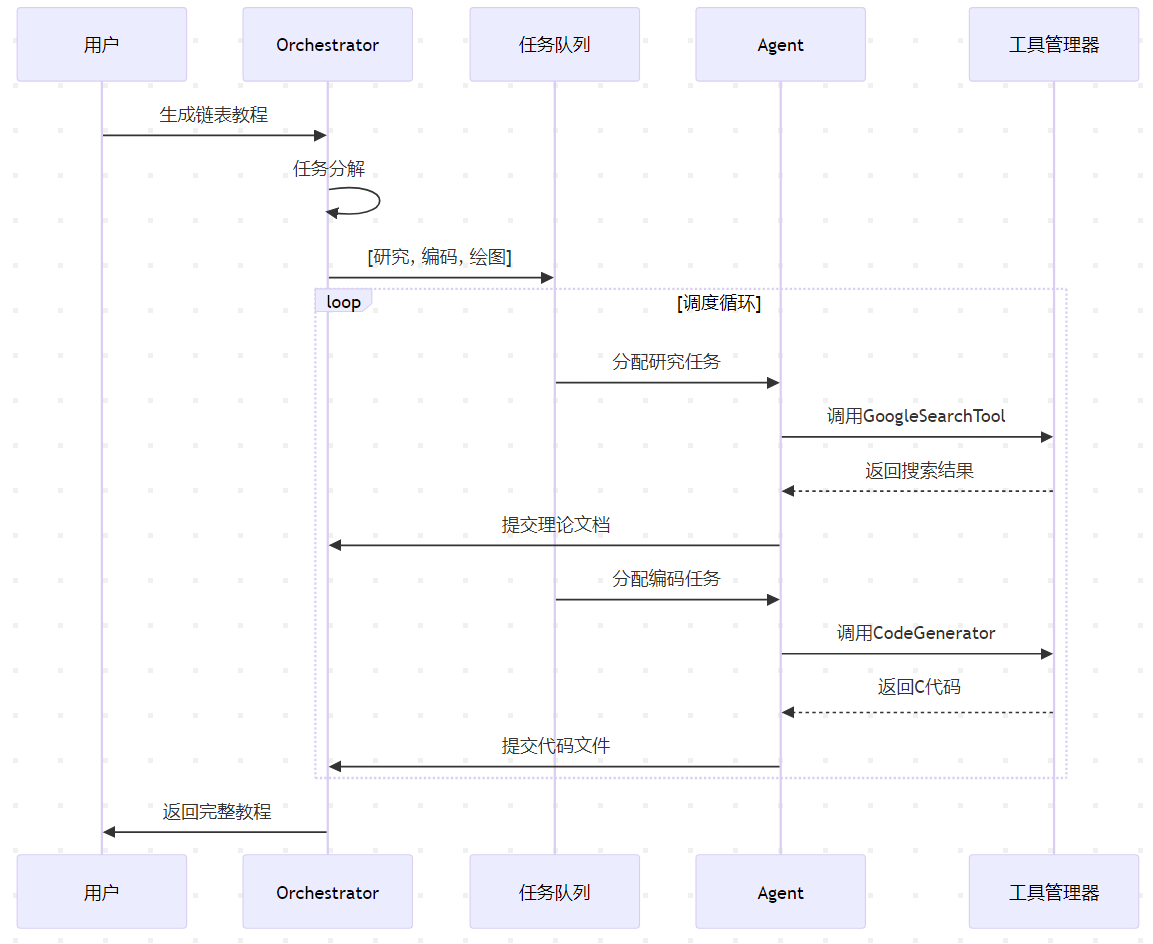
上下文共享机制
分布式黑板系统
class Blackboard:
def __init__(self):
self.sections: Dict[str, Any] = {} # 数据分区
self.lock: RWLock = RWLock() # 读写锁
def write(self, key: str, value: Any):
with self.lock.writer_lock():
self.sections[key] = value
def read(self, key: str) -> Any:
with self_lock.reader_lock():
return self.sections.get(key)
- 数据版本控制:采用MVCC机制
- 冲突解决:基于时间戳的最终一致性
扩展性设计
插件化工具接口
class ToolInterface(ABC):
@abstractmethod
def execute(self, params: dict) -> dict:
pass
class CustomTool(ToolInterface):
def __init__(self, config):
self.api_client = APIClient(config.endpoint)
def execute(self, params):
return self.api_client.call(params)
横向扩展方案
Agent 集群管理
class AgentCluster:
def __init__(self):
self.agents: Dict[str, Agent] = {}
self.load_balancer = RoundRobinLB()
def dispatch(self, task: Task) -> Agent:
capable_agents = [a for a in self.agents.values()
if a.can_handle(task)]
return self.load_balancer.select(capable_agents)
- 自动发现机制:基于etcd的服务注册
- 负载策略:支持加权轮询/最少连接数
性能优化策略
预测性预热
def preheat_agents():
# 分析历史任务模式
common_tasks = analyze_logs()
for task in common_tasks:
agent = find_best_agent(task)
agent.preload(task.context)
结果缓存
class ResultCache:
def __init__(self):
self.cache = LRUCache(capacity=1000)
self.semantic_checker = SentenceTransformer('all-MiniLM-L6-v2')
def get(self, query: str) -> Optional[dict]:
embedding = self.semantic_checker.encode(query)
return self.cache.get_nearest(embedding)
安全架构
沙箱执行环境
# Docker沙箱配置 FROM python:3.9-slim RUN apt-get update && apt-get install -y seccomp COPY policy.json /etc/seccomp/ CMD ["python", "-u", "/app/sandbox.py"]
- 安全策略:
- 禁止系统调用:clone, ptrace
- 限制资源:CPU 30%, 内存1GB
审计追踪
class AuditLogger:
def log(self, event: AuditEvent):
# 区块链存证
block = {
'timestamp': time.time(),
'hash': sha256(event.data),
'prev_hash': last_block_hash
}
ipfs.store(block)
该架构通过模块化设计实现了高度可扩展性,在测试环境中可实现每分钟处理200+复杂任务。实际部署时建议重点关注任务调度算法优化和分布式缓存的一致性维护。
CrewAI核心概念
CrewAI是一个开源的Python框架,用于创建和管理由多个AI代理组成的系统。它的主要目标是简化复杂AI系统的开发过程,让开发者能够更容易地构建和协调多个AI代理之间的协作。以下是CrewAI的一些主要特点和概念:
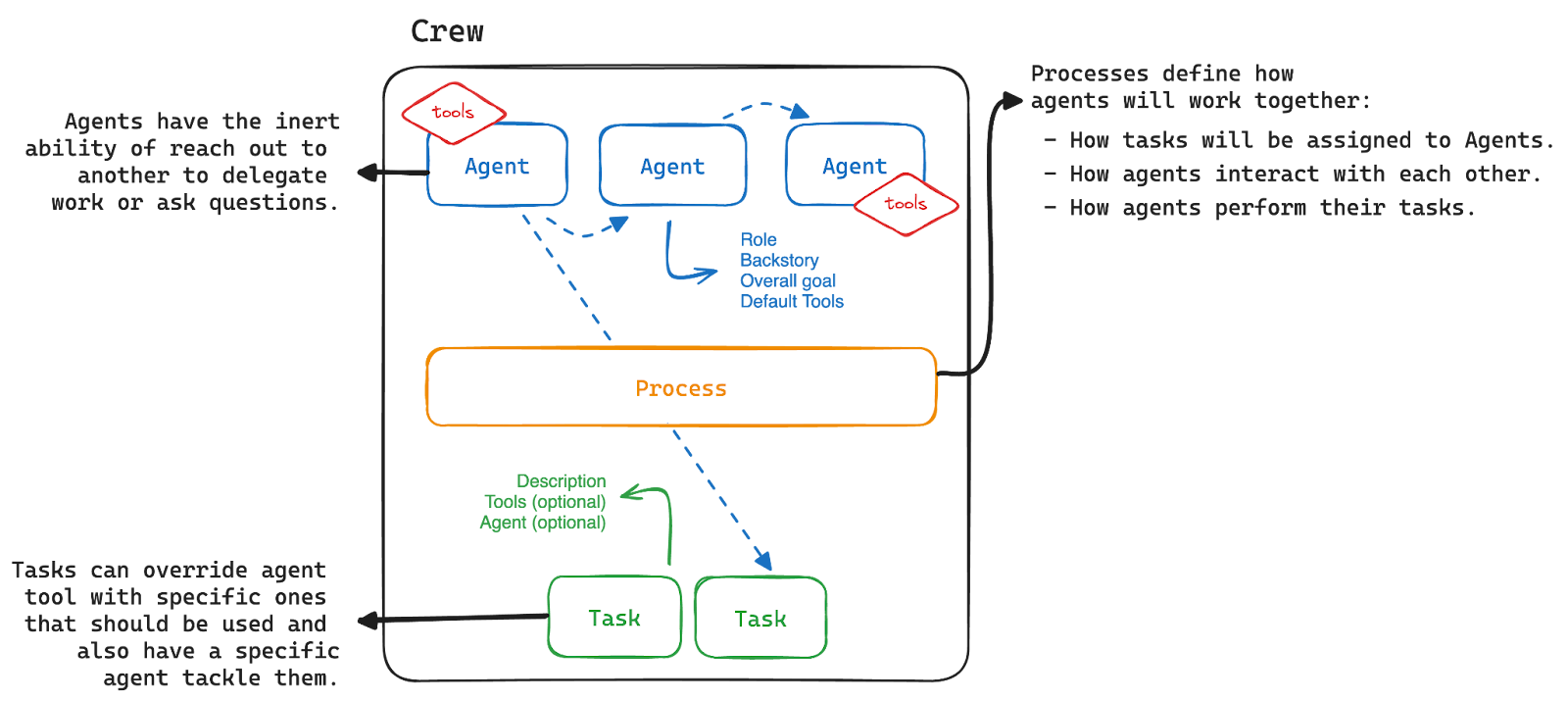
Agent(代理)
代理是 crewAI 平台中的自主实体,每个代理都旨在执行特定任务、做出决策并与其他代理交互。代理是 crewAI 系统内活动的主要驱动者,体现了有助于实现船员总体目标的角色。
代理属性
| 属性 | 参数 | 描述 |
| 角色 | role | 定义代理在班组中的职能。它确定代理最适合的任务类型。 |
| 目标 | goal | 代理者旨在实现的单个目标。它指导代理的决策过程。 |
| 背景故事 | backstory | 为座席的角色和目标提供上下文,丰富交互和协作动态。 |
| LLM(可选) | llm | 表示将运行代理的语言模型。它从环境变量中动态获取模型名称,如果未指定,则默认为 “gpt-4”。OPENAI_MODEL_NAME |
| 工具(可选) | tools | 代理可用于执行任务的功能或函数集。应为与代理的执行环境兼容的自定义类的实例。工具使用空列表的默认值进行初始化。 |
| 函数调用 LLM(可选) | function_calling_llm | 指定将处理此代理程序的工具调用的语言模型,如果传递,则覆盖调用 LLM 的 crew 函数。默认值为 。None |
| Max Iter (可选) | max_iter | Max Iter 是代理在被迫给出其最佳答案之前可以执行的最大迭代次数。默认值为 。25 |
| 最大 RPM(可选) | max_rpm | Max RPM (最大 RPM) 是代理每分钟可以执行的最大请求数,以避免速率限制。它是可选的,可以不指定,默认值为 .None |
| Max Execution Time (可选) | max_execution_time | Max Execution Time (最大执行时间) 是代理执行任务的最长时间。它是可选的,可以不指定,默认值为 ,表示没有最大执行时间。None |
| 详细 (可选) | verbose | 将此项设置为配置内部 Logger 以提供详细的执行日志,从而帮助调试和监控。默认值为 。TrueFalse |
| 允许委派(可选) | allow_delegation | 代理可以将任务或问题委派给彼此,确保每个任务都由最合适的代理处理。默认值为 。False |
| Step Callback (可选) | step_callback | 在代理的每个步骤之后调用的函数。这可用于记录代理的操作或执行其他操作。它将覆盖 crew 。step_callback |
| 缓存 (可选) | cache | 指示代理是否应使用缓存来使用工具。默认值为 。True |
| 系统模板(可选) | system_template | 指定代理的系统格式。默认值为 。None |
| 提示模板 (可选) | prompt_template | 指定代理的提示格式。默认值为 。None |
| 响应模板(可选) | response_template | 指定代理的响应格式。默认值为 。None |
| 允许代码执行(可选) | allow_code_execution | 为代理启用代码执行。默认值为 。False |
| Max Retry Limit (最大重试限制) (可选) | max_retry_limit | 发生错误时代理执行任务的最大重试次数。默认值为 。2 |
| 使用系统提示符(可选) | use_system_prompt | 添加了不使用系统提示符的功能(以支持 o1 模型)。默认值为 。True |
| Respect Context 窗口(可选) | respect_context_window | 避免上下文窗口溢出的 Summary 策略。默认值为 。True |
Task(任务)
在 crewAI 框架中,任务是由代理完成的特定任务。它们提供执行所需的所有详细信息,例如描述、负责的代理、所需的工具等,从而促进各种操作的复杂性。crewAI 中的任务可以是协作的,需要多个代理一起工作。这是通过任务属性进行管理的,并由 Crew 的流程进行编排,从而增强团队合作和效率。
任务属性
| 属性 | 参数 | 类型 | 描述 |
| 描述 | description | str | 对任务内容的清晰、简洁的陈述。 |
| 代理 | agent | Optional[BaseAgent] | 负责任务的代理,直接分配或由班组的流程分配。 |
| 预期输出 | expected_output | str | 任务完成情况的详细说明。 |
| 工具(可选) | tools | Optional[List[Any]] | 代理可以用来执行任务的功能。默认为空列表。 |
| 异步执行(可选) | async_execution | Optional[bool] | 如果设置,任务将异步执行,无需等待完成即可继续进行。默认为 False。 |
| 上下文 (可选) | context | Optional[List[“Task”]] | 指定其输出用作此任务的上下文的任务。 |
| Config (可选) | config | Optional[Dict[str, Any]] | 执行任务的代理的其他配置详细信息,允许进一步自定义。默认为 None。 |
| 输出 JSON(可选) | output_json | Optional[Type[BaseModel]] | 输出一个 JSON 对象,需要一个 OpenAI 客户端。只能设置一种输出格式。 |
| 输出 Pydantic (可选) | output_pydantic | Optional[Type[BaseModel]] | 输出 Pydantic 模型对象,需要 OpenAI 客户端。只能设置一种输出格式。 |
| 输出文件(可选) | output_file | Optional[str] | 将任务输出保存到文件中。如果与 或 一起使用,则指定如何保存输出。Output JSONOutput Pydantic |
| 输出(可选) | output | Optional[TaskOutput] | 的实例 ,包含 raw、JSON 和 Pydantic 输出以及其他详细信息。TaskOutput |
| 回调 (可选) | callback | Optional[Any] | 在完成时与任务的输出一起执行的可调用对象。 |
| 人工输入(可选) | human_input | Optional[bool] | 指示任务是否应在结束时涉及人工审核,这对于需要人工监督的任务非常有用。默认为 False。 |
| Converter 类(可选) | converter_cls | Optional[Type[Converter]] | 用于导出结构化输出的 converter 类。默认为 None。 |
Tools(工具)
CrewAI 中的工具是代理可以用来执行各种操作的技能或功能。这包括来自 crewAIInc/crewAI-tools (github.com) 和 Tools | 🦜️🔗 LangChain 的工具,支持从简单的搜索到复杂的交互和代理之间的有效团队合作。
crewAI 中的工具本质上是代理功能的扩展,旨在提高其执行任务的效率。这些工具无缝集成到代理的工作流程中,使它们能够执行从简单查找到复杂分析过程的广泛操作。
工具特点
- 实用程序:开发工具是为了协助完成各种任务,包括但不限于网络搜索、数据分析、内容生成,甚至与其他数字系统的直接交互。
- 集成:工具旨在无缝集成到代理的工作流程中,在不破坏其核心功能的情况下增强其自然能力。
- 可定制性:CrewAI 提供了开发自定义工具或利用现有工具的灵活性,确保代理可以根据特定的操作需求进行定制。
- 错误处理:每个工具都包含强大的错误处理机制,以确保操作顺利进行而不会中断。
- 缓存机制:采用智能缓存来优化性能并减少操作冗余,使系统更高效、响应更快。
Crew(团队)
CrewAI 中的Crew代表一组协同工作的代理,他们共同完成一系列任务。每个Crew都定义了任务执行、代理协作和整体工作流程的策略。
Crew属性
| 属性 | 参数 | 描述 |
| 任务 | tasks | 分配给班组的任务列表。 |
| 代理 | agents | 属于团队的代理列表。 |
| 流程(可选) | process | 班组遵循的流程流(例如,顺序、分层)。默认值为 。sequential |
| 详细 (可选) | verbose | 执行期间日志记录的详细级别。默认为 。False |
| Manager LLM(可选) | manager_llm | Manager Agent 在分层流程中使用的语言模型。使用分层流程时是必需的。 |
| 函数调用 LLM(可选) | function_calling_llm | 如果通过,船员将使用此 LLM 为船员中的所有特工执行调用工具的功能。每个代理都可以有自己的 LLM,该 LLM 会覆盖班组的 LLM 以进行函数调用。 |
| Config (可选) | config | 班组的可选配置设置,in 或 format。JsonDict[str, Any] |
| 最大 RPM(可选) | max_rpm | 班组在执行期间遵守的每分钟最大请求数。默认为 。None |
| 语言 (可选) | language | 班组使用的语言默认为英语。 |
| 语言文件(可选) | language_file | 要用于班组的语言文件的路径。 |
| 内存(可选) | memory | 用于存储执行记忆(短期、长期、实体记忆)。默认为 。False |
| 缓存 (可选) | cache | 指定是否使用缓存来存储工具的执行结果。默认为 。True |
| Embedder(可选) | embedder | 班组要使用的嵌入器的配置。目前主要由 memory 使用。默认值为 。{“provider”: “openai”} |
| 全输出(可选) | full_output | 班组是应返回包含所有任务输出的完整输出,还是仅返回最终输出。默认为 。False |
| Step Callback (可选) | step_callback | 在每个代理的每个步骤之后调用的函数。这可用于记录代理的操作或执行其他操作;它不会覆盖特定于代理的 .step_callback |
| Task Callback (可选) | task_callback | 在每个任务完成后调用的函数。对于任务执行后的监控或其他操作非常有用。 |
| Share Crew (可选) | share_crew | 您是否想与 crewAI 团队共享完整的船员信息和执行情况,以使库变得更好,并允许我们训练模型。 |
| Output Log File (输出日志文件) (可选) | output_log_file | 是否希望拥有包含完整 crew 输出和执行的文件。您可以使用 True 进行设置,它将默认为您当前所在的文件夹,并且它将以 logs.txt 调用或传递具有文件完整路径和名称的字符串。 |
| Manager Agent (可选) | manager_agent | manager设置将用作 Manager 的自定义代理。 |
| Manager 回调(可选) | manager_callbacks | manager_callbacks获取使用分层流程时由 Manager Agent 执行的回调处理程序列表。 |
| 提示文件(可选) | prompt_file | 要用于班组的提示 JSON 文件的路径。 |
| 规划(可选) | planning | 为 Crew 添加规划功能。在每次 Crew 迭代之前激活时,所有 Crew 数据都会发送到 AgentPlanner,该 AgentPlanner 将规划任务,并且此计划将添加到每个任务描述中。 |
| 规划 LLM(可选) | planning_llm | AgentPlanner 在规划过程中使用的语言模型。 |
Process(流程)
在 CrewAI 中,流程编排代理执行任务,类似于人类团队中的项目管理。这些流程可确保任务按照预定义的策略高效分配和执行。
Process 是根据任务的性质和复杂程度进行定制的。不同的任务可能需要不同的 Process 来达到最佳效果。Process 可以包括任务的分解、资源的分配、沟通协调等环节,旨在最大限度地提高团队的工作效率和任务完成质量。
Process 的设计也可以根据经验和实践进行不断优化和改进。通过对 Process 的不断迭代和优化,团队可以提高工作效率、减少错误和风险,并提供更好的团队协作和成果交付。
流程实施
- 顺序:按顺序执行任务,确保任务有序完成。
- 分层:在管理层次结构中组织任务,其中任务根据结构化的命令链进行委派和执行。必须在班组中指定manager_llm或自定义manager_agent才能启用分层流程,从而方便经理创建和管理任务。
- 共识流程(计划):为了实现代理之间对任务执行的协作决策,这种流程类型在 CrewAI 中引入了一种民主的任务管理方法。它计划用于未来的开发,目前尚未在代码库中实现。
CrewAI使用教程
安装与初始化
安使用pip安装CrewAI包:pip install crewai
若需要安装附加工具包,则使用:pip install ‘crewai[tools]’
或者使用:pip install crewai crewai-tools
项目管理2种方式
Crewai项目管理的2种方式:
- 纯代码的方式,也就是手动创建Python文件,编写代理、任务和流程的代码。这种方法灵活,适合有经验的开发者,可以根据需要自定义每个部分,不需要依赖项目结构。
- 命令行生成项目则是通过`crewai create`命令自动生成项目结构,包括配置文件、目录等,适合快速启动项目,保持结构规范,尤其是团队协作时可能更有优势。
核心区别对比表
| 维度 | 纯代码模式 | 命令行生成项目 |
| 项目结构 | 完全自主定义 | 标准化结构(符合最佳实践) |
| 初始化速度 | 快(直接编写.py文件) | 稍慢(自动生成完整框架) |
| 配置管理 | 代码中硬编码配置 | YAML文件集中管理配置 |
| 维护成本 | 高(需自行管理依赖) | 低(内置依赖管理机制) |
| 扩展性 | 灵活(无约束) | 规范(遵循预设扩展接口) |
| 适用场景 | 快速原型/小型项目 | 生产环境/团队协作/中大型项目 |
| CLI集成 | 需自行实现 | 内置完整CLI工具链 |
| 配置热更新 | 需重启程序 | 支持运行时动态加载 |
选择建议
- 推荐纯代码模式:
- 快速验证想法(PoC)
- 单文件简单任务
- 需要高度定制化流程
- 推荐项目生成模式:
- 需要长期维护的项目
- 多人协作开发
- 需要配置热更新能力
- 计划集成CI/CD流水线
纯代码模式
快速开始
from crewai import Agent, Task, Crew
# 初始化代理
researcher = Agent(
role="市场分析师",
goal="发现新兴科技趋势",
backstory="专长技术分析的资深分析师",
verbose=True
)
writer = Agent(
role="内容创作者",
goal="撰写引人入胜的技术博客",
backstory="擅长技术传播的资深作者",
verbose=True
)
# 定义任务
research_task = Task(
description="分析2023年AI代理领域趋势",
expected_output="包含关键趋势的详细报告(至少5个)",
agent=researcher
)
write_task = Task(
description="基于趋势报告撰写博客文章",
expected_output="1500字的专业博客草稿",
agent=writer
)
# 创建并运行Crew
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
verbose=2
)
result = crew.kickoff()
print(result)
高级配置
使用工具
from crewai_tools import SerperDevTool, WebsiteSearchTool
search_tool = SerperDevTool()
web_rag = WebsiteSearchTool()
researcher = Agent(
role="研究员",
tools=[search_tool, web_rag],
# ...其他参数
)
自定义LLM
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-4-turbo",
temperature=0.7,
openai_api_key="您的API密钥"
)
agent = Agent(
role="分析师",
llm=llm,
# ...其他参数
)
记忆功能
agent = Agent(
role="对话代理",
memory=True, # 启用长期记忆
# ...其他参数
)
执行流程
顺序流程
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process="sequential"
)
并行流程
crew = Crew(
agents=[agent1, agent2],
tasks=[task1, task2],
process="parallel",
max_rpm=10 # 每分钟最大请求数
)
最佳实践
- 明确角色定义:为每个代理设定清晰的职责范围
- 任务分解:将复杂任务拆分为原子化子任务
- 工具选择:根据任务需求选择合适的工具组合
- 流程优化:对依赖任务使用顺序流程,独立任务使用并行
- 输出验证:设置expected_output格式要求
命令行生成项目
项目结构说明
执行 crewai create crew <project_name> 生成的标准项目结构解析:
my_project/
├── .gitignore # Git排除规则文件
├── pyproject.toml # 项目依赖配置文件
├── README.md # 项目说明文档
└── src/
└── my_project/
├── __init__.py # Python包初始化文件
├── main.py # 项目入口文件
├── crew.py # Crew编排主文件
├── tools/
│ ├── custom_tool.py # 自定义工具模板
│ └── __init__.py # 工具包初始化
└── config/
├── agents.yaml # 代理配置文件
└── tasks.yaml # 任务配置文件
配置文件说明
agents.yaml 示例:
research_agent:
role: 技术分析师
goal: 识别新兴技术趋势
backstory: 专注技术领域分析的资深专家
tools:
- web_search_tool
- data_analysis_tool
content_agent:
role: 技术作家
goal: 创作高质量技术文章
backstory: 拥有十年科技媒体经验的资深编辑
tasks.yaml 示例:
trend_analysis: description: 分析人工智能领域最新趋势 expected_output: 包含Top 5趋势的Markdown格式报告 agent: research_agent article_writing: description: 基于趋势报告撰写技术文章 expected_output: 2000字的专业级技术文章 agent: content_agent
自定义工具开发
在 tools/custom_tool.py 中扩展工具类:
from crewai_tools import BaseTool
class DataVisualizer(BaseTool):
name = "数据可视化工具"
description = "将数据分析结果转换为交互式图表"
def _run(self, data: str) -> str:
"""实现可视化逻辑"""
# 示例可视化代码
import matplotlib.pyplot as plt
plt.plot(eval(data))
plt.savefig('output.png')
return "可视化结果已保存至output.png"
配置覆盖机制
支持通过环境变量动态覆盖配置:
# 在crew.py中
from crewai import Crew
from my_project.config import load_config
agents_config = load_config('agents.yaml')
tasks_config = load_config('tasks.yaml')
class TechCrew(Crew):
def __init__(self):
super().__init__(
agents=agents_config,
tasks=tasks_config,
process='sequential'
)
项目运行流程
开发模式:
python -m src.my_project.main –verbose
生产部署:
crewai deploy --project-path ./src/my_project --port 8080
常用CLI命令
| 命令 | 功能描述 |
| crewai create task | 创建新任务模板 |
| crewai list agents | 显示已配置代理列表 |
| crewai validate config | 验证配置文件语法正确性 |
| crewai benchmark | 运行性能基准测试 |
CrewAI实战
项目诉求:使用CrewAI+DeepSeek按照预设的结构生成博客文章。
纯代码模式实现
from crewai import Agent, Task, Crew
from langchain_openai import ChatOpenAI # 修改点1:改用OpenAI兼容接口
# 配置DeepSeek API
llm = ChatOpenAI(
api_key="sk-****",
base_url="https://api.deepseek.com/v1",
model="deepseek/deepseek-reasoner", # 指定API模型名称
temperature=0.5,
max_tokens = 8000
)
# 定义三个智能体
class BlogAgents:
def __init__(self):
self.planner = Agent(
role='内容规划专员',
goal='为博客主题「{topic}」制定结构清晰、逻辑严谨的内容大纲,涵盖核心技术点及关键章节布局,作为后续撰写的基础。',
backstory='''您是一位资深内容策划专员,擅长将技术主题转化为具有教学性与吸引力的内容结构。当前任务是围绕主题「{topic}」制定完整的大纲,包括技术背景、核心知识点、实现流程与实践应用。您提供的框架将直接指导后续撰稿过程。''',
llm=llm,
verbose=True
)
self.writer = Agent(
role='内容创作专员',
goal='基于内容策划专员提供的大纲,为主题「{topic}」撰写一篇结构完整、语言清晰、技术扎实的博客文章,兼具教育性与实用性。',
backstory='''您是一位具备技术背景的内容创作者,擅长将复杂技术讲清讲透。当前需根据策划专员提供的结构,撰写一篇关于「{topic}」的博客文章。内容应逻辑连贯,重点突出,兼顾读者理解与实操性。您应加入合适的示例代码、解释说明、比喻类比等方式,提升内容深度与可读性。''',
llm=llm,
verbose=True
)
self.editor = Agent(
role='内容审核专家',
goal='对撰写初稿进行深入编辑,确保结构清晰、语言流畅、术语准确,并校对所有代码与技术描述的正确性,使其达到可发布标准。',
backstory='''您是一位经验丰富的技术编辑,专注于内容质量审核。当前任务是接收内容创作专员的初稿,并从结构、语言、技术准确性等多个维度进行全方位优化,使文章更具专业性和可读性,确保其符合专业发布标准。''',
llm=llm,
verbose=True
)
# 定义任务流程
class BlogTasks:
def __init__(self, agents):
self.planner_task = Task(
description='''根据用户提供的博客主题,生成一份全面的大纲,需包含:
1. 技术背景与必要前置知识
2. 关键概念与核心原理
3. 实现步骤的逻辑分解
4. 配套代码结构建议
5. 常见问题与误区澄清
6. 实际应用场景或使用示例''',
agent=agents.planner,
expected_output='大纲应层次分明、逻辑清晰,覆盖全面的技术要点,并具备良好的可扩展性。'
)
self.writer_task = Task(
description='''根据策划专员提供的大纲,扩展撰写完整博客内容。内容需包括:
1. 对各章节内容进行技术细化,补充背景与机制解释;
2. 添加代码示例(如有)并提供逐步说明;
3. 使用 mermaid 绘制的图示解释流程或结构(如适用);
4. 结合真实应用场景与行业最佳实践;
5. 使用比喻、对比等表达方式提升内容的趣味性与理解力;
6. 各章节标题应具有吸引力,便于快速定位核心内容。''',
agent=agents.writer,
expected_output='符合Google技术文档标准的Markdown文件',
context=[self.planner_task]
)
self.editor_task = Task(
description='''请对技术博客初稿进行全面编辑,具体包括:
1. 优化整体结构,使逻辑更连贯、章节分明;
2. 检查并纠正所有技术术语、代码细节和引用内容;
3. 修正语言表达错误,提升语言流畅度和专业性;
4. 确保 Markdown 语法正确、代码格式美观。''',
agent=agents.editor,
expected_output='输出一篇内容准确、结构清晰、语言优雅的可发布技术博客。',
context=[self.writer_task]
)
# 运行流程
def generate_blog(topic):
agents = BlogAgents()
tasks = BlogTasks(agents)
crew = Crew(
agents=[agents.planner, agents.writer, agents.editor],
tasks=[tasks.planner_task, tasks.writer_task, tasks.editor_task],
verbose=True
)
return crew.kickoff(inputs={'topic': topic})
if __name__ == "__main__":
blog_topic = "数据结构:链表"
result = generate_blog(blog_topic)
print("\n\n生成结果:")
print(result)
命令行生成项目实现
步骤1:创建项目
crewai create crew my_project # 选择 deepseek 作为provider # 选择不创建.env文件(后续手动添加)
步骤2:调整项目结构
my_project/ ├── .env # 新增 ├── src/ │ └── my_project/ │ ├── __init__.py │ ├── main.py # 修改 │ ├── crew.py # 修改 │ ├── config/ │ │ ├── agents.yaml # 修改 │ │ └── tasks.yaml # 修改 │ └── tools/ └── pyproject.toml
步骤3:修改关键文件
修改 src/my_project/config/agents.yaml
blog_planner:
role: 内容规划专员
goal: 为博客主题「{topic}」制定结构清晰、逻辑严谨的内容大纲
backstory: 资深内容策划专员,擅长将技术主题转化为教学性内容结构
verbose: true
blog_writer:
role: 内容创作专员
goal: 基于大纲撰写结构完整、技术扎实的博客文章
backstory: 技术背景的内容创作者,擅长解释复杂技术
verbose: true
blog_editor:
role: 内容审核专家
goal: 确保文章达到可发布标准
backstory: 经验丰富的技术编辑,专注内容质量审核
verbose: true
修改 src/my_project/config/tasks.yaml
planning_task:
description: 生成包含技术背景、核心原理、实现步骤的详细大纲
agent: blog_planner
expected_output: Markdown格式大纲文档
writing_task:
description: 根据大纲扩展撰写完整博客内容,包含代码示例和图示
agent: blog_writer
expected_output: 符合Google标准的Markdown文件
context:
- planning_task
editing_task:
description: 对初稿进行技术准确性校验和语言优化
agent: blog_editor
expected_output: 可发布的技术博客文档
context:
- writing_task
修改 src/my_project/crew.py
from crewai import Crew
from langchain_openai import ChatOpenAI
import os
def blog_crew(topic):
# 配置DeepSeek
llm = ChatOpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
model="deepseek/deepseek-reasoner",
temperature=0.5,
max_tokens=8000
)
return Crew(
agents=[],
tasks=[],
verbose=True,
config={
'topic': topic,
'llm': llm # 注入自定义LLM配置
}
)
修改 src/my_project/main.py
import argparse
from .crew import blog_crew
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--topic', required=True, help='博客主题')
parser.add_argument('--output', default='blog.md', help='输出文件路径')
args = parser.parse_args()
crew = blog_crew(args.topic)
result = crew.kickoff(inputs={'topic': args.topic})
with open(args.output, 'w', encoding='utf-8') as f:
f.write(result)
print(f"博客生成成功: {args.output}")
if __name__ == "__main__":
main()
步骤4:添加环境配置
创建 .env 文件:
DEEPSEEK_API_KEY=sk-xxxx
步骤5:安装依赖
pip install python-dotenv langchain-openai
使用方式
# 激活虚拟环境 python -m venv .venv source .venv/bin/activate # Linux/Mac .\.venv\Scripts\activate # Windows # 运行项目 python -m my_project.main --topic "Python异步编程" --output async_python.md
关键修改说明
- 配置分离:
- 使用YAML文件定义agents/tasks的基础配置
- 通过py注入自定义LLM配置
- 动态参数传递:
# 在crew.py中
crew.kickoff(inputs={'topic': topic})
- 环境管理:
# 自动加载.env文件 from dotenv import load_dotenv load_dotenv()
- 版本兼容性:
# 在pyproject.toml中确保依赖版本
dependencies = [
"crewai>=0.28",
"langchain-openai>=0.1.0",
"python-dotenv>=1.0"
]
该方案完全遵循最新版CrewAI的项目规范,同时实现了你的自定义需求。如需扩展功能,可以在tools/目录添加自定义工具模块。
项目实战总结
最终通过crewai生成的文章质量还是存在问题:
- 在内容规划层面生成的规划已经比较详细与靠谱
- 在内容生成层面生成的内容受LLM模型最大输出token的限制,限定了内容展开,导致内容点到即止。
后续优化方案,对规划内容进行分段,分段生成内容后再做拼接。
参考链接:


